 運営会社
運営会社![【Alteryx関数シリーズ】文字列関数の使い方[2025Ver.対応]](https://newssdx.kcme.jp/wp-content/uploads/2020/07/Alteryx関数キャッチ用.png)
Alteryxで使用できる関数の「文字列関数」の使い方をご紹介します
文字列関数は、文字列型のデータに対して、加工や検索を行う関数です。
本記事はAlteryx Designer Version 2025.1.2.の内容になりますので、Alteryx Designer Version 2019.1.6の場合は以下のリンクを参考にしてください。
以下の関数は、Alteryx Designer Version 2019.1.6以降にAlteryxに追加された関数です。
- GetLeft (Version2023.2で追加)
- GetPartv (Version2023.2で追加)
- GetRight (Version2023.2で追加)
-
FindNth (Version2024.1で追加)
※本関数のリリース日は、公式ドキュメント上では明記されていません。
-
MD5_ASCII
-
MD5_UNICODE
-
MD5_UTF8
フォーミュラツールの文字列関数の一覧
| カテゴリ | 関数名 | 概要 | 対応するExcel関数 |
|---|---|---|---|
| 判断 | Contains(String, Target) | 指定した文字列が含まれているかチェックします | - |
| 取得 | CountWords(string) | 文字列の単語数を取得します | - |
| 判断 | EndsWith(String, Target) | 文字列が指定した文字列で終わるかチェックします | - |
| 判断 | StartsWith(String, Target) | 文字列が指定した文字列で始まるかチェックします | - |
| 取得 | FindString(String, Target) | 文字列内の指定した文字列を取得します | Search/Find(String, Target) |
| 取得 | GetWord(string, n) | 文字列内の指定した単語を取得します | - |
| 取得 | Left(String, len) | 文字列の左から指定した文字数の文字列を取得します | LEFT(String, len) |
| 取得 | Right(String, len) | 文字列の右から指定した文字数の文字列を取得します | RIGHT(String, len) |
| 取得 | Length(String) | 文字列の文字数を取得します | LEN(String) |
| 変換 | LowerCase(String) | 大文字を小文字に変換します | LOWER(String) |
| 変換 | UpperCase(String) | 小文字を大文字に変換します | UPPER(String) |
| 変換 | TitleCase(String) | 最初の文字は大文字、他の文字はすべて小文字に変換します | PROPER(String) |
| 取得 | PadLeft(String, len, char) | 指定された文字列を左に埋め込みます | - |
| 取得 | PadRight(String, len, char) | 指定された文字列を右に埋め込みます | - |
| 取得 | REGEX_CountMatches(String, pattern) | 文字列内で、指定したパターンと一致した単語の数を取得します | - |
