運営会社
運営会社
Alteryx Pythonツールによる形態素解析の実装
形態素解析とは?
形態素解析とは自然言語処理の一種です。文章を形態素、言葉が意味を持つまとまりの単語の最小単位まで分解し、単語の品詞の種類、活用形などを解析します。
Alteryxでは通常のツールを用いての形態素解析はできません。そこでPythonツールを用いて解析し、その結果を用いてAlteryxで分析する方法を取ります。もしくはAPIを用いてWEBクラウドの言語解析エンジンを用います。代表例としてはGoogle自然言語APIなどです。APIを用いる場合は、件数や用途によっては有料となりますがエンジンや辞書が常に更新されるためより詳しい解析のためにはAPIの利用は有力な選択肢となります。
本ページではPythonは「Janome」を用いた形態素解析を行ってみます。Pythonにはその他「MeCab」など有名なテキストマイニングパッケージが存在します。
Pythonソースコードの生成
まず、PythonツールにPythonパッケージのインストールを行います。
Alteryx.installPackages("Janome")今回のPythonソースです。
from ayx import Alteryx
from janome.tokenizer import Tokenizer
import pandas as pd
text = Tokenizer()
#Alteryxデータストリーム読込処理
df =Alteryx.read("#1")
#出力用の空配列作成します。
OutPutText = []
i = 0
#ここでのTextはAlteryxデータストリームのフィールド名です。解析するフィールドを指定します。
