 運営会社
運営会社
UiPath担当のChewbaccaです。
今回はオートメーション化を考える上では外せない、UiPathのOCR機能をご紹介します。
はじめに
RPAとOCRの組み合わせにより業務の自動化や効率化に大きな相乗効果を期待することができます。
例えば、OCRにて画像から文字データを読み取り、そのままRPAにてデータ処理する様な事が可能となります。
今回はUiPathのOCR機能を使用して画像からテキストを読み込み、データ化してみたいと思います。
OCRとは
OCRとは、Optical Character Recognition/Readerの略で訳すと光学文字認識となります。
画像やPDF、その他のスキャンした文書からテキストを認識し、抽出することが可能です。
スキャンが画像としてデータ化するだけなのに対し、OCRは画像のテキストをデータ化する事ができるため、システム上での利用が可能となります。
また、汎用性が高い為、様々な業務の効率化に適しています、一般的な効率化例をいくつかご紹介します。
<請求書処理>
請求書から請求書番号、日付、金額などの関連情報を抽出し、請求書処理の効率化が可能に
<文書のデジタル化>
紙ベースの文書を検索・編集可能なデジタル形式に変換し、保管、検索、分析が容易に
<データ抽出>
フォーム、アンケート、レポートからデータを抽出し、手作業なしでデータベース、CRMシステム、その他のアプリケーションへの入力が可能に
使用方法
では、実際にUiPathの「UiPath.Core.Activities」パッケージに含まれているTesseract を使用してテキストを読み込んでみたいと思います。
(Tesseract (テッセラクト)とは四次元超立方体との意味だそうです)
今回は以下の画像を読み込んでみたいと思います。

アクティビティの設定は例によって簡単です。
「画像を読み込み」「Tesseract OCR」「テキストをファイルに書き込み」アクティビティを以下の様に配置し、プロパティを設定します。
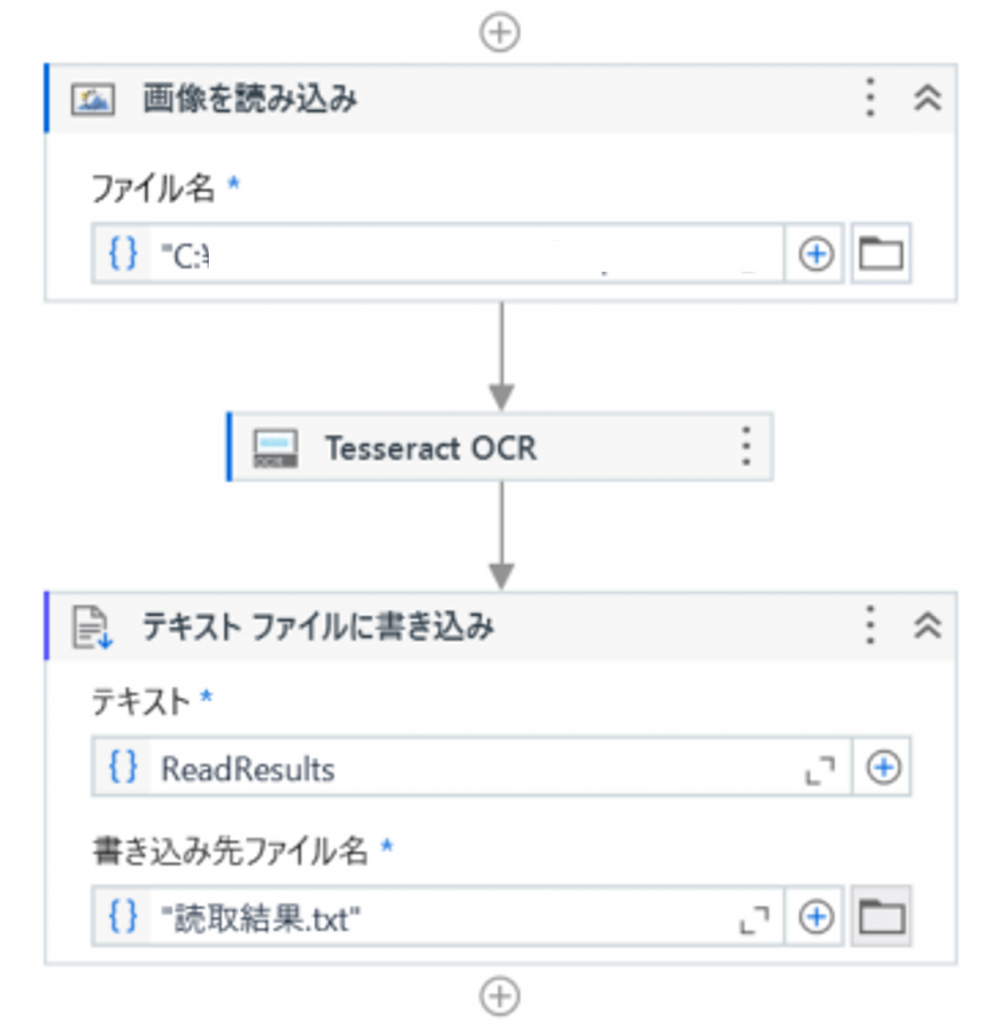
「画像を読み込み」アクティビティではファイル名に読みとる画像のパス
画像に読み取り結果を格納する変数名を設定します
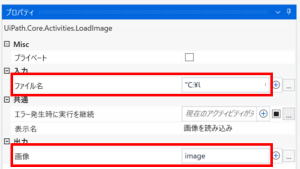
続いて、「Tesseract OCR」の設定です
今回は読み取る対象が日本語ですので「言語」に"jpn"を指定します
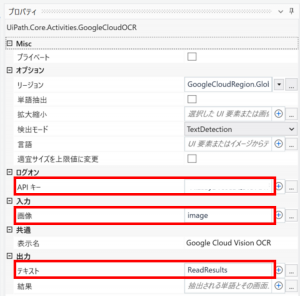