| 判断 | REGEX_Match(String, pattern) | 文字列が指定したパターンと一致するかチェックします | - |
| 変換 | REGEX_Replace(String, pattern, replace) | 文字列の中で、指定したパターンと一致する部分を置き換えます | - |
| 変換 | Replace(String, Target, Replacement) | 指定した文字列を置き換えます | SUBSTITUTE(String, Target, Replacement) |
| 変換 | ReplaceChar(String, y, z) | 指定した文字を置き換えます | SUBSTITUTE(String, y, z) |
| 変換 | ReplaceFirst(String, Target, Replacement) | 文字列の最初の指定した文字列を置き換えます | - |
| 変換 | ReverseString(String) | 文字列を反転します | - |
| 取得 | STRCSPN(String,y) | 指定した文字列にない文字で構成される文字列の、最初のセグメントの長さを取得します | - |
| 取得 | STRSPN(String,y) | 指定した文字列にある文字で構成される文字列の、最初のセグメントの長さを取得します | - |
| 取得 | Substring(String,start,length) | 指定される長さと開始位置で文字列を取得します | MID(String,start,length) |
| 変換 | StripQuotes(String) | 文字列の引用符を削除します | - |
| 変換 | Trim(String,y) | 指定した文字を文字列から削除します | - |
| 変換 | TrimLeft(String,y) | 指定した文字を文字列の先頭から削除します | - |
| 変換 | TrimRight(String,y) | 指定した文字を文字列の末尾から削除します | - |
| 取得 | UuidCreate() | ユニークな識別子を作成します | - |
| 取得 | FindNth(Initial String, Target, Instance) | 指定した文字が何番目に出現するかを返します | FIND(String, Target, ) |
| 取得 | GetLeft(String, Delimiter) | 区切り文字の最初の出現位置より左側の文字列を取得します | LEFT(String) |
| 取得 | GetRight(String, Delimiter) | 区切り文字の最初の出現位置より右側の文字列を取得します | RIGHT(String) |
| 取得 | GetPart(String, Delimiter, Index) | 区切り文字で分割した文字列の指定位置を返します | INDEX(array, row_num) |
| 変換 | MD5_ASCII | 文字列の MD5 ハッシュを計算します | - |
| 計算 | MD5_UNICODE | UTF-16 文字列の MD5 ハッシュを計算します | - |
| 計算 | MD5_UTF8 | UTF-8 文字列の MD5 ハッシュを計算します | - |
以下の関数が、本バージョンより新たにAlteryxに追加された関数です。
-
FindNth
-
GetLeft
-
GetPart
-
GetRight
-
MD5_ASCII
-
MD5_UNICODE
