運営会社
運営会社
PythonツールでPDFを取り扱ってみよう
目標
Alteryx2018.3で導入された「Python Tool with Jupyter Notebook」でPythonコードが扱う事ができるようになりました。
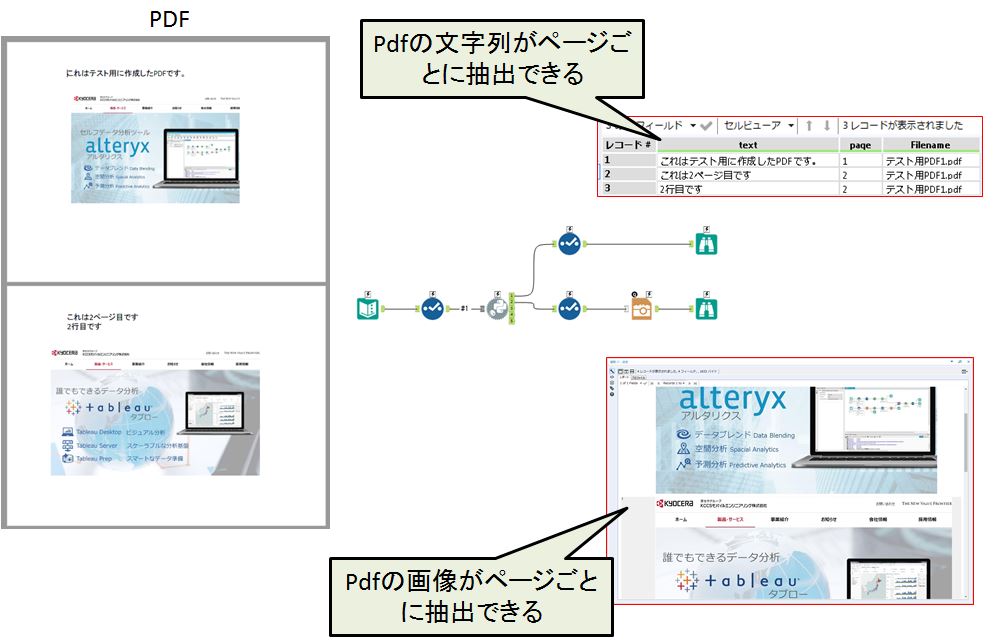
今回はこのツールを使い、PDFの取り込みを行ってみましょう。
PDFの取扱はANALYTICS GALLERYにも「Rツール」を使った方法が公開されていますが、文字列の取り込みのみになってます。
せっかくのPythonでの実装ですので画像も取り込めるようにしてみましょう。
Pythonツールの基礎
Pythonツールですが正式名称からもわかるようにエディタ画面は「Jupyter Notebook」です。基本的な使い方は「Jupyter Notebook」に準拠します。
AlteryxのPython用の専用コマンドは以下があります。
| コマンド | 説明 |
| Alteryx.read( "<input connection name>" ) | Pythonツールに接続されてる入力データを読み取ります。 |
| Alteryx.write( <pandas dataframe>, <output anchor> ) | Pythonツールからのアウトプットを指定する命令です。 |
| Alteryx.installPackages( "<package name or list of package names>" ) | パッケージのインストール用コマンドです。 |
| Alteryx.getIncomingConnectionNames( ) | Pythonツールに接続されてる入力名のリストの取得になります。
例: ['#2', '#1'] などが取得できます。 |
注意Pythonツールの出力に使えるデータはPandasデータフレームになります。
Pythonの初期設定
Pythonの環境ですが今回は以下を使用してます。
| Python | Python3.6 |
| 導入パッケージ | PDFMiner3K(PDFライブラリ) |
| Pillow(画像処理ライブラリ) |
注意PythonのVersionが異なる場合はパッケージが変わります。
ライブラリの導入方法
通常Pythonでのパッケージ導入は「pip install」コマンドを使用しますが、AlteryxのPythonツールでは「Alteryx.installPackages」コマンドを使います。
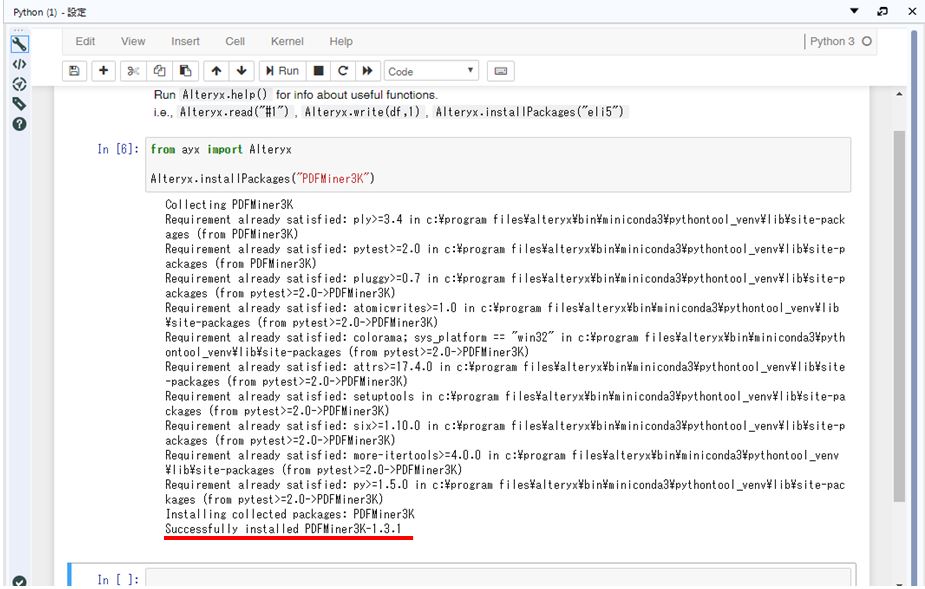
パッケージインストールが成功すると、Successfully となります。
もしAlteryx上でインストールできない場合は、コマンドプロンプトより、Python pip installコマンドでインストールを行います。
一度パッケージの導入を行えば「Alteryx.installPackages」コマンドは不要となります。利用するときは「import」コマンドで利用します。
今回は「PDFMiner3K」「Pillow」の2つをインストールします。
これで一通りの準備が完了しまいした。次回よりPDFの取り込み方法の説明をいたします。
※Alteryx Version 2018.3.5時点での情報です