「画像」にはOCRで読み取りたい画像を指定する必要があるため、 「画像を読み込み」アクティビティの画像に設定した変数を指定します。(今回はimage)
「テキスト」にはOCRで読み込んだ結果を格納する変数を設定します。(今回はReadResults
サポート言語の確認やデータの追加も可能ですので詳しくは公式のこちらをご参照ください。
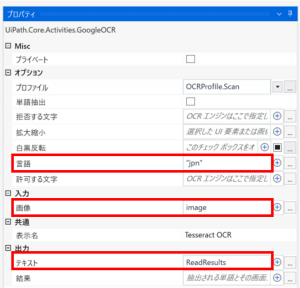
また、OCRの読み取り精度を向上させるため、任意の前処理プロファイルを選択する事が可能です、プロファイルの上にカーソルを乗せれば、選択可能な項目と用途が表示されます。
今回は「Scan」を選択してみたいと思います。
Profileの選択次第で読み取り精度が上がる可能性もありそうなので色々試して頂くのもおすすめです。
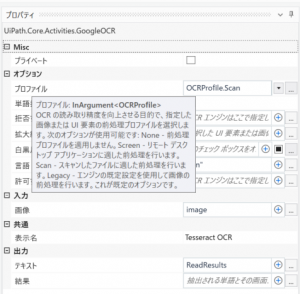
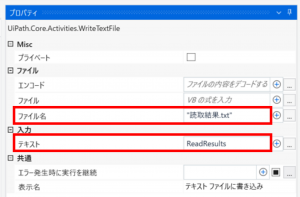
最後にOCRエンジンにて読み取った結果をテキスト出力する為に、「テキストをファイルに書き込み」のプロパティを設定します。
ファイル名には出力ファイルのパス、テキストにはOCRでの読み取り結果(今回はReadResults)を設定します。
実行結果
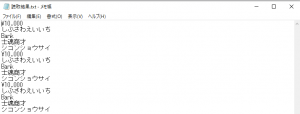
この様な結果となりました。
<読み取り元画像>
<読み取り結果テキスト>

1が①になっていたり、カンマがピリオドになっていたりで、カタカナは読めていないのですが、\や漢字、ひらがながはきれいに読めている、意外な結果となりました。
せっかくなので、GoolgeCloudVision OCRも試してみようと思います。
<GoolgeCloudVision読み取り結果テキスト>
すべてのテキストを正確に読み込むことができました!
アクティビティの設定は「Tesseract OCR」とほぼ変わりませんが、別途APIキーを用意する必要があるので要注意です。
まとめ
OCRとUiPathの組み合わせにより、目視で作業せざるを得なかったデータ入力作業などを自動化できる様になり、人間がより付加価値の高い業務に注力する事ができる様になります。
また、UiPathにはAIドキュメント処理製品であるDocument Understandingも用意されており、AI-OCRについては、今後もより進歩が期待される領域かと思われます。
これらの活用により更なる効率化への道筋が拓けるかと思いますのでぜひ検討していただけたらと思います。














