 運営会社
運営会社
【Snowflake】マルチクラスターウェアハウスによるデータ処理の可用性を高める方法
おはようございます。MJです。
今回はSnowflakeのマルチクラスターウェアハウスについて概要と設定方法の説明をし、実際にマルチクラスターウェアハウスを利用して処理の結果をご説明します。
マルチクラスターウェアハウスとは?
マルチクラスターウェアハウスを説明する前にまずクラスターが何か説明する必要があります。
クラスターとはSnowflakeの中でクエリを処理する仮想ウェアハウスを意味します。
Snowflakeの仮想ウェアハウスは基本的に単一クラスターで構成されますが、複数のクラスターを使って、データを分散処理する機能を“マルチクラスターウェアハウス「MULTI CLUSTER WAREHOUSE」”と呼びます。
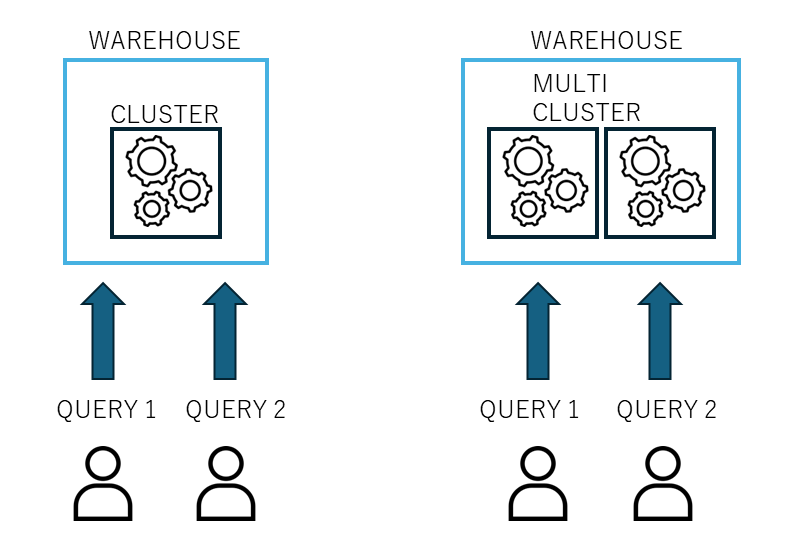
マルチクラスターウェアハウスの長所としてはデータの量が増えたり、処理の量が増えたりした時、自動でクラスターを追加してデータ処理タスクを複数のクラスターに分散させることで、処理能力を向上させることができます。
また、処理の量が減った時、クラスターの数を減らしてコストを節約できます。
それでは、Snowflakeでマルチクラスターウェアハウスを設定する方法についてご紹介します。
マルチクラスターウェアハウス設定方法
マルチクラスターウェアハウスの設定は「Admin」→「Warehouse」ページで新しいウェアハウスを作成する時、既存のウェアハウスの「Edit」画面で設定を変更する時に行います。
新しいウェアハウスを作成する時は「Warehouse」ページの右上にある青色の「+Warehouse」ボタンをクリックし、マルチクラスターウェアハウスのチェックボックスを有効化します。
