運営会社
運営会社
PDFから特定部分の文章を抽出する
以前の記事でAlteryxでPDFを取り込む方法を紹介したことがありましたが、今回は応用してみて、任意の位置の文字列を抜き出す方法を考えたいと思います。
例えば次のような見積書があったとします。

この見積書から見積金額に関する箇所を抜粋し、Alteryxでテーブルしてみます。
まず前回公開した【Alteryx Tips】AlteryxのPythonツールでPDFの取り込みを行ってみよう【プログラムコードの作成編】
を其のまま用いて文字列を取り込んでみます。
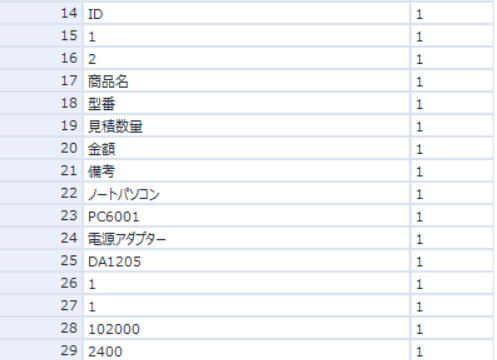
実行すると文字は取り込めていますが、これでは表にするのは難しいのが分かります。
そこで、どうやって取り込むかを考察していきましょう。
1.表にするにはどうすれば良いかを考察する
まず、表にする部分を見ていきましょう。

これに対して取り込まれたデータを見てみると
取り込順も規則性が良く分からないですね。これを表にするには何の情報があれば行けるか考えてみます。
まず、文字の区切りは問題なさそうです。次に表の項目になる「ID、商品名、型番、見積数量、金額、備考」と値をどの様に対応させるか考えます。
まず並び替えを考えてみますが、これは厳しいと判断せざるを得ません。現状では何を基準に並び替えるかが分からないからです。これではTool化は出来ません。
そこで、基準となるものを取得できないかを考えます。
2.文字列の座標を取得する
PythonのPDFMinerでは、PDFからTextBoxの座標を取得することができます。これを用いてTextBoxごとに文字列と座標を取得すれば、座標を元に並び替えを行う事が出来ます。
Pythonコードを次の様にします。
from ayx import Alteryx
import re
import pandas as pd
from PIL import Image
from pdfminer.pdfparser import PDFParser,PDFPage,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.converter import PDFPageAggregator,TextConverter
from pdfminer.layout import LTTextBox, LTTextLine, LTImage,LTFigure, LAParams, LTTextBoxHorizontal,LTContainer
def find_textboxes(layout_obj):
# LTTextBoxを継承する場合、1要素を返す
if isinstance(layout_obj, LTTextBox):
return [layout_obj]
# 再帰的に探す。
if isinstance(layout_obj, LTContainer):
boxes = []
for child in layout_obj:
boxes.extend(find_textboxes(child))
return boxes
# その他
return []
#ファイル名読み込み
filename=Alteryx.read("#1")
fn = (filename.iat[0,0])
fp = open(fn, 'rb')
#PDF初期処理
parser = PDFParser(fp)
document = PDFDocument()
parser.set_document(document)
password=""
document.set_parser(parser)
document.initialize(password)
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
intepreter = PDFPageInterpreter(rsrcmgr, device)
pages = list(document.get_pages())
#配列初期化
words = []
Jpgfile = []
#PDFページごとに抽出処理
for i,page in enumerate(pages):
intepreter.process_page(page)
layout = device.get_result()
#TextBox抽出
boxes = find_textboxes(layout)
for box in boxes:
#X座標、Y座標、テキスト
words.append([box.x0, box.y1, box.get_text().strip()])
df = pd.DataFrame(words,columns =["X","Y","Text"])
Alteryx.write(df,1)
このコードを実行した場合次の結果が得られます。
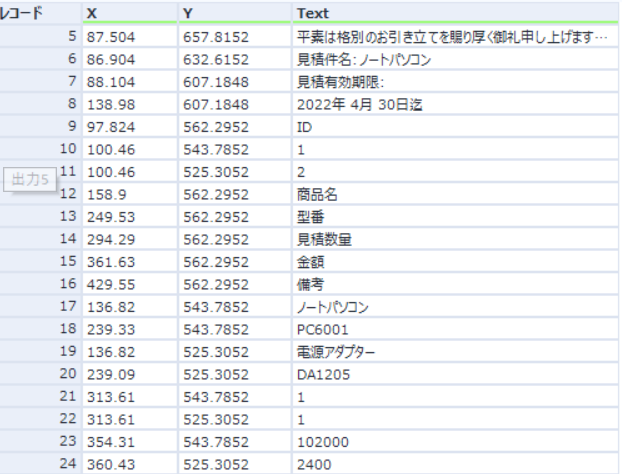
テキストと座標が抽出されているのが分かります。ではこの座標を元にどの様に並び替えるかを考察します。
3.取得したデータから、データ範囲を特定する
取得したい部分に座標を書き込んでいきます。