dftext = df.loc[:,"Text"]
for a in dftext:
txt = str(a)
#Textフィールドの文章を、形態素に分解します。どの形態素が同じ文章なのかわかるようにNoとして変数iを用いています
text_c = text.tokenize(txt)
for j in text_c:
t =str(j)
OutPutText.append([i,t])
i += 1
#配列を出力できるようにpdデータストリームに変換します。
Outdf = pd.DataFrame(OutPutText,columns =["No","Text"])
#Alteryx出力処理
Alteryx.write(Outdf,1)これでPythonソースは完成です。
Alteryxワークフローで実施しよう
作成したPythonツールをAlteryxで動かします。今回の入力は単純にテキスト入力ツールを用いて行っています。
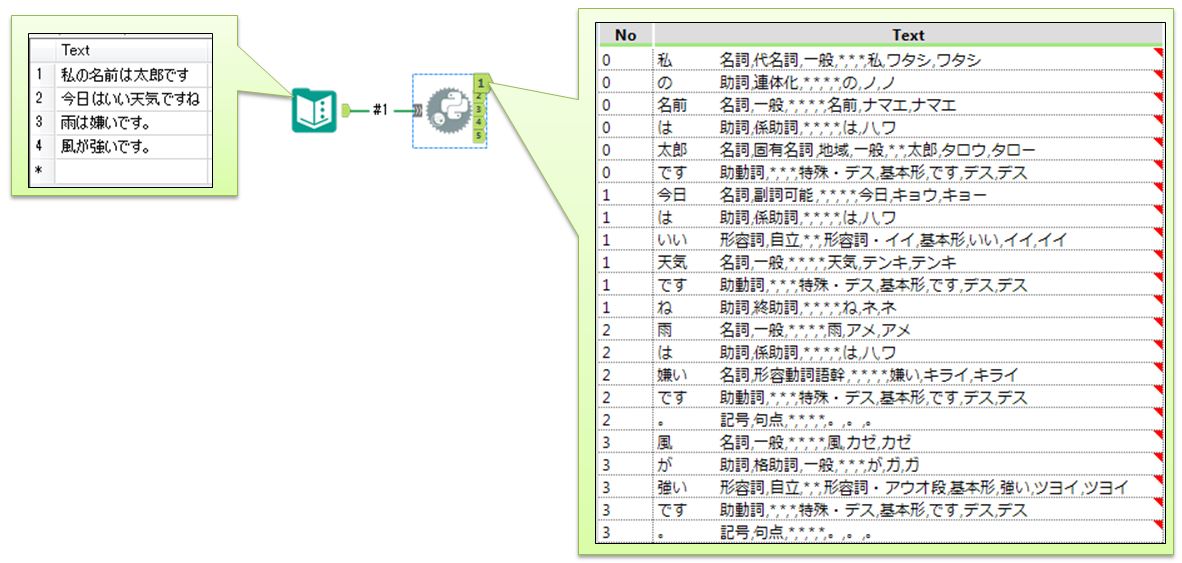
形態素解析の結果はテキストの塊です。これをPythonで分解するのは一苦労です。ですが、ここから先の処理はAlteryxで行えば簡単です。
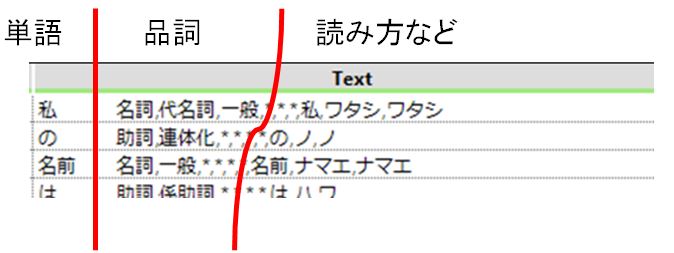
まずは出力されたデータを確認します。「単語」空白(Tab)「品詞」*,*,*,「読み方など」で出力されてます。まずは空白を利用してテキストパースしてみましょう。
分割する列は「Text」区切り文字は「\t」(Tabによる空白)にします。分割する列数は「2」です。
