 運営会社
運営会社
PythonツールでPDFの取り込みを行ってみよう
本記事は、前回の記事の続きとなります。
PDFを取り込む
基本構成を考える
まずは基本構成を考えます。前提となりますがAlteryxではPDFデータの取扱はそのままでは出来ません。
しかしPythonツールをInputツールの代わりに使うことでPDFの読み込みが可能となります。PythonでPDFを取り込む為には、PDFファイルのフルパス情報が必要となります。
PDFはテキストだけではなく画像も含んでいますので、折角なので今回は画像も取り扱いたいと思います。しかしながら、Pythonツール内では画像をPythonツールの出力として扱うことができないので、一度ローカルフォルダに出力し、Alteryxで再度取り込む方法を用います。
PDFをPythonで読み込む
フルパス情報はディレクトリツールなどで得ることが出来ます。
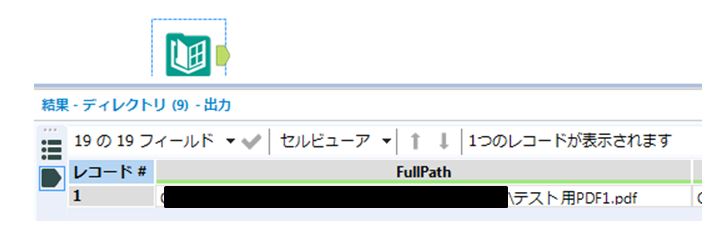
まずは単体のPDF処理を考えてみましょう。本番ではディレクトリツールを使いますが、今回は単体のファイルをテスト的に読み込むだけですので、テキスト入力ツールにフルパス情報を直接記載しました。その上で、Pythonツール上でAlteryx.read命令を実行してみます。
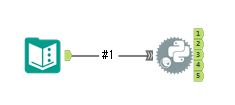

この時点ではエラーとなってしまいます(FileNotFoundError)。
ポイントPythonツールは他のAlteryxツールと接続しただけではメタデータを認識しません。一度ワークフローを実行する必要があります。
ということで、一度ワークフローを実行してみれば成功します(比較のために、エラー画面と成功画面を以下に記載します)。
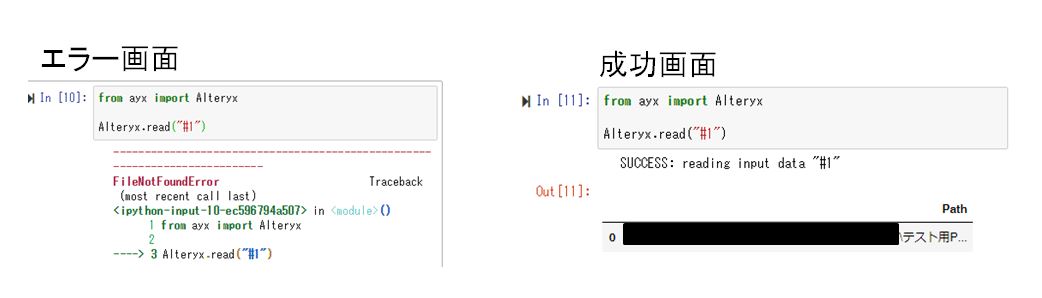
次に、テキスト入力ツールからPythonツールに入力されたフルパスデータを変数(ここでは「filename」)に代入し、一度Printコマンドで表示させてみます。
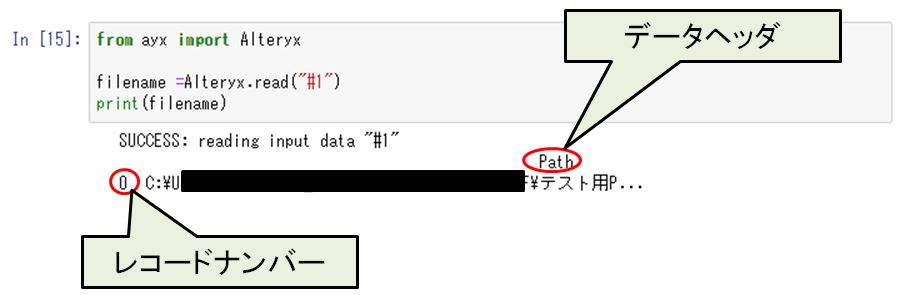
すると、入力されたデータはヘッダとレコードナンバーを持つデータフレームになってることがわかります。
このまま変数に代入するだけでは文字列として扱えませんので、データフレームからデータを取り出します。

.iatで配列指定することで、フルパス情報だけが変数(ここでは「fn」としています)に代入されました。
ここでPythonに詳しい方でしたらお気づきだと思いますが、パス名に「¥」が含まれています。ディレクトリツールなどで読み込んだパス情報は「\」またはバックスラッシュで表記されますが、「\」はPythonではエスケープ文字として認識される為、そのままでは使用出来ません。もっとも簡単な回避方法は「\」を「/」に置換することです。
Pythonツールに入力する前にフォーミュラツールなどで変換を行えば簡単に行えます。
Pythonコード
ここからは実際のPythonコードとなります。Versionによっては使用するパッケージなどが異なることがあるのでご注意ください。