これを見ると座標は左下起点と分かります。また、Y座標は横で見るときそろってますが、X座標はIDの項目をみると、項目と値でずれがあることが分かります。ですが、IDから金額までは、必ず埋まってる事で仮定するとX座標で並び変えれば行けそうです。*もし全て項目に文字列が入力してない場合は、一番近いX軸座標に紐づけるなどします。この方法は今回は説明を省かせていただきます。
まず、抜き出す文字列のY座標を決めます。まず項目行のY座標は文字列が「ID」の場所で問題なさそうです。次に値の最終行を求めるにはどうするかを考えます。
今回は2品ですが、3品、4品の事もあります。また、商品名などで決めていては汎用性に欠けます。ここでもう一度見積書を見てみます。そうすると下部に注釈がついてる事が分かります。

これを基準としてY座標を決めてしまいます。つまり抽出した文字列のうち「ID」を含むもののY座標以下で「この見積書に表示されている」を含むY座標より上は表の項目か値になると判断できます。そのうちでIDのY座標と同じ文字列は項目だと分かります。ではここまでをAlteryxでWFにします。
4.取得データから表を作成する
それぞれ取得した値を抜粋するとこの様なデータが取得できます。項目名はIDと同Y座標を取得し、X座標順に並び替えRecordIDをふります。値は上記で説明したY座標の範囲から文字列を抽出します。
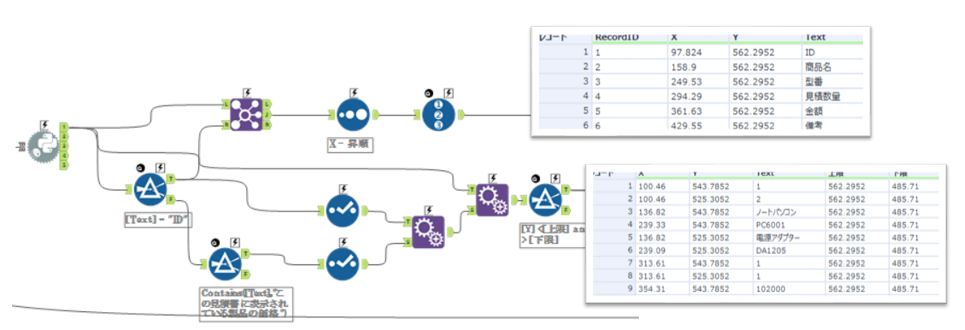
次に値の部分をY座標で番号を振り、同じ行のグループを作ります。
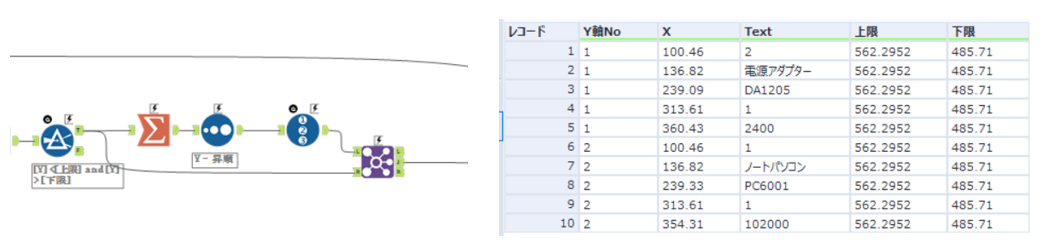
値部分をグループX座標順に並び替え、Yグループごとに番号をふります。クロスタブで縦横を変換し、カラム名を前記で抽出した項目名に置き換えます。これで表部分の抽出が可能になりました。
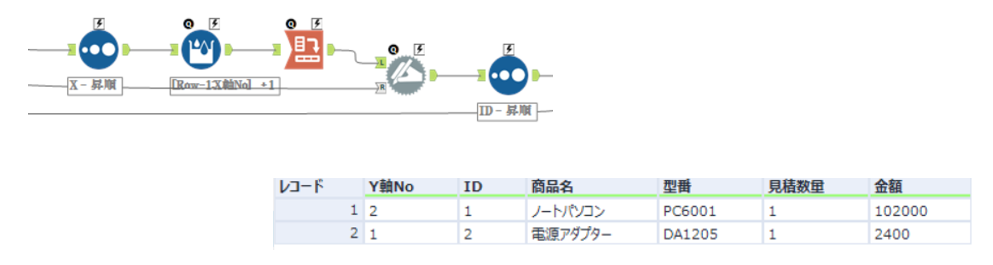
ただ、この時点では備考など値がNull値の場合が出力されてません。もう一工夫するとNull値の場合も処理ができます。添付しているWFはその部分も考慮したつくりにしてますので是非中を確認して、どの様に処理してるか考えてみてください。
今回紹介した方法はY軸の上限と下限の指定ができるマクロとして添付しますので、是非確認して見てください。
いかがでしたでしょう、一見難しいそうに見える事でも、最終的にしたいことから、そこにたどり着くまでに何が必要で、それを得るためにはどうすればいいかを、一つ一つ考えれば、思っていたより簡単にできてしまうのが分かったと思います。
※Alteryx Designer v2021.3.3.63061時点の情報です
サンプルワークフロー
注意事項
- 本マクロに関する不具合、および利用したことによる損害については一切の責任を負いません
- 不具合報告、ご要望などあるようでしたら弊社フォームにて投稿頂ければ、本マクロの改良、機能追加など検討させて頂きますが、弊社都合にて行いますので要望の反映などのお約束はできませんのでご了承ください
- 有償でのカスタマイズ要望などあるようでしたら、弊社フォームにてお申し込みください。別途お見積りさせて頂きます