 運営会社
運営会社
UiPath担当のChewbaccaです。
今回はOCRによるテキストのデータ化の補足として、UiPathのAI Computer Visionを使用してみたいと思います。
AI Computer Visionとは
公式によりますと「人間のような認識力で画面上の要素を見ることができます。」とありまして、UipathのAIモデルを使用して画面の項目を人間が見て認識するかの様に視覚的に画面要素を取得する事ができる機能です。
これにより、動的に変化する要素やhtml要素が少ない画面、またはVDI上での自動化の際にも、「キーボードショート」や「ホットキートリガー」のアクティビティに頼ることなく、画面操作することが可能になるので、とても役立ちそうです。
Computer Visionでは日本語・中国語・韓国語対応のOCR「CjkOCR」が利用可能となりましたので試してみたいと思います。
今回は、OCRによるテキストのデータ化にてうまく読み取れなかった以下の文字を読んでみたい思います。

CV画面スコープの設定
まずはアクティビティより「CV画面スコープ」を配置します。
既に別のOCRエンジンが配置されている場合は、削除して「OCR - 日本語、中国語、韓国語」アクティビティを配置します。
続いてOCRのプロパティにて、APIキーとエンドポイントを設定します。
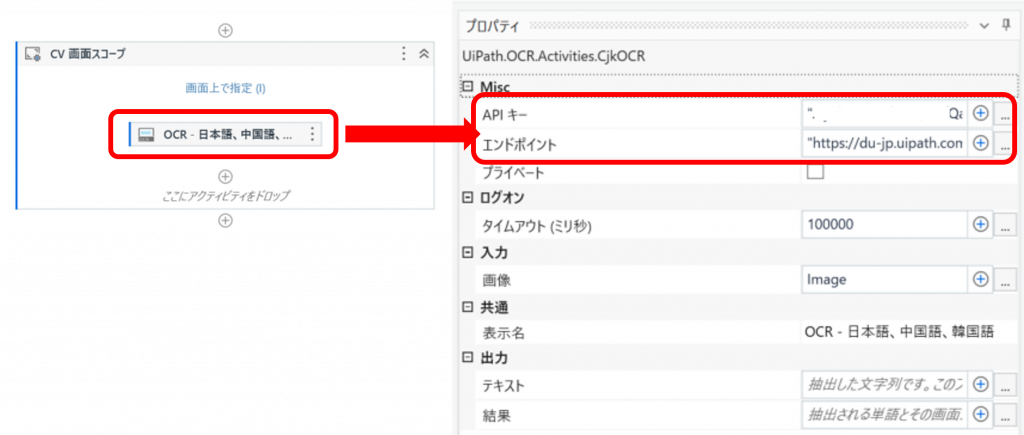
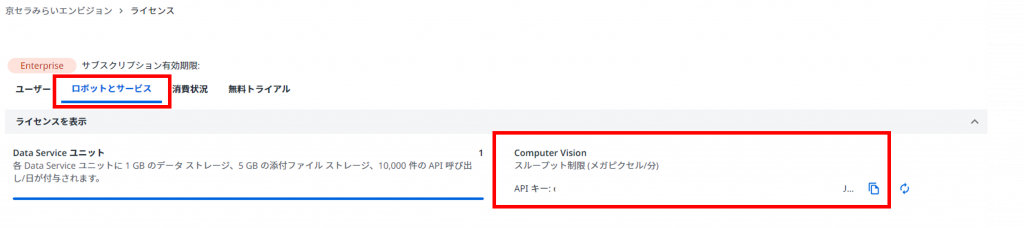
Computer VisionのAPIキーはCloudポータルの「ライセンス」→「ロボットとサービス」より取得します。
エンドポイントには「https://du-jp.uipath.com/cjk-ocr」を設定します。
APIキーとエンドポイントは文字列として認識させる必要がある為、ダブルコーテーションで括る必要があります。
エンドポイントの詳細はこちら。
要素の指定
要素の指定はCV画面スコープの「画面上で指定」した画像に対して選択します。
いきなりですが、読み取り結果です。
<読み取り結果テキスト>

日本語を冠するOCRだけあってきれいに読み取れました!
せっかくなので、こちらでも試してみたいと思います。
以下が、画面上で指定した結果となり、薄青で囲われた箇所がComputer VisionがUI要素と予測した箇所と思われます。
CV画面スコープを使用する際には、UiPathCloudと通信が発生する為、機密情報など使いどころには注意してください。
<画面上で指定した結果>

<読み取り結果>

ところどころの空白が気になりますが、すべて正確に読み取ることができました!
まとめ
文字の読み取りはある程度の精度で認識できるので便利かと思いますが、結局は画像認識の為、htmlタグが使えるならタグで要素を認識させた方が精度と速度の両面とも優れてそうです。
ただ、今後もAIは目まぐるしい速さで発展していくはずですので、注視し続ける必要がある技術と思われます。