注意PythonツールにAlteryxツールをつなぐとフィールドを認識しない場合があります。その時は一度ワークフローを実行してください。マクロなどを使用した場合でも起こる現象ですが、出力されるフィールドが不明となるため、実行しないと認識出来ないことがあります。
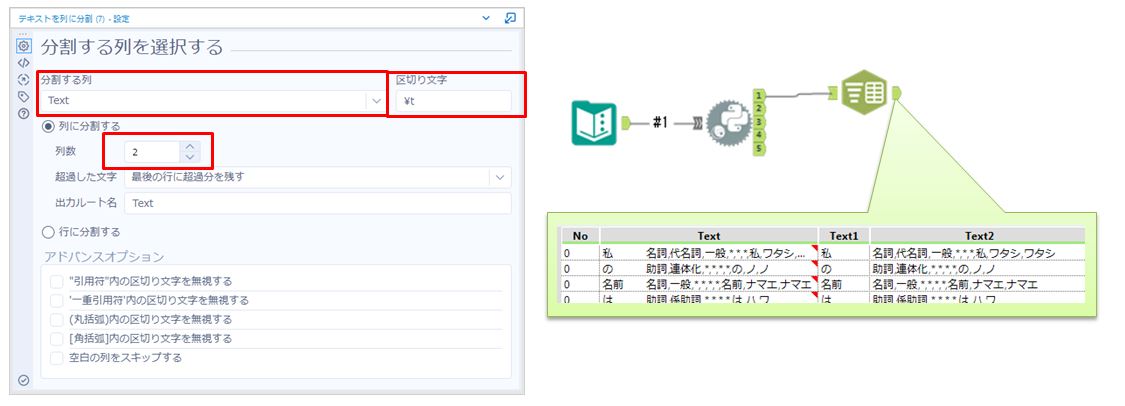
次に品詞と読み方を分割してみます。確認すると区切り文字が「,*」であることは分かりますが数が4つだったり5つだったりしています。このようなケースの場合は「正規表現」ツールなどがおすすめです。
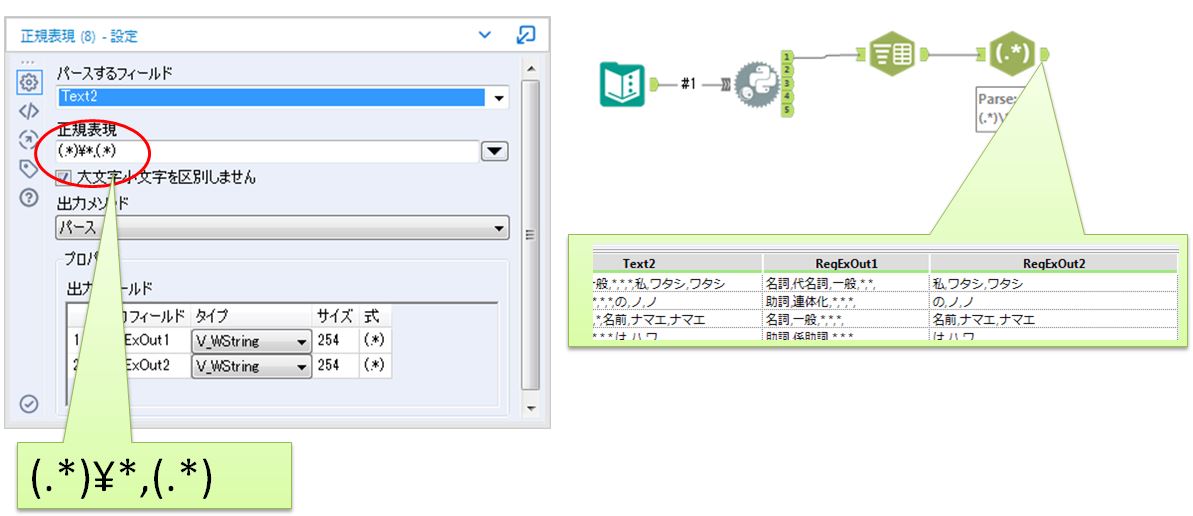
正規表現ツールの使い方は下記ページを参照ください。

これで「品詞」と「読み方など」に分割できました。この状態だと品詞の部分に不要な「*,」が残ります。「フォーミュラ」ツールでReplace関数を使って修正します。
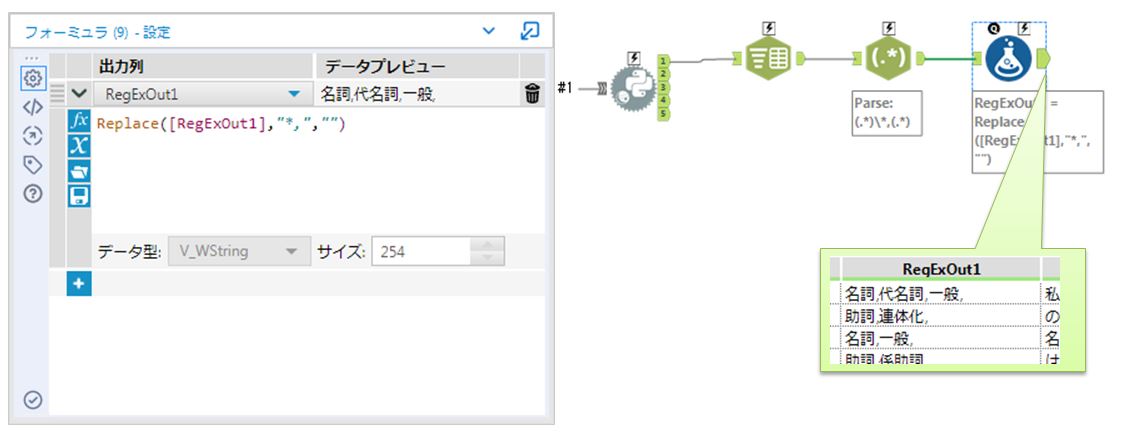
最後に「選択」ツールで形を整えます。
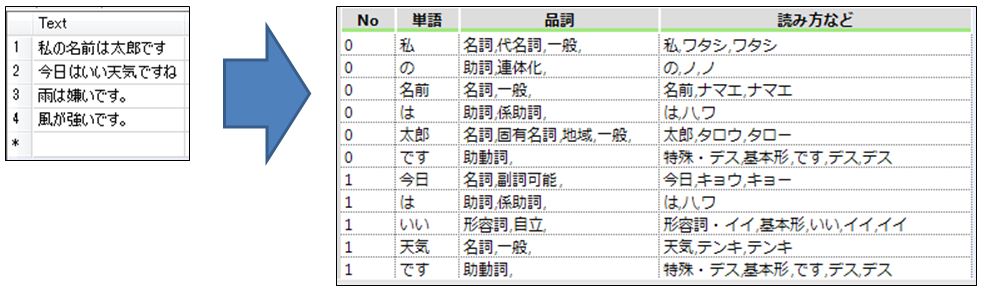
これでテキストの形態素解析ができました。
いかがでしたでしょうか?Pythonなどのプログラムだけで、全部作成するのは一苦労ですが、一部機能だけをPythonツールで利用し、その結果をAlteryxで編集すると、比較的に簡単に目的の機能を実装できます。
※Alteryx Version 2018.4.5時点での情報です
*Alteryx Version2018.4.5ではPythonツールを日本語ファイル名で保存したり、ファイルのフルパスに日本語が含まれるフォルダに保存すると不具合が発生することが確認されてます。保存する時は半角英数字でお願いいたします。現在改修依頼をしております。