-
MD5_UTF8
各関数の使い方とサンプル
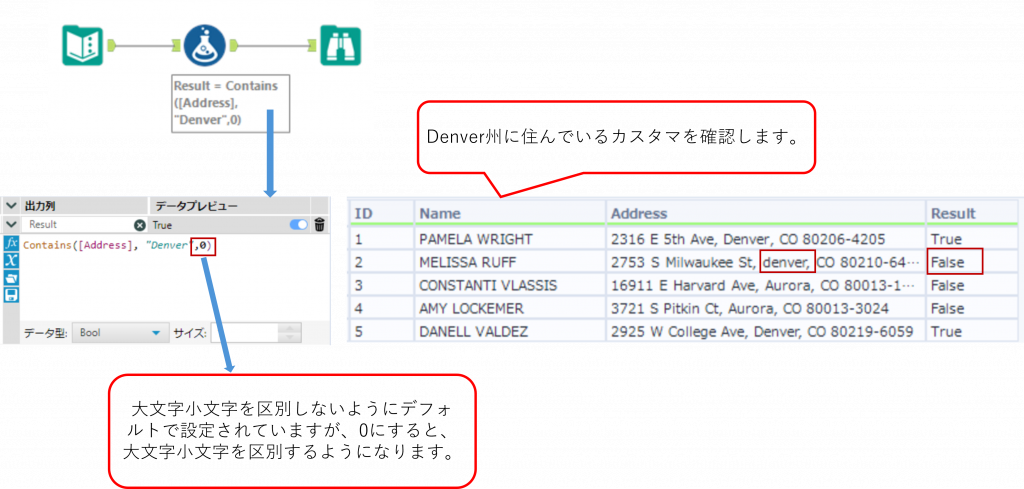
Contains ・・・ 指定した文字列が含まれているか確認
Contains(String, Target, CaseInsensitive)String で指定した文字列の中に、Target で指定した文字列が含まれるか確認します。Target で指定した文字列が含まれる場合は True、それ以外の場合は False を返します。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample
下の例では、「Address」列の文字列の中に、「Denver」という文字列が含まれるか確認しています。CaseInsensitive で 0 を指定して大文字小文字を区別しているため、2 行目の小文字の「denver」が含まれ場合は False が返っています。
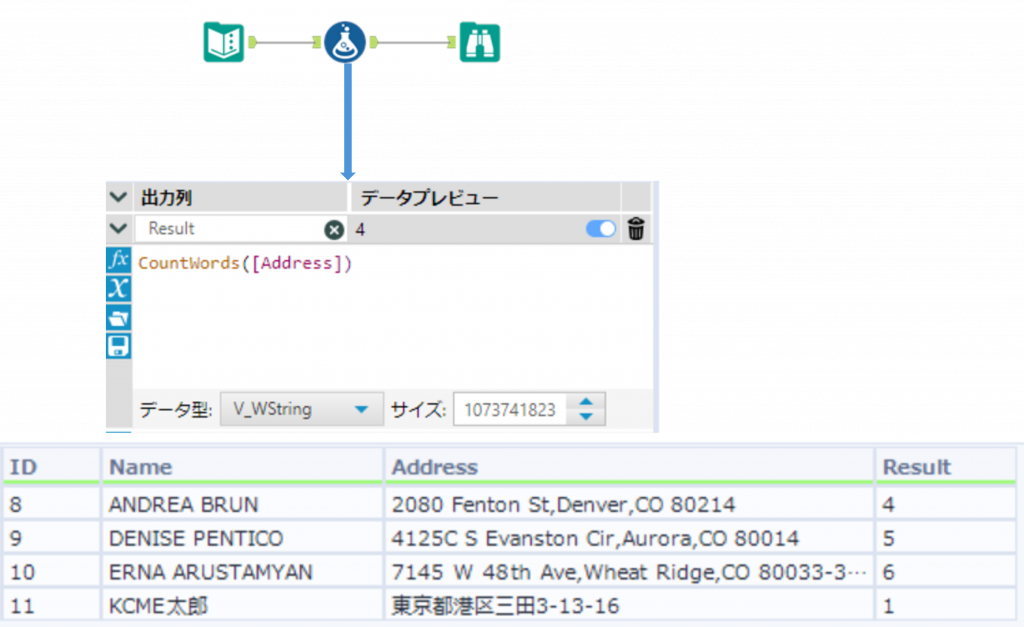
CountWords ・・・ 文字列内の単語数をカウント
CountWords(string)String で指定した文字列に対して、スペースで区切られた単語数を返します。戻り値は数値型となります。
注意
CountWords関数では、半角のスペース(半角の空白)のみを単語の区切りとして判断します。全角文字の空白は半角英数字と同様に処理されるため、単語の区切りとして認識されないので注意してください。
| Words | CountWords関数 結果 | 補足 |
|---|---|---|
| I have a pen. | 4 | 「I / have / a / pen.」で4単語。(単語の区切りが全て半角空白のため、正常に単語がカウントされます。) |
| I have a pen. | 3 | 「I / have / a pen.」で3単語。(have と a の間の区切りが全角空白のため、単語の区切りとして認識されず「a pen.」が一つの単語としてカウントされます。) |
| 私は ペンを 持っています。 | 1 | 使われているすべての空白が全角のため、単語の区切りが無い、文全体で一つの単語であると判断されます。 |
Sample
下の例では、「Address」列のスペースで区切られた単語数を取得できました。
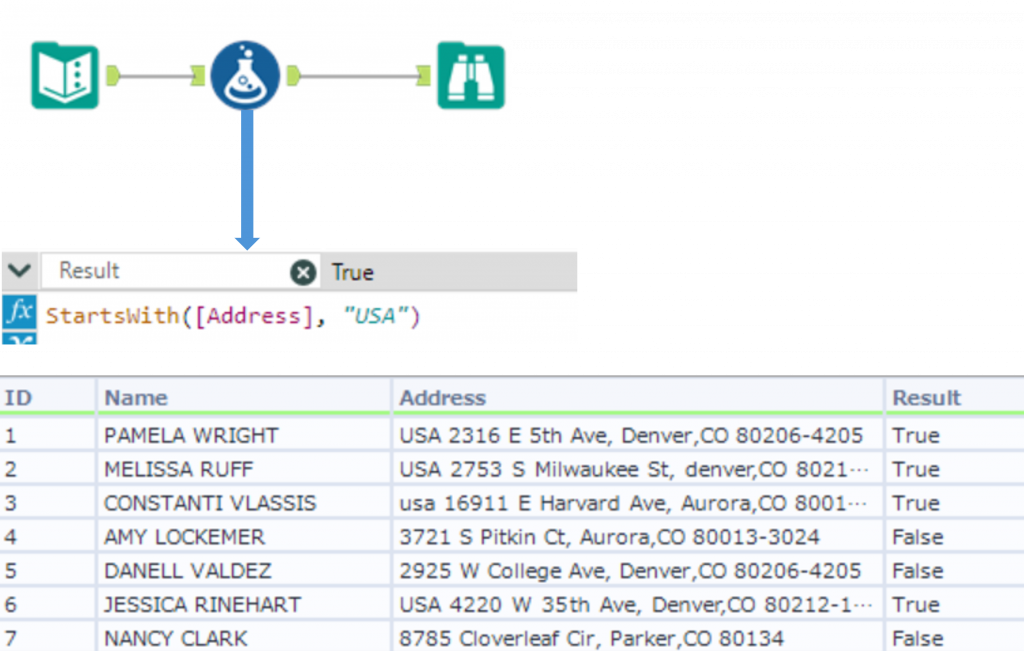
StartsWith ・・・ 指定した文字列で始まるかを確認
StartsWith(String, Target, CaseInsensitive=1)String で指定した文字列が、Target で指定した文字列で始まるかどうか確認します。戻り値はBool型となります。文字列が指定の文字列で始まる場合はTrue、それ以外はFalseを返します。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample
下の例では、「Address」列が「USA」という文字列で始まるか確認しています。CaseInsensitive を指定していないため、デフォルト設定で大文字小文字を区別しないようになっています。
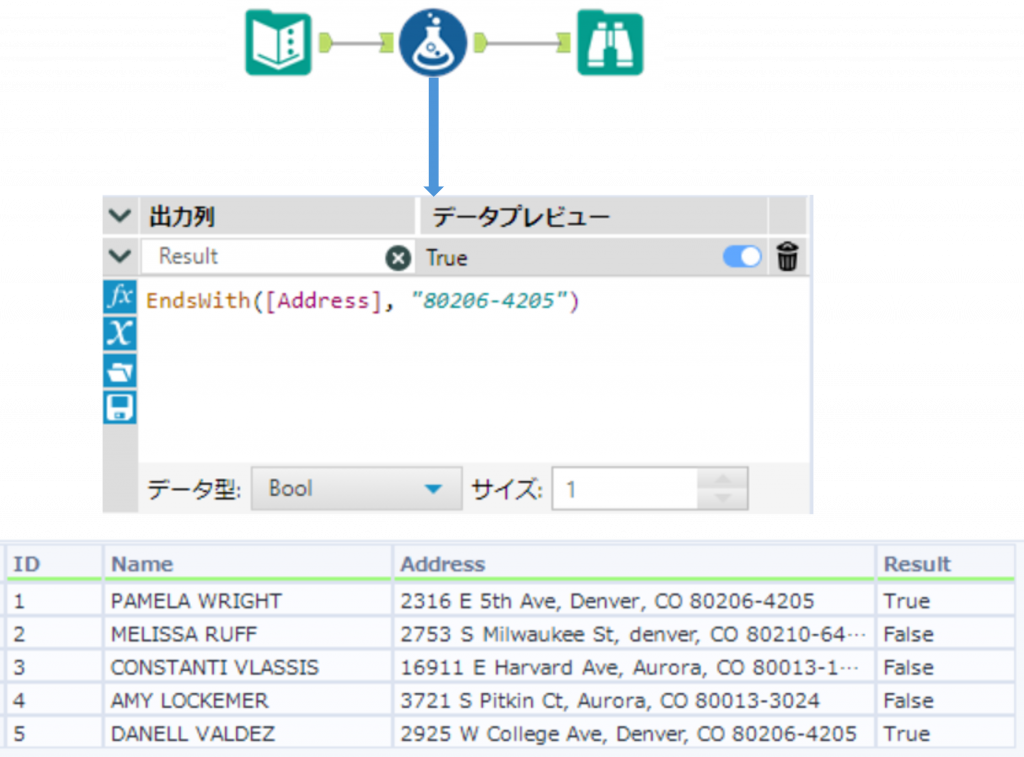
EndsWith ・・・ 指定した文字列で終わるかを確認