前回導入したパッケージとデフォルトでインストールされている「re」、「pandas」のコマンドを使用しますのでimportに記載します。
from ayx import Alteryx
import re
import pandas as pd
from PIL import Image
from pdfminer.pdfparser import PDFParser,PDFPage,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.converter import PDFPageAggregator,TextConverter
from pdfminer.layout import LTTextBox, LTTextLine, LTImage,LTFigure, LAParams, LTTextBoxHorizontal
次に、画像処理用の関数を作成します。画像の検索はオブジェクトの中のオブジェクトを検索する為に再帰処理を行います。
#画像の保存処理
def get_jpg(ltImage,i,page,OutFD):
folder = OutFD + "/"
filename = folder +str(page)+"_"+ str(i) + "_image.jpg"
pictimage = open(filename,"wb")
pictimage.write(ltImage.stream.get_rawdata())
pictimage.close
return filename
#画像検索の再帰処理
def Regression(layout):
images = []
for obj in layout:
if isinstance(obj, LTTextBox) or isinstance(obj, LTTextLine) or isinstance(obj, LTFigure):
images.extend(Regression(obj))
elif isinstance(obj, LTImage):
images.append(obj)
return images
さらに、PDFの読み込みと初期処理を作成します。Pythonツールの入力の#1にPDFのフルパスを入力し、#2に画像の一時フォルダを入力しているので、それを使うように作っています。
#画像保存フォルダ指定
Output =Alteryx.read("#2")
OutFD= (Output.iat[0,0])
#PDFファイル指定
filename =Alteryx.read("#1")
fn = (filename.iat[0,0])
#PDFファイルOpen
fp = open(fn, 'rb')
#PDF初期処理
parser = PDFParser(fp)
document = PDFDocument()
parser.set_document(document)
password=""
document.set_parser(parser)
document.initialize(password)
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
intepreter = PDFPageInterpreter(rsrcmgr, device)