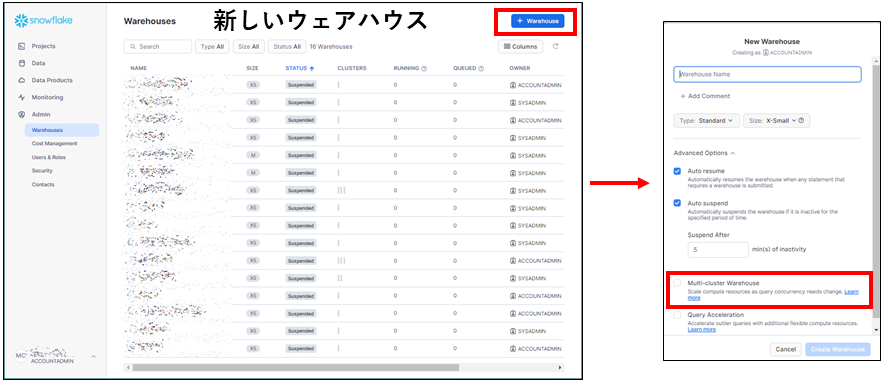
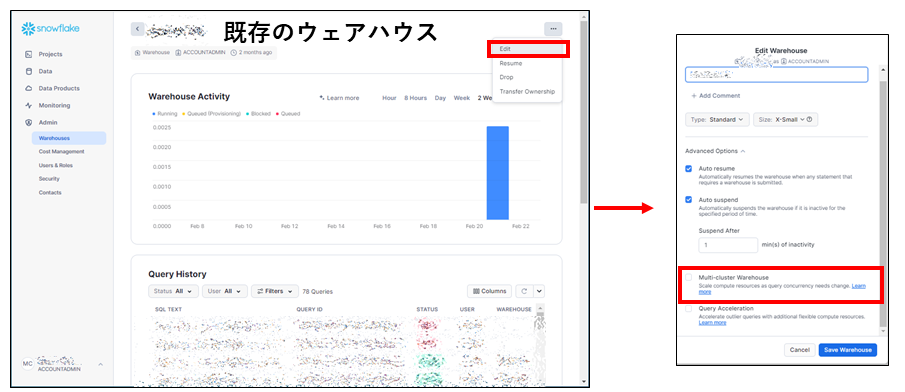
既存のウェアハウスの場合は該当のウェアハウスのページに移動し、右上の「Edit」ボタンをクリックし、マルチクラスターウェアハウスのチェックボックスを有効化します。
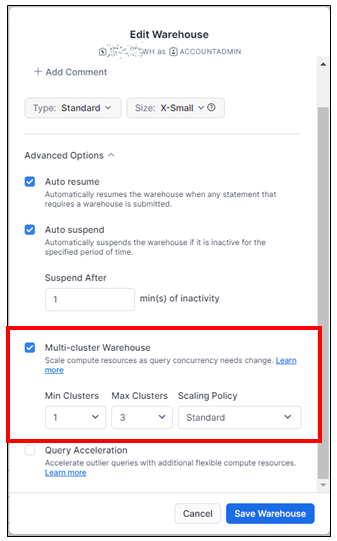
マルチクラスターウェアハウスのオプション設定は3つあります。
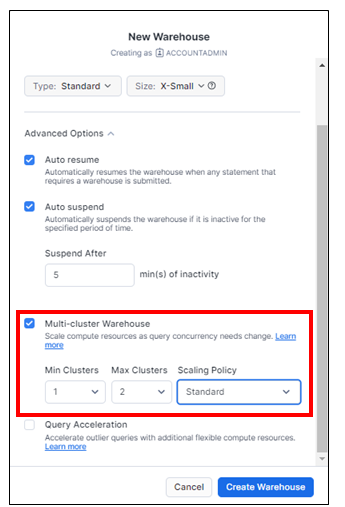
- Min Clusters:クラスターの最小数を指定
- Max Clusters:クラスターの最大数を指定
- Scaling Policy:自動でクラスターの数を制御するモード
- Standard:クレジット(費用)を節約するよりも、追加のクラスターを開始することが優先されます。
- Economy:追加のクラスターを開始するよりも、実行中のクラスターを完全にロードされた状態に保つことが優先され、クレジットが節約されます。
上記の設定が完了できたら、下にある青色の「Create Warehouse」をクリックします。
マルチクラスターウェアハウスの結果
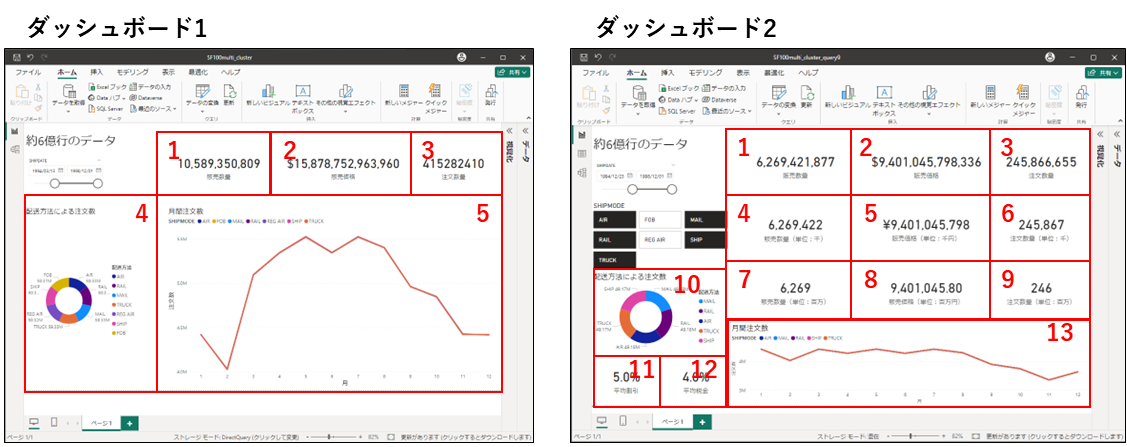
それでは実際にマルチクラスターウェアハウスがどうやって動くのか確認するために、Power BIで約6億行のデータを読み込んでテストをやってみます。
用意したダッシュボードは、約6億行のデータをDirectQuery方式でSnowflakeにクエリを投げ、リアルタイムで値を読み込めるようにしました。
DirectQueryについてはこの記事をご参考にしてください。
【PowerBITips】Snowflakeの接続方法「Import、DirectQuery」とは?