EndsWith(String, Target, CaseInsensitive=1)String で指定した文字列が、Target で指定した文字列で終わるかどうかをチェックします。戻り値はBool型となります。文字列が指定の文字列で終わる場合はTrue、それ以外はFalseを返します。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample
下の例では、「Address」列が「80206-4205」という文字列で終わるか確認しています。
FindString ・・・ 指定した文字列の出現位置を取得
FindString(String, Target)String で指定した文字列に対して、Target で指定した文字列の出現位置を返します。戻り値は数字となります。
最初の文字位置を0ベースのインデックスとして、何文字目に指定した文字列が出現するか、出現位置の数値を返します。文字列内に指定した文字列を含まれない場合は -1 を返します。
Sample
下の例では「Name」列の文字列に対して、0 から数えて何文字目に「太郎」という文字列が出現するか確認しています。「太郎」という文字列が含まれない場合は -1 の値が返っています。
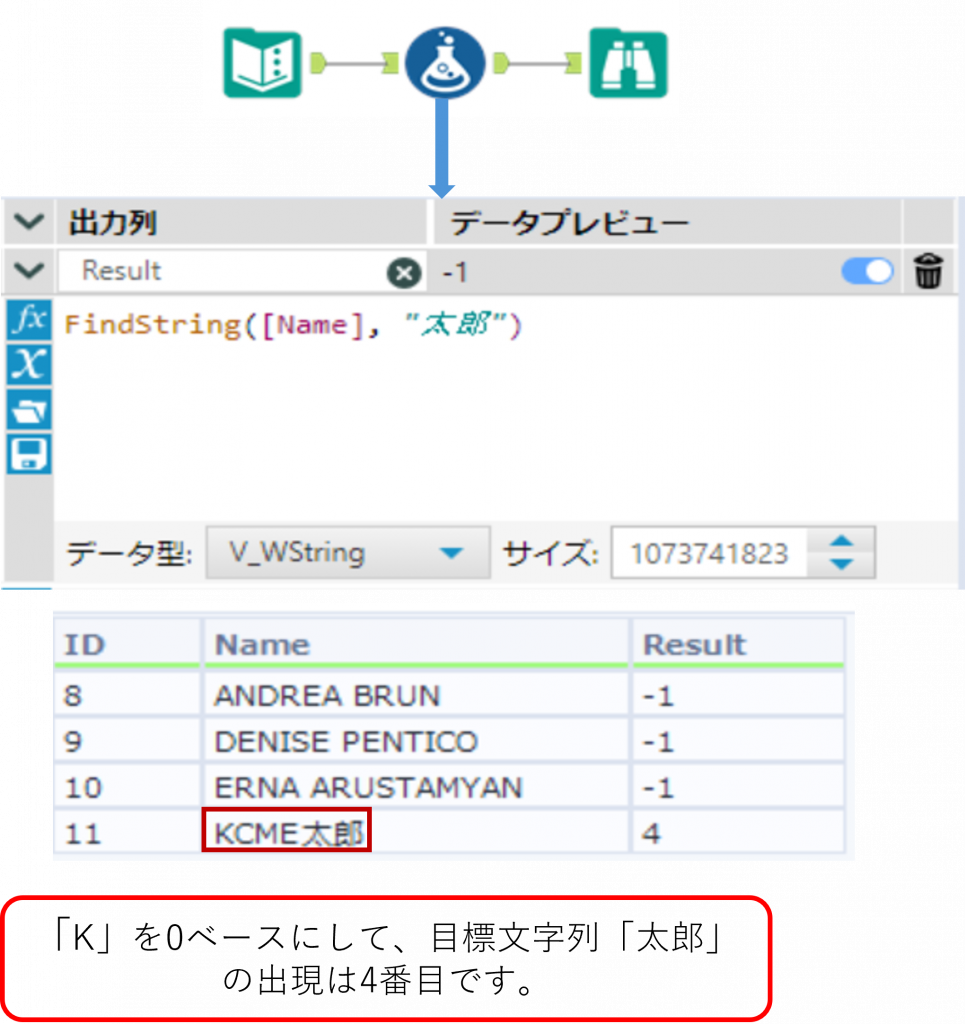
GetWord ・・・ 指定した位置の単語を取得
GetWord(String, n)String で指定した文字列の中で、n 番目の単語を取得します。戻り値は文字列となります。最初の文字位置を0ベースのインデックスとして、 n番目の単語(スペースで区切られた文字の集合)を返します。
注意
GetWord関数では、半角のスペース(半角の空白)のみを単語の区切りとして判断します。全角文字の空白は半角英数字と同様に処理されるため、単語の区切りとして認識されないので注意してください。
| Words | 補足 |
|---|---|
| I have a pen. | 「I / have / a / pen.」で4単語。(単語の区切りが全て半角空白のため、正常に単語がカウントされます。) |
| I have a pen. | 「I / have / a pen.」で3単語。(have と a の間の区切りが全角空白のため、単語の区切りとして認識されず「a pen.」が一つの単語としてカウントされます。) |
| 私は ペンを 持っています。 | 使われているすべての空白が全角のため、単語の区切りが無い、文全体で一つの単語であると判断されます。 |
Sample
下の例では「Name」列の文字列に対して、0 から数えて 1 番目の単語を取得しています。取得できない場合は Null が返っています。
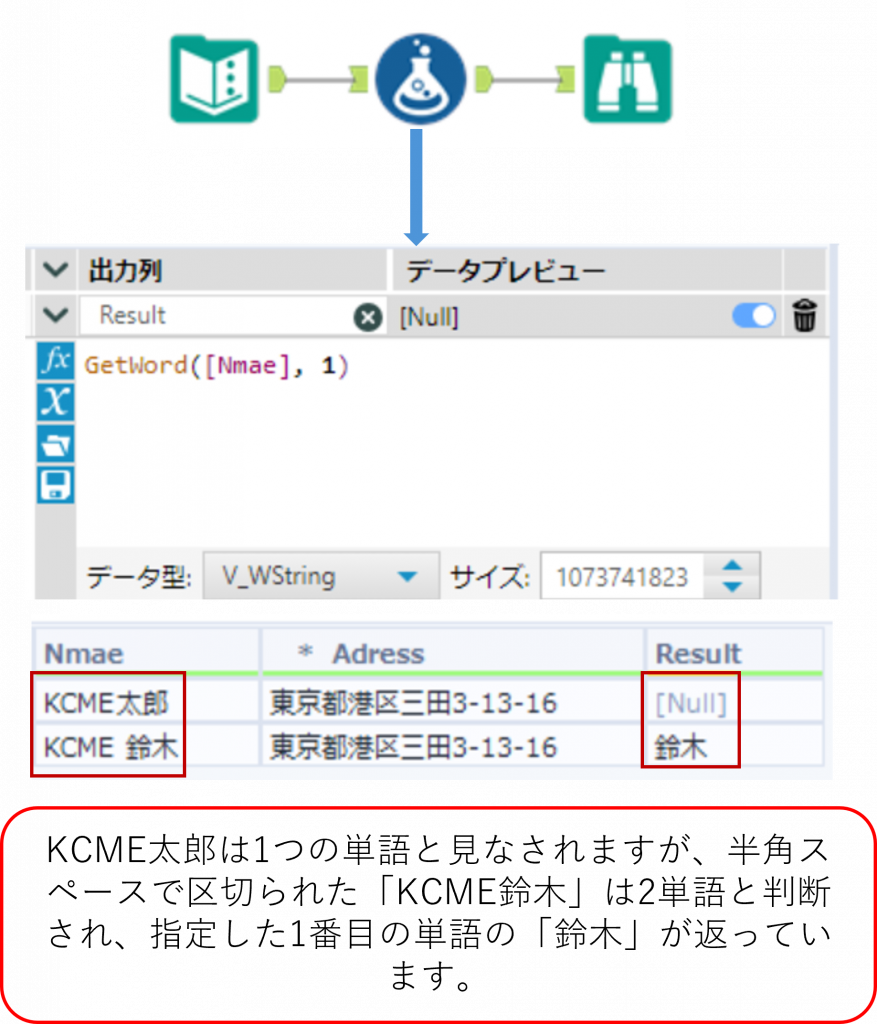
Left ・・・ 指定した文字数を抽出
Left(String, len)String で指定した文字列に対して、左から len 番目までの文字を抽出します。戻り値は文字列となります。len が0より小さい、または文字列の長さより大きい場合、String で指定した文字列がそのまま返ります。
Sample
下の例では「Address」列の文字列に対して、左から 6 文字を取得しています。3 行目では「Address」列が 6 文字未満のため、「Address」列の値がそのまま返っています。
Right ・・・ 指定した文字数を抽出
Right(String, len)String で指定した文字列に対して、右から 指定した番目までの文字を抽出します。戻り値は文字列となります。len が0より小さい、または文字列の長さより大きい場合、String で指定した文字列がそのまま返ります。
Sample