pages = list(document.get_pages())
次に、PDFをページごとに分割し、テキストと画像を抽出します。
注意今回用いたPdfminer3kの画像処理では「jpg」形式での処理となります。他形式の画像を扱う場合は他のライブラリを用いる必要があります。
#配列初期化
words = []
Jpgfile = []
#PDFページごとに抽出処理
for i,page in enumerate(pages):
intepreter.process_page(page)
layout = device.get_result()
#文字列抽出
for l in layout:
if isinstance(l, LTTextBoxHorizontal):
texts = re.sub(r"\s+", " ", l.get_text())
texts = texts.strip("\n")
texts = texts.split(" ")
texts = [t for t in texts if t != '']
for t in texts:
words.append([t ,str(i+1)])
#画像抽出
contents = []
contents.extend(Regression(layout))
for itImage in contents:
j = 1
Jpgfile.append([get_jpg(itImage,j,i+1,OutFD),str(i+1)])
j= j+1
最後に、抽出したデータをデータフレームに変換し出力を行います。
#データフレームに変換
df = pd.DataFrame(words,columns =["text","page"])
df2 = pd.DataFrame(Jpgfile,columns =["jpeg","page"])
fp.close
#Alteryx出力
Alteryx.write(df,1)
Alteryx.write(df2,2)これで一通りのソースが完成しました。
画像を一時保存するフォルダを指定するようにしましたので、テキストツールを追加して実行してみます。
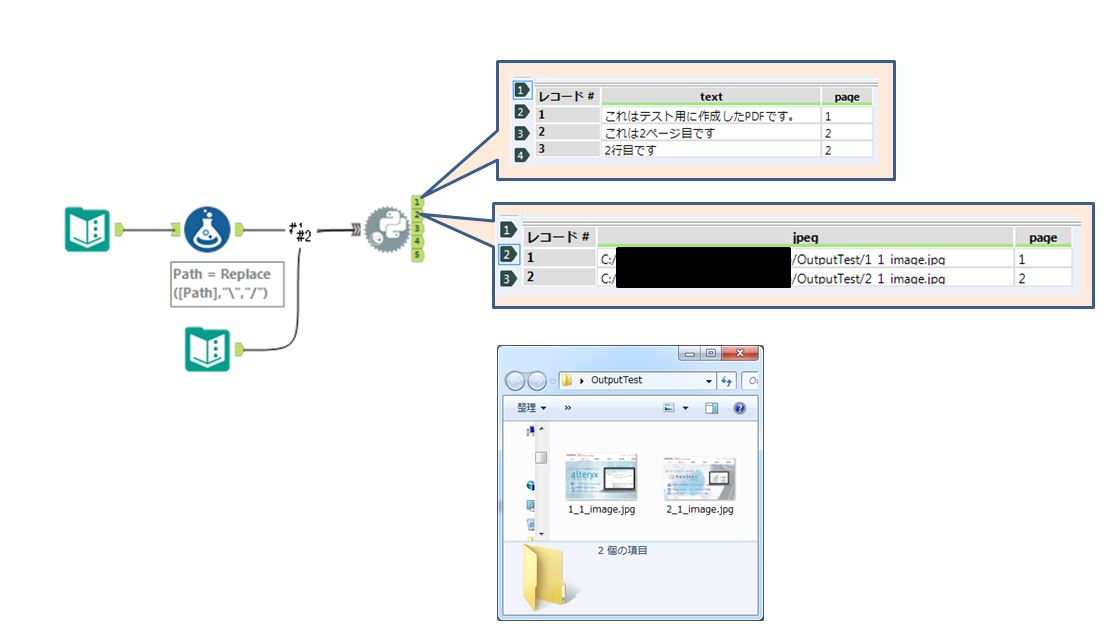
出力「1」からテキストデータが、「2」から画像のフルパス情報が出力されます。
一時保存フォルダには画像ファイルが出力されます。
画像のフルパスを元に画像の取り込みを行ったり、読み込んだTextを利用して後の処理を行うことで任意の処理につなげていきます。
現状の問題点
テキストと画像の取り込みを行うことができましたが、現状で取り込み可能はテキストはPDF作成時に文字として作成されたデータに限ります。スキャナなどで取り込んだ画像の文字を抽出することは、今回の方法では出来ません。
※Alteryx Version 2018.3.5時点での情報です
*Alteryx Version2018.4.5ではPythonツールを日本語ファイル名で保存したり、ファイルのフルパスに日本語が含まれるフォルダに保存すると不具合が発生することが確認されてます。保存する時は半角英数字でお願いいたします。現在改修依頼をしております。