左は負荷がない時を想定してビジュアルを5個使って作ったダッシュボードで、右は負荷をかけるためにビジュアル13個使って作ったダッシュボードとなります。
そして、テストで使うウェアハウスは最小1つ、最大3つのクラスターを動的に使うマルチクラスターウェアハウスとなります。
それでは、左のダッシュボードの期間スライサーを触ってウェアハウスを動かしてみましょう。
そうすると、5個のビジュアルに表現するために5つのクエリが発生し、処理していることが確認できます。しかし、1つのクラスターだけで処理できるため、クラスターの数は変動がありませんでした。

次に負荷を強制的にかけるために、用意した2つのダッシュボードの期間スライサーを触ってウェアハウスを動かしてみます。
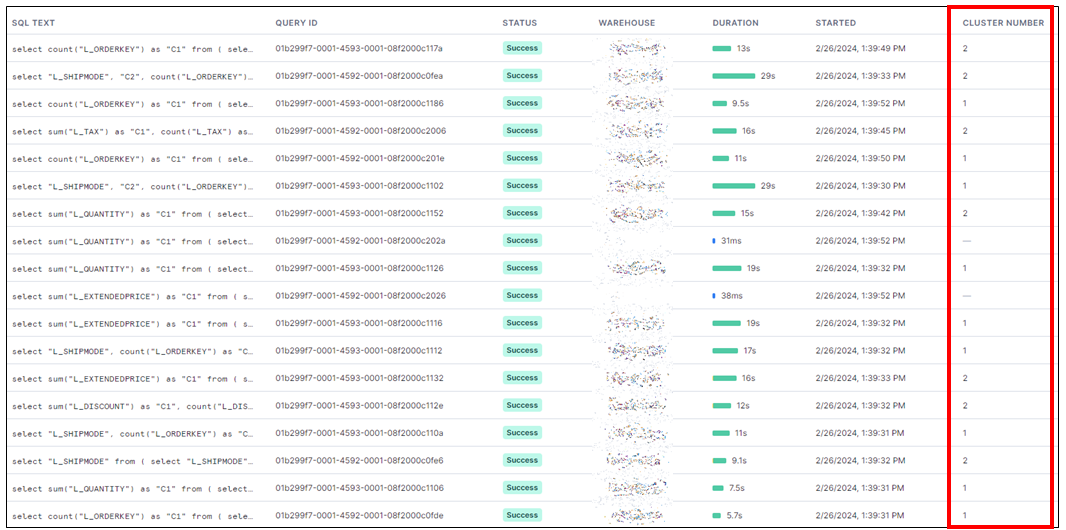
そうすると、1つのクラスターで実行できるクエリ数より多くのクエリを検出され、2つのクラスターを動かしていることが確認できます。

Query Historyページの詳細結果をみると、クラスター2つが並行で分散処理してた結果が確認できます。
まとめ
このようにデータを並列に処理するマルチクラスターウェアハウス機能を設定して、皆さんもデータを効率的に処理し、安定的なウェアハウスを作ってみてください!
※マルチクラスターウェアハウスはSnowflake Enterprise Edition(またはそれ以上)のバージョンで使えるサービスです。