下の例では「Address」列の文字列に対して、右から 6 文字を取得しています。3 行目では「Address」列の「中国上海」が 6 文字未満のため、「Address」列の値がそのまま返っています。
![]()
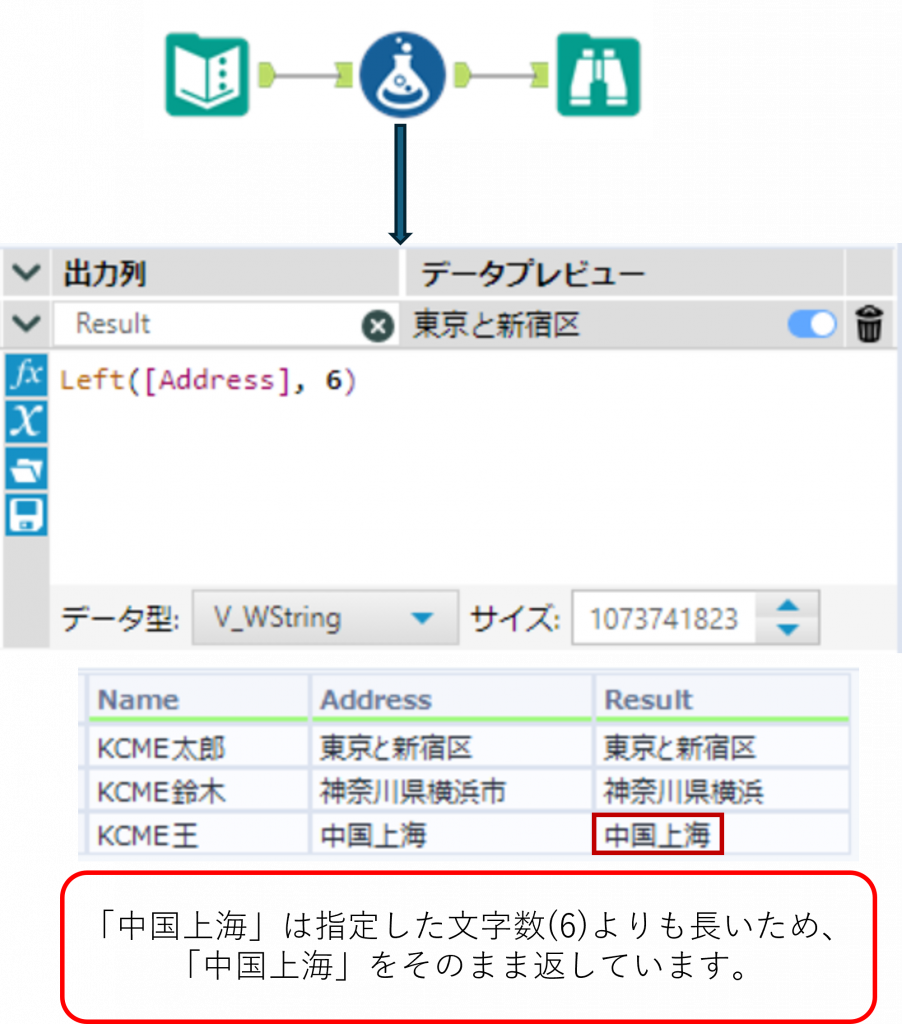
Length ・・・ 文字列の長さを取得
Length(String)String で指定した文字列の文字数を取得します。戻り値は数値型になります。(半角、全角の空白も1文字と数えられます。)
Sample
下の例では「Address」列の文字列に対して、右から 6 文字を取得しています。3 行目では「Address」列が 6 文字未満のため、「Address」列の値がそのまま返っています。
LowerCase ・・・ 大文字を小文字に変換
LowerCase(String)String で指定した文字列に対して、大文字を小文字に変換します。戻り値は文字列となります。
Sample
下の例では、「Name」列の大文字が小文字に変換されました。
![]()
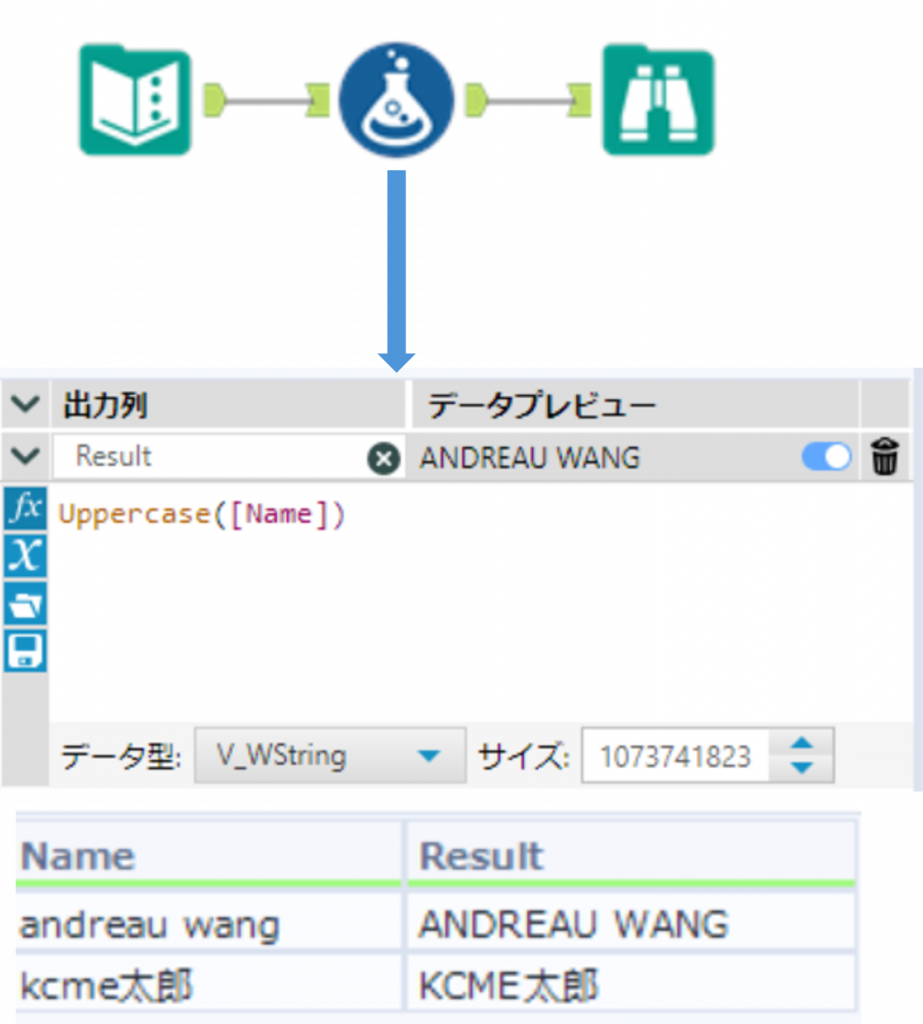
UpperCase ・・・ 小文字を大文字に変換
UpperCase(String)小文字を大文字に変換します。戻り値は文字列となります。
Sample
下の例では、「Name」列の小文字が大文字に変換されました。
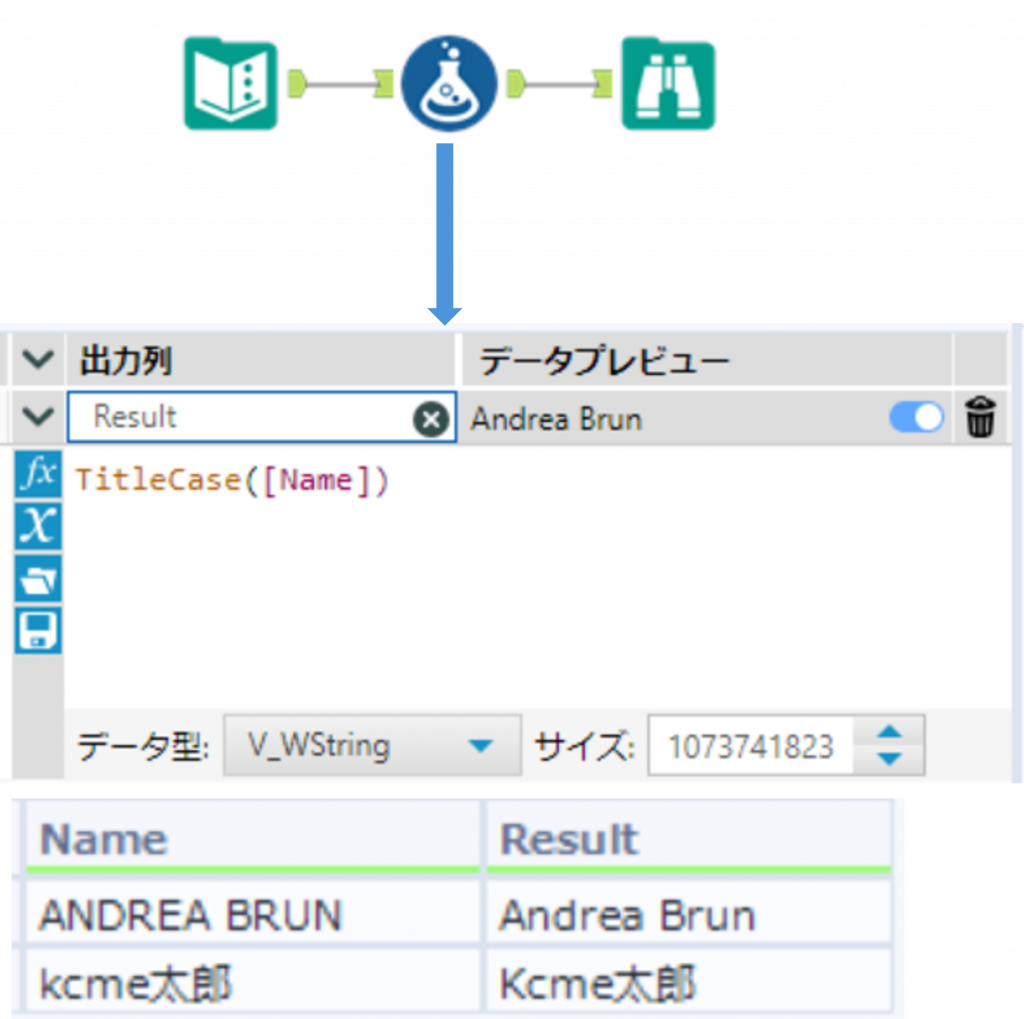
TitleCase ・・・ 文字列を先頭文字を大文字、それ以外は小文字に変換
TitleCase(String)String で指定した文字列のアルファベットに対して、最初の文字は大文字、それ以外の文字はすべて小文字に変換します。戻り値は文字列となります。アルファベット以外の文字については String の文字がそのまま返ります。
Sample
下の例では「Name」列のアルファベットの文字列が、最初の文字は大文字、それ以外の文字がすべて小文字に変換されました。
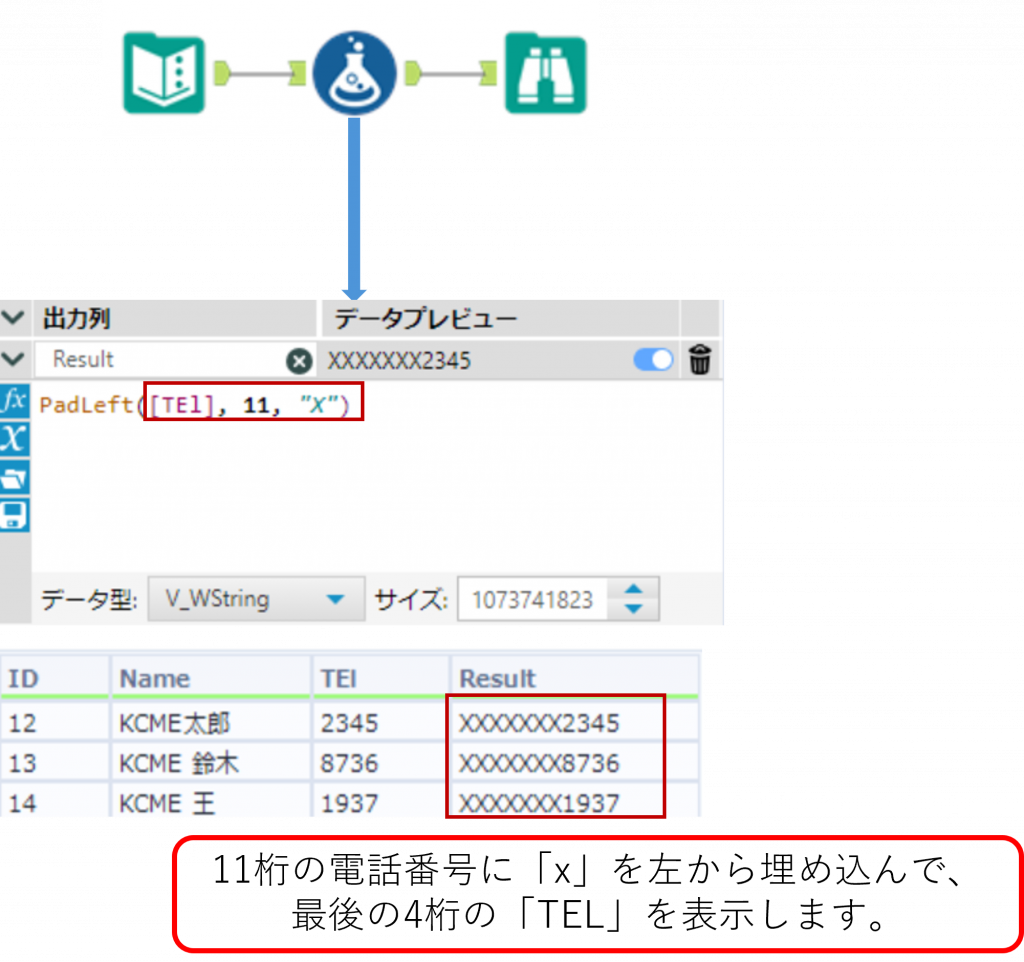
PadLeft ・・・ 文字列の埋め込み
PadLeft(String, len, char)String で指定した文字列に対して、左に char で指定した文字列を埋め込みます。全体の文字数は len で指定された文字数に調節されます。戻り値は文字列となります。「char」 が2文字以上の場合、最初の文字のみが使用されます。
Sample
下の例では「TEL」列の 4 文字に対して、全体の文字数が 11 文字になるように、左に「X」が埋め込まれました。
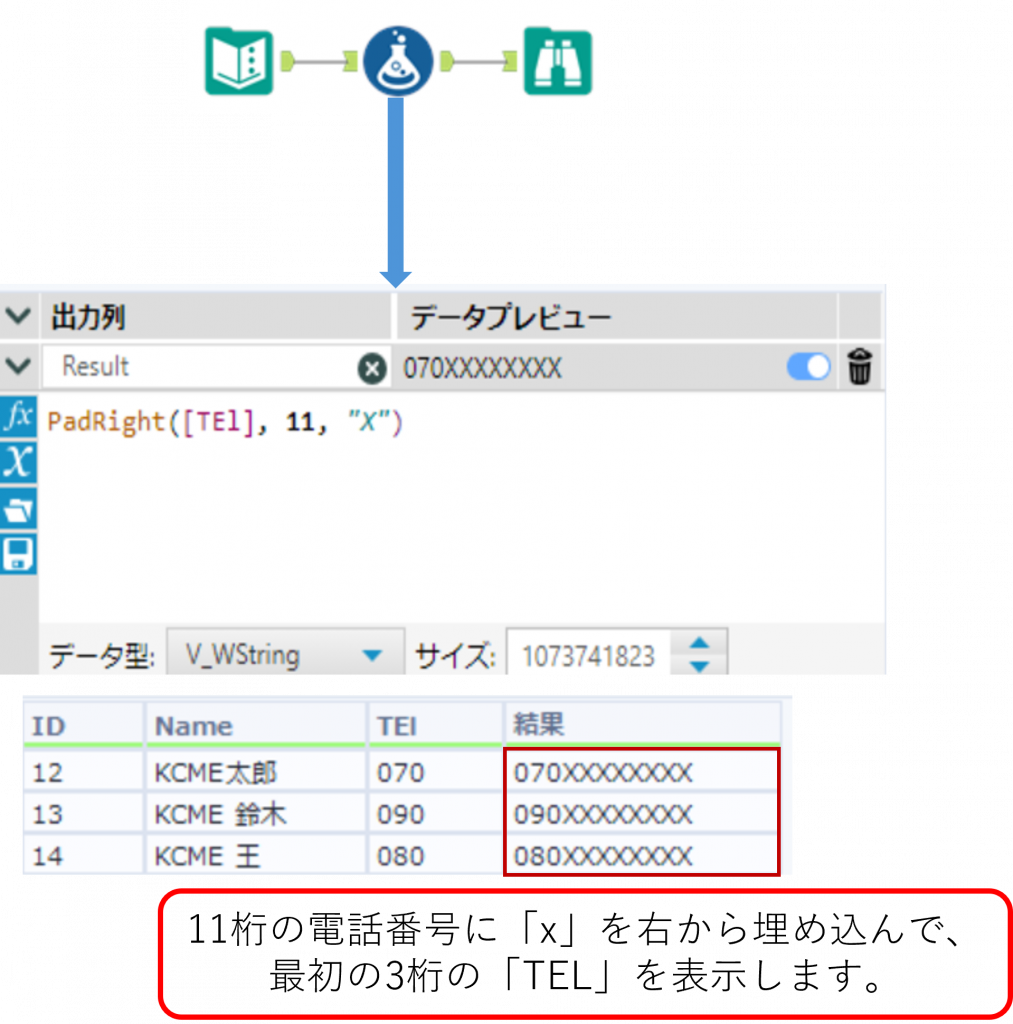
PadRight ・・・ 文字列の埋め込み
PadRight(String, len, char)
String で指定した文字列に対して、右に char で指定した文字列を埋め込みます。全体の文字数は len で指定された文字数に調節されます。戻り値は文字列となります。「char」 が2文字以上の場合、最初の文字のみが使用されます。
Sample
下の例では「TEL」列の 3 文字に対して、全体の文字数が 11 文字になるように、右に「X」が埋め込まれました。
REGEX_CountMatches ・・・ 指定したパターンと一致する文字列をカウント
REGEX_CountMatches(String, pattern,CaseInsensitive=1)String で指定した文字列の中で、pattern で指定した文字列や正規表現と何回一致したかカウントして返します。戻り値は数字となります。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample1
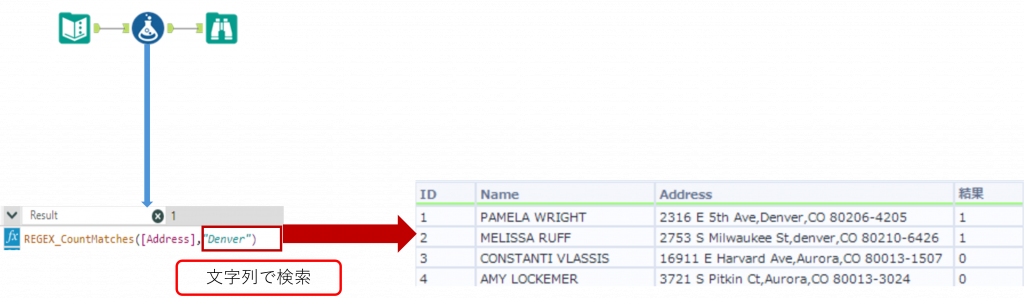
下の例では「Address」列に対して、「Denver」という文字列が何回一致したかを取得しています。CaseInsensitive を指定していないため、デフォルトとして大文字小文字を区別しない設定になっています。
Sample2
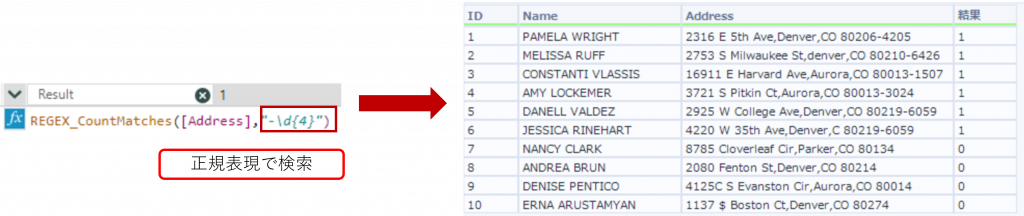
下の例では「Address」列に対して、正規表現「-\d{4}」(ハイフン - の後に数字4文字)で表される文字列が何回一致したかを取得しています。CaseInsensitive を指定していないため、デフォルトとして大文字小文字を区別しない設定になっています。
REGEX_Match ・・・ パターンと一致するかを確認
REGEX_Match(String, pattern)String で指定した文字列の中で、pattern で指定した文字列や正規表現が存在するかチェックします。戻り値はBool型となります。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample
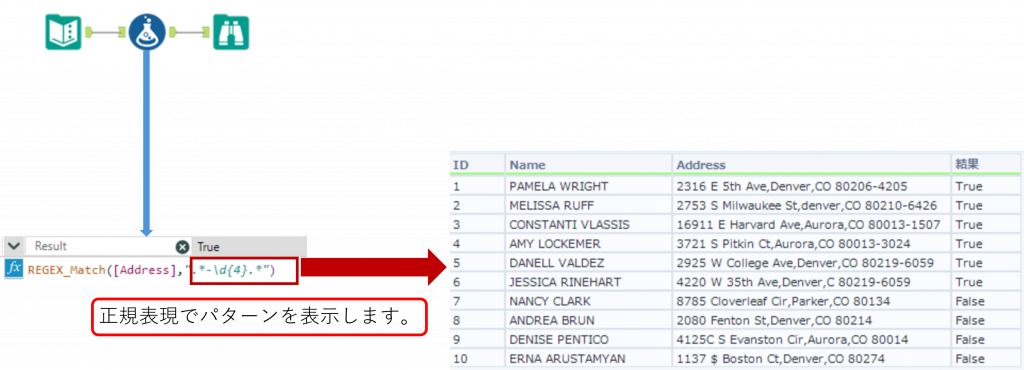
下の例では「Address」列に対して、正規表現「-\d{4}」(ハイフン - の後に数字4文字)で表される文字列が存在するか確認しています。
REGEX_Replace ・・・ パターンと一致する部分の置き換え
REGEX_Replace(String, pattern, replace)String で指定した文字列の中で、pattern で指定した文字列や正規表現を、replace で指定した文字列に置き換えます。戻り値は文字列となります。
オプションとしてCaseInsensitive で 0 または 1 を指定できます。(CaseInsensitive で 0 を指定すると大文字小文字を区別し、 1 を指定すると大文字小文字を区別しない設定になります。)CaseInsensitive を指定しない場合は、デフォルトとして大文字小文字を区別しない設定になります。
Sample
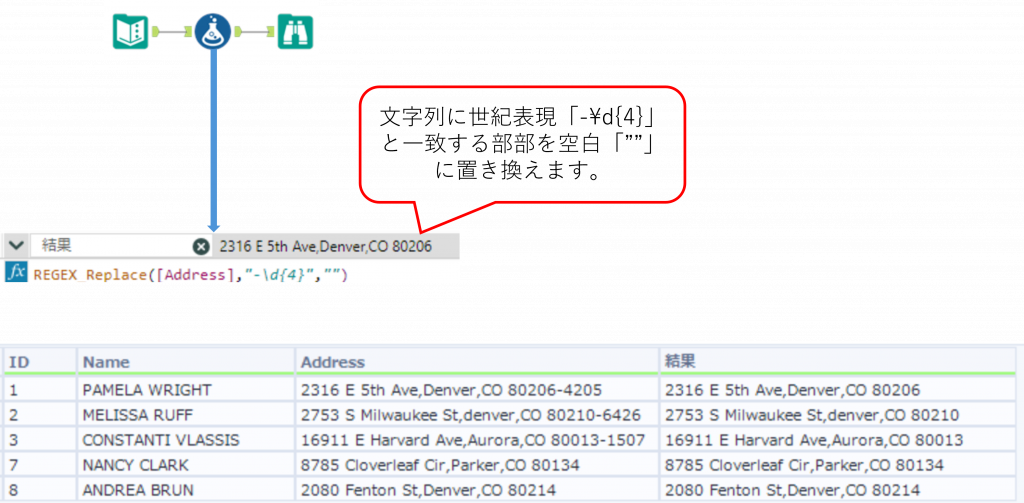
下の例では「Address」列に対して、正規表現「-\d{4}」(ハイフン - の後に数字4文字)で表される文字列を、空白("")に置き換えることで削除しています。
Replace ・・・ 目標文字列の置き換え
Replace(String, Target, Replacement)String で指定した文字列内の、Target で指定した文字列を、Replacement で指定した文字列で置換します。戻り値は文字列となります。
Sample
下の例では「Mail」列に対して、文字列「kccs」を「kcme」で置換しています。

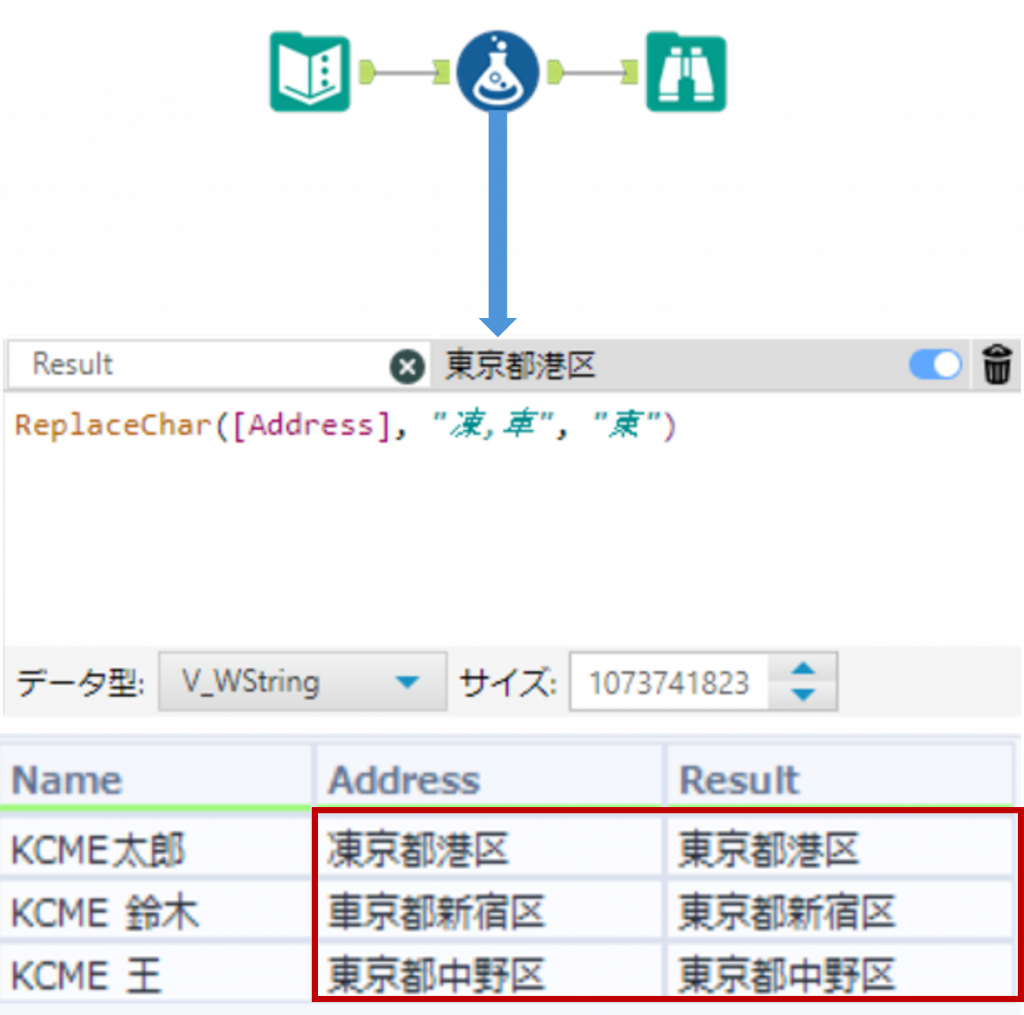
ReplaceChar ・・・ 指定した文字の置き換え
ReplaceChar(String, y, z)String で指定した文字列内の y で指定した文字を、z で指定した文字で置換します。yで指定する文字はカンマ( , )で区切ることによって複数指定できます。戻り値は文字列となります。
Sample
下の例では「Address」列に対して、「凍」または「車」の字を、「東」の字で置換しています。
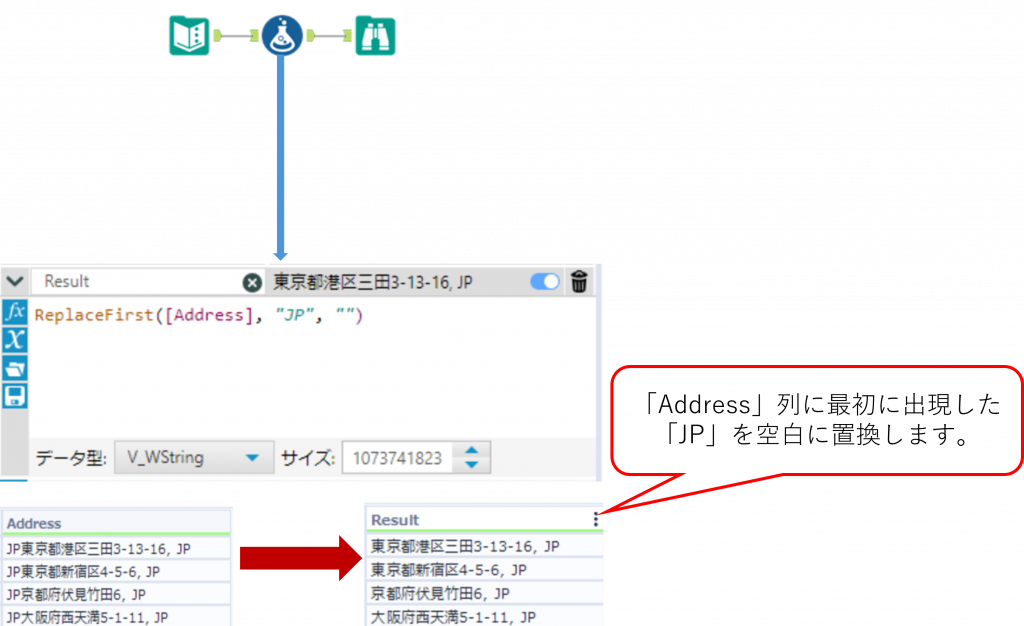
ReplaceFirst ・・・ 文字列内の最初に出現する文字列の置き換え
ReplaceFirst(String, Target, Replacement)String で指定した文字列内の、最初に出現するTarget で指定した文字列を、Replacement で指定した文字列で置換します。戻り値は文字列となります。
Replacement関数が String 文字列内のすべての Target 文字列を置換するのに対して、ReplaceFirst関数は最初(一番左)の Target文字列のみを置換します。
Sample
下の例では「Address」列内の一番左の「JP」を、空白で置換することで削除しています。
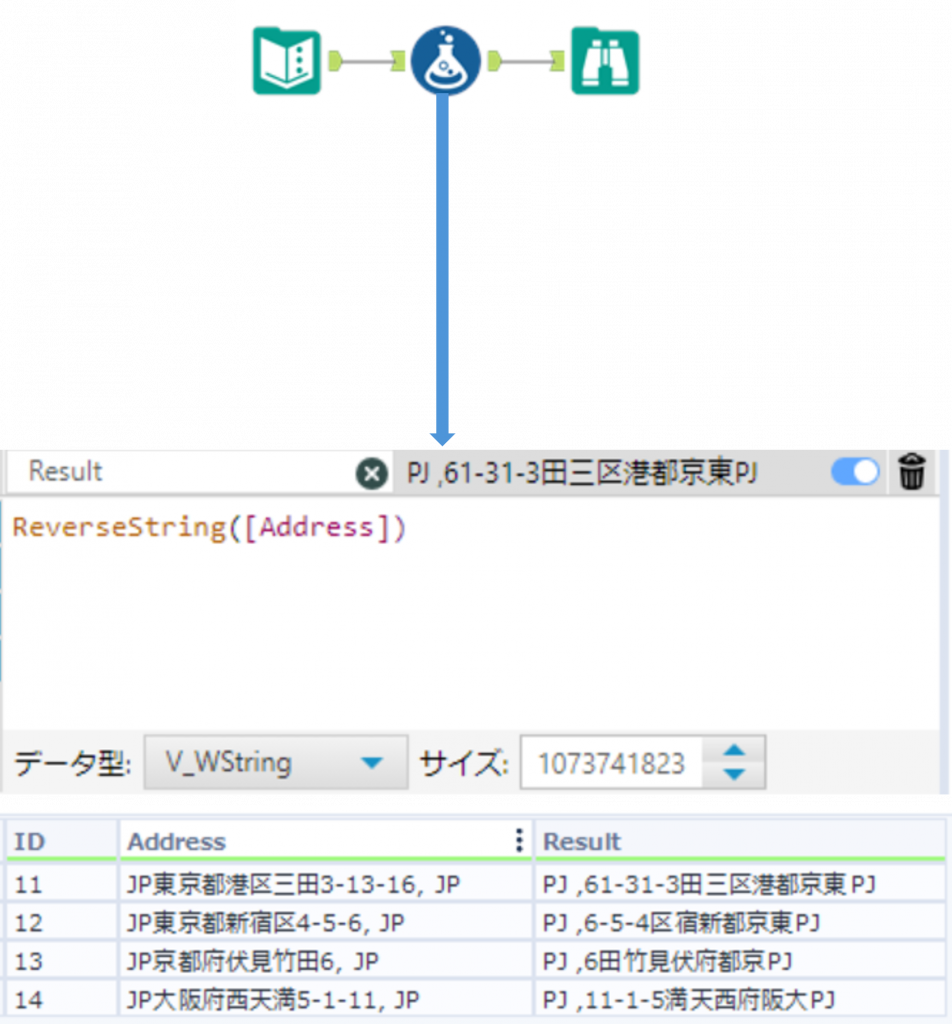
ReverseString ・・・ 文字の反転
ReverseString(String)String で指定した文字列の順番を反転します。戻り値は文字列型となります。
Sample
下の例では「Address」列の文字の順番を反転させた文字列を取得しています。
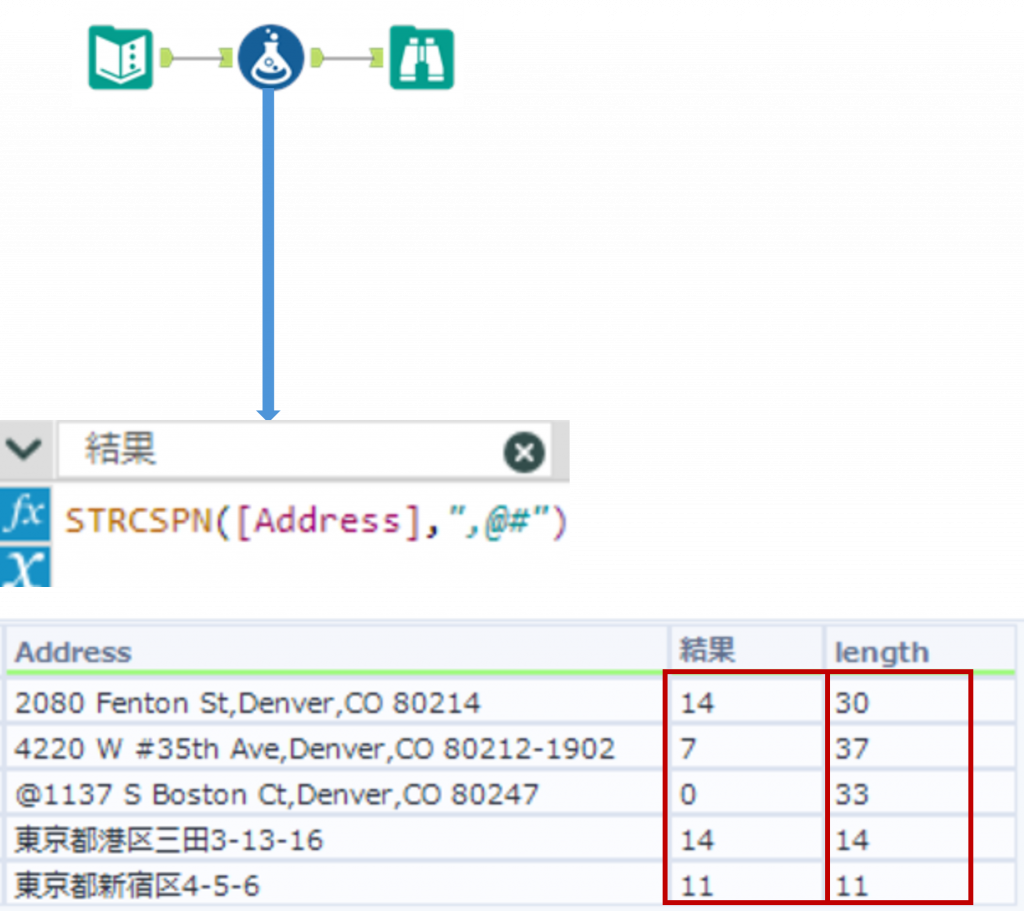
STRCSPN ・・・ 指定文字以外で構成されるセグメントの文字数を取得
STRCSPN(String,y)String で指定した文字列に対して、y で指定した文字以外で構成される文字列の、最初のセグメントの長さを返します。y には複数の文字を指定できます。戻り値は数字となります。
Sample
下の例では「Address」列の文字の中で、特殊文字である「,」「@」「#」以外の文字で構成される最初のセグメントの文字数を取得しています。Length関数で取得した文字数「length」列と比較すると、4行目、5行目は特殊文字が入っていないため、STRCSPN関数の結果と同じ値が取得されています。
STRSPN ・・・ 指定した文字で構成されるセグメントの文字数を取得
STRSPN(String,y)String で指定した文字列に対して、y で指定した文字で構成される文字列の、最初のセグメントの長さを返します。y には複数の文字を指定できます。戻り値は数字となります。
Sample
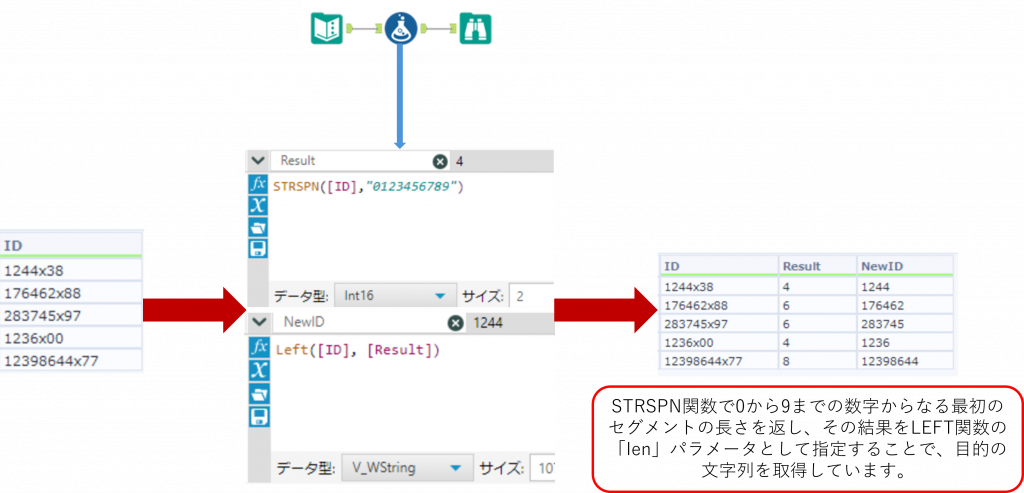
下の例では「Address」列に対して、文字「x」より左の数字(0 から 9 の数字で構成される文字列)を取得しようとしています。
STRSPN関数とLEFT関数を組み合わせて、目的の文字列を取得しています。
Substring ・・・ 一部の文字列の抽出
Substring(String, start, length)String で指定した文字列に対して、指定される長さと開始位置で文字列を返します。start で左から何文字目からを抽出をスタートするかを指定し、length で抽出する文字数を指定します。戻り値は文字列となります。
Sample
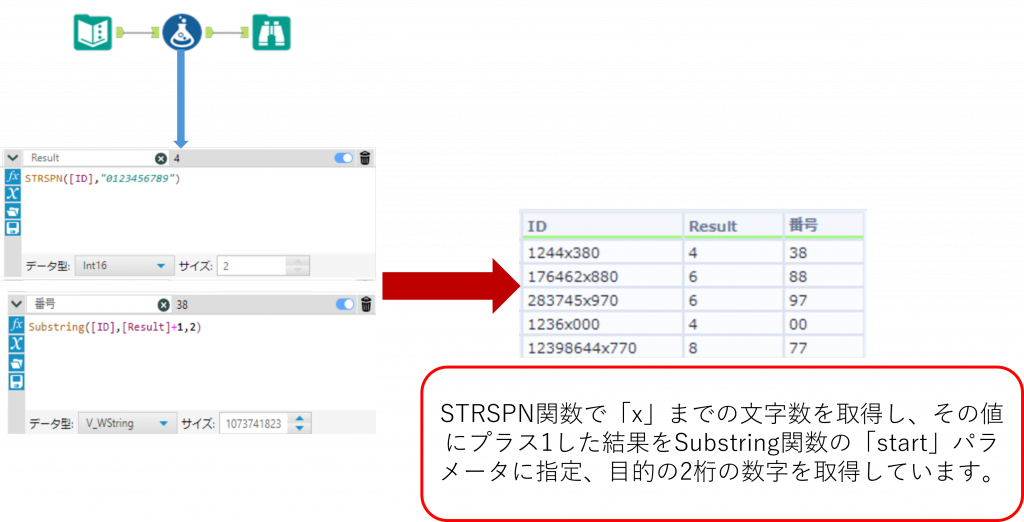
下の例では「Address」列に対して、文字「x」の右2桁の数字(0 から 9 の数字で構成される 2 文字)を取得しようとしています。
STRSPN関数とSubstring関数を組み合わせることで、目的の文字列を取得しています。
StripQuotes ・・・ 引用符の削除
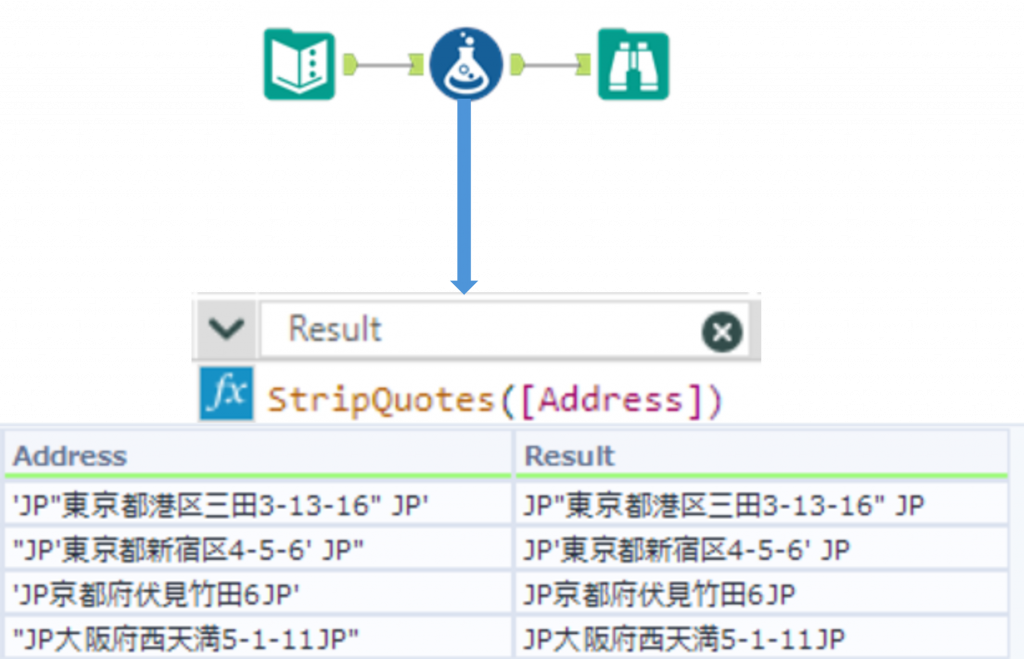
StripQuotes(String)文字列から引用符を削除します。戻り値は文字列となります。
Sample
下の例では、「Address」列に対して文字列の末尾から引用符またはアポストロフィーを削除しています。
Trim ・・・ 文字の削除
Trim(String,y)
「y」で指定した文字を、文字列の先頭と末尾から削除します。戻り値は文字列となります。「y」を指定しない場合は、デフォルトで両端の空白を削除します。
TrimLeft ・・・ 先頭の文字を削除
TrimLeft(String,y)
「y」 で指定した文字を、文字列の先頭から削除します。戻り値は文字列となります。「y」を指定しない場合は、デフォルトで先頭の空白を削除します。
TrimRight ・・・ 末尾の文字を削除
TrimRight(String,y)
「y」で指定した文字を、 文字列の末尾から削除します。戻り値は文字列となります。「y」を指定しない場合は、デフォルトで末尾の空白を削除します。
Sample(Trim関数、TrimLeft関数、TrimRight関数)

UuidCreate ・・・ 固有識別子の生成
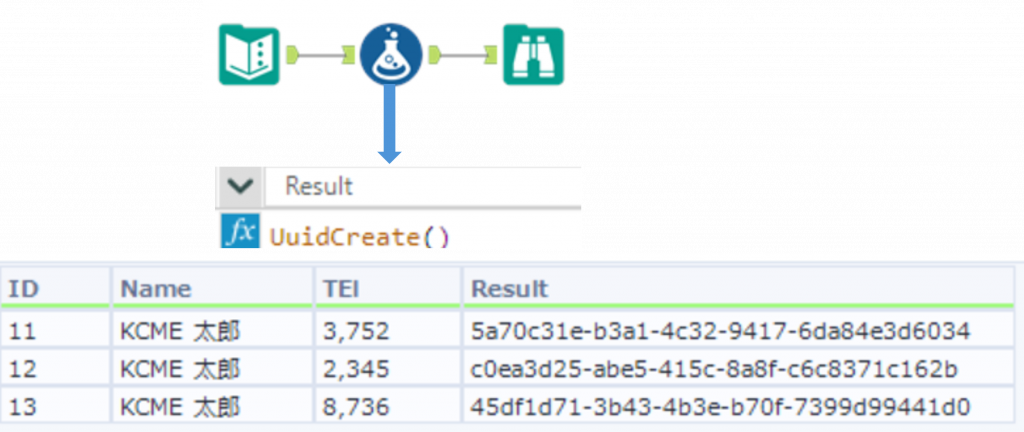
UuidCreate()ユニークな識別子を作成します。戻り値は文字列となります。パラメータはありません。ワークフローを実行する度に、毎回異なるユニークな識別子が作成されます。
Sample
下の例では、UuidCreate関数でユニークな識別子(ユニークID)を作成しています。
FindNth ・・・ 指定した文字が何番目に出現するかを検索
FindNth(InitialString, Target, Instance)文字列の中から指定した文字が 何番目に出現するか を検索し、その位置を返します。位置は 1 から数えられ、該当する文字が存在しない場合は -1 が返されます。
Sample1
下の例では、FindNth関数で - の文字が何番目に出現するかを検索しその値を取得しています。
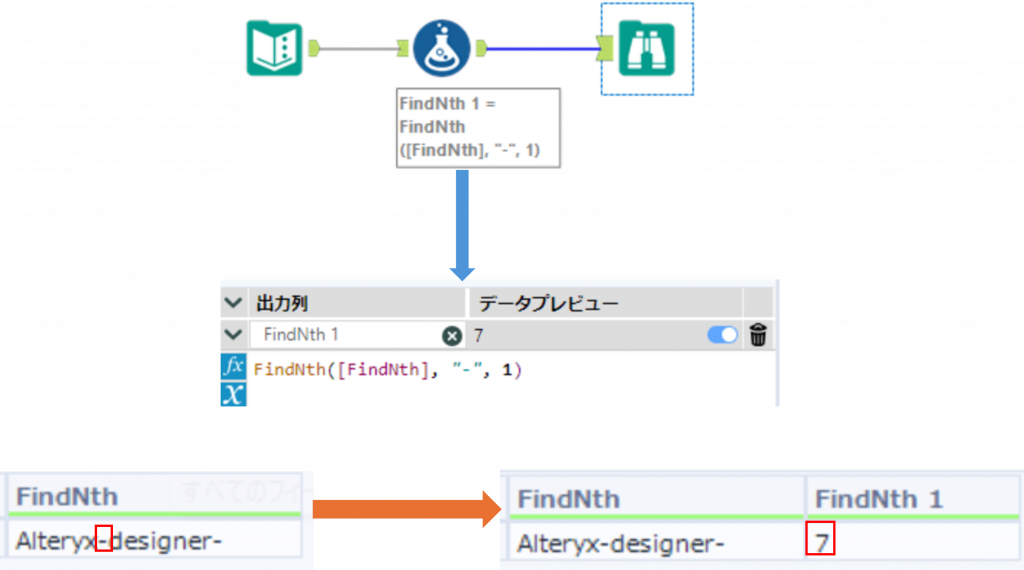
Sample2
下の例では、2番目にある - の位置の値を検索し取得しています。
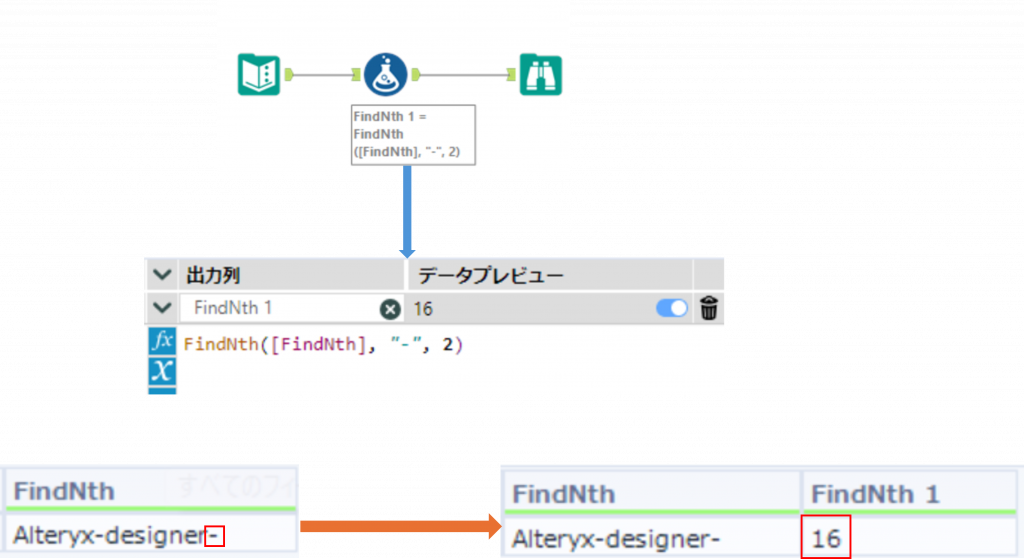
Sample3
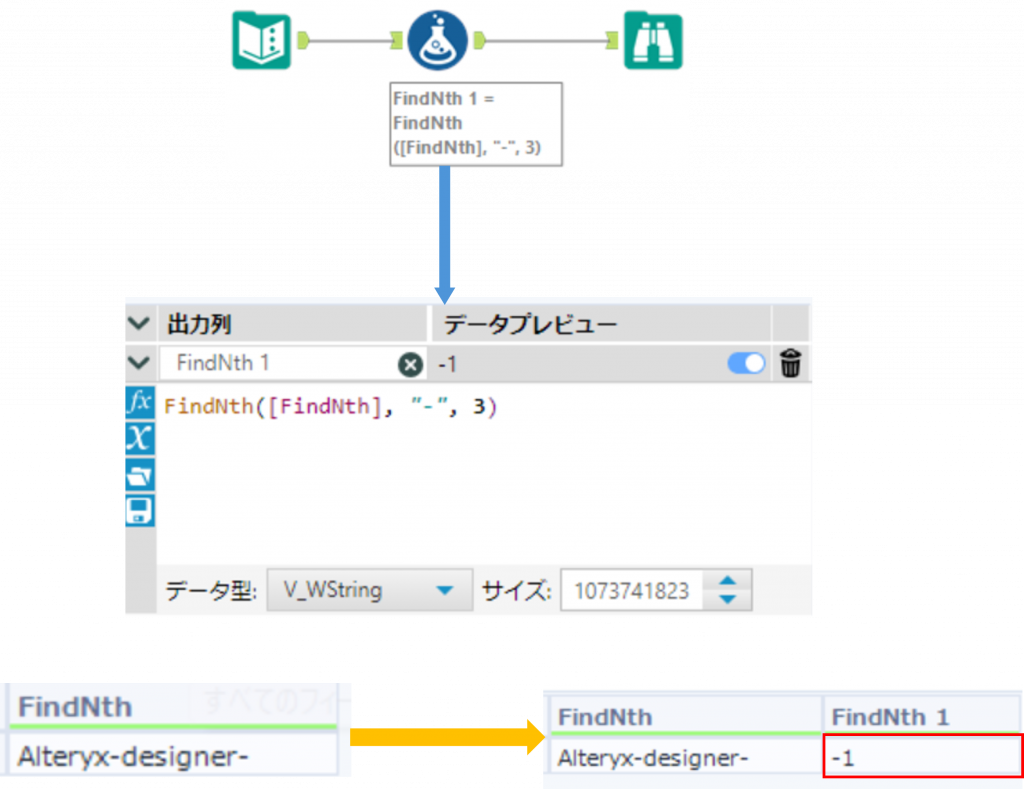
下の例では、指定した対象の文字が指定した回数分存在しない場合、-1を返します。
GetLeft ・・・ 区切り文字の最初の出現位置より左側の文字列を取得
GetLeft(String, Delimiter)指定した区切り文字が最初に出現する位置を基準として、その左側の文字列を取得します。
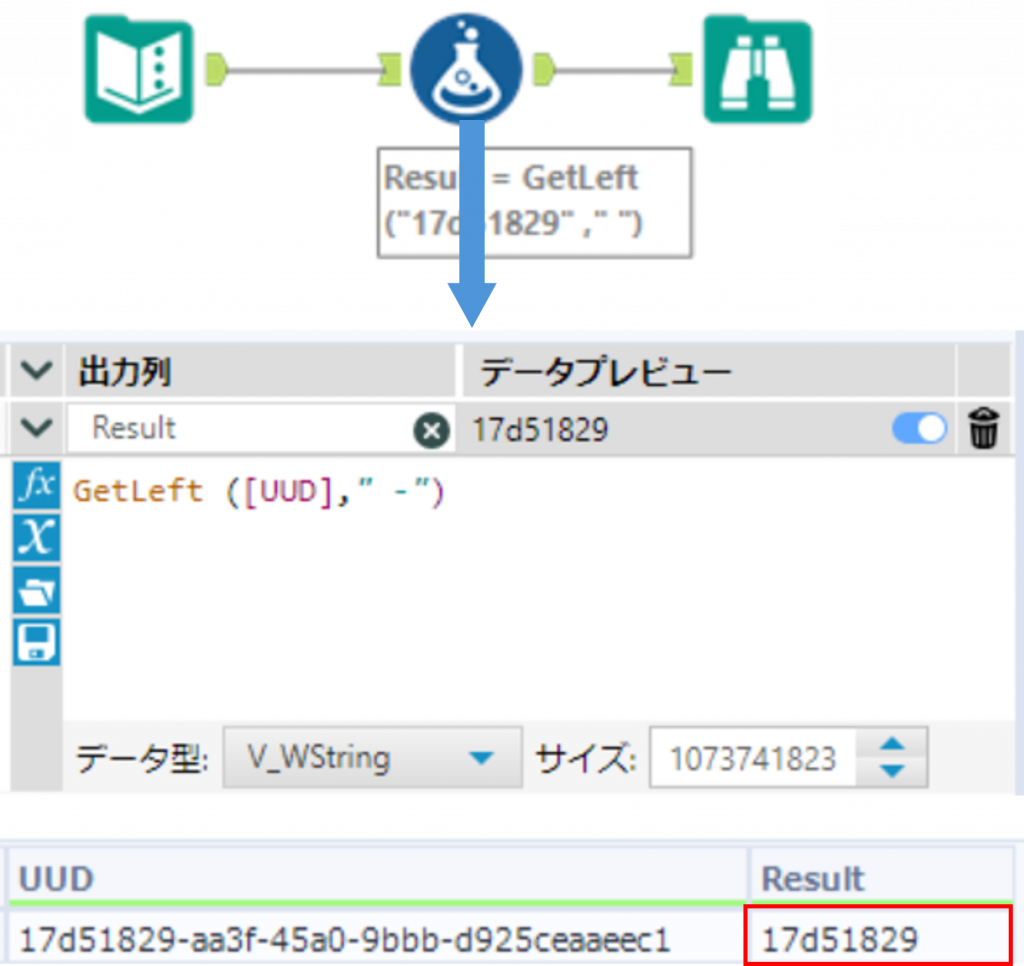
Sample1
下の例では、指定した区切り文字 - が最初に出現する位置を基準として、その左側の文字列を取得しています。
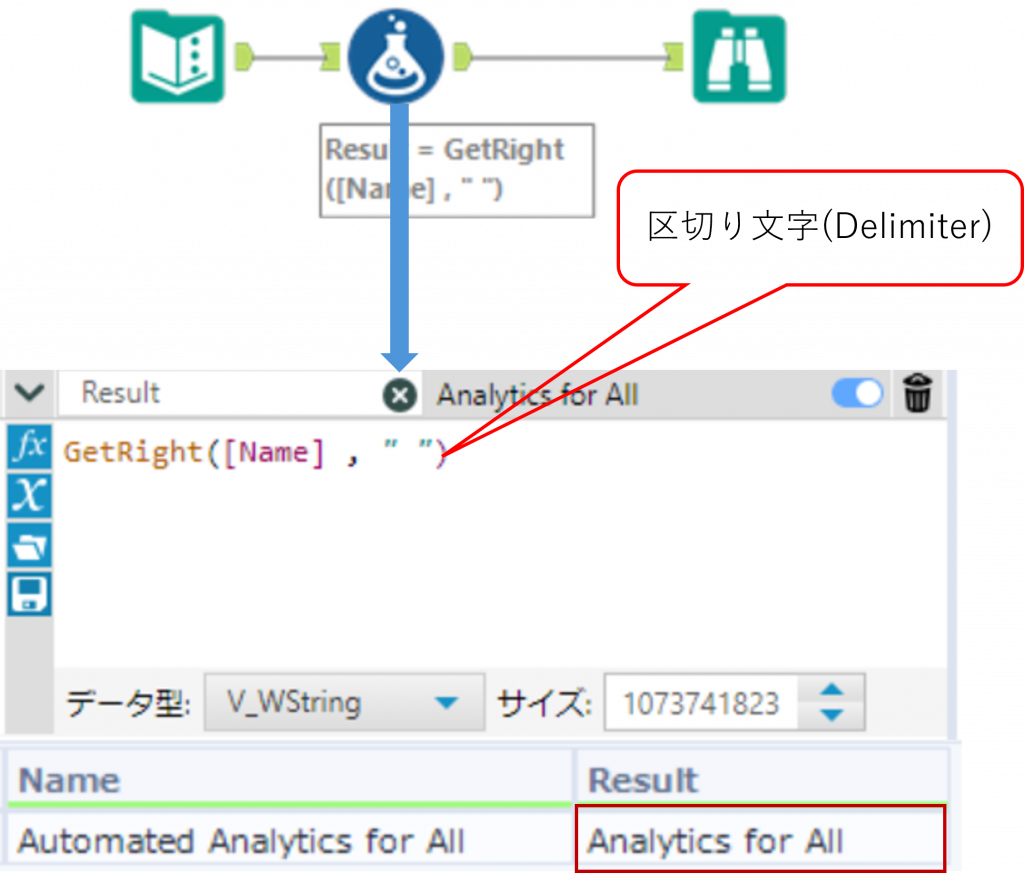
GetRight ・・・区切り文字の最初の出現位置より右側の文字列を取得
GetRight(String, Delimiter)指定した区切り文字が最初に出現する位置を基準として、その右側の文字列を取得します。
Sample
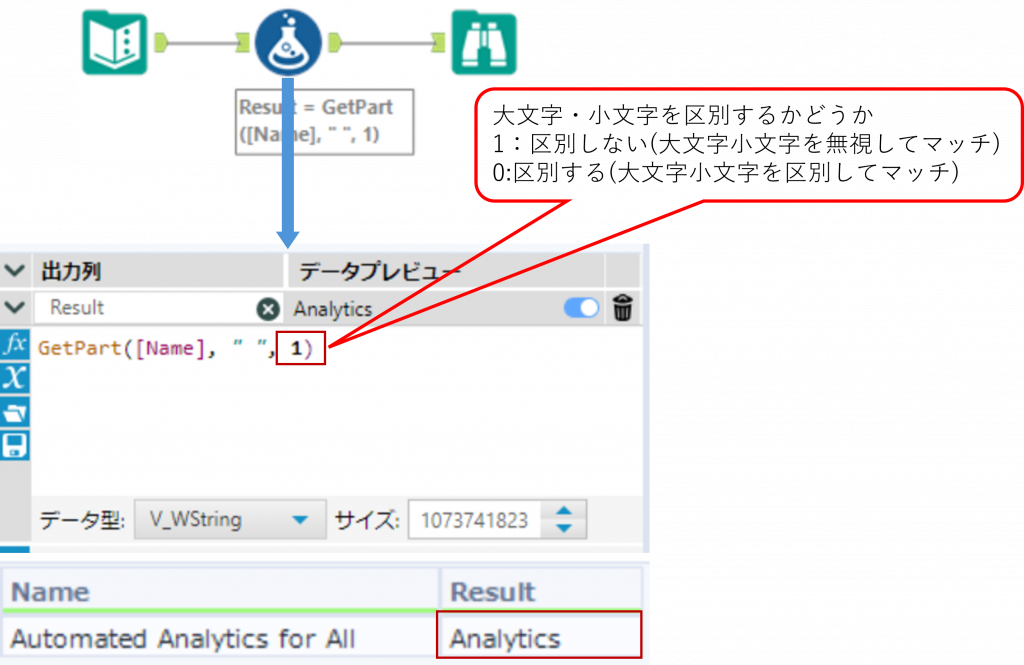
GetPart ・・・区切り文字で分割した文字列の、指定した位置の要素を取得
GetPart(String, Delimiter, Index)区切り文字を基準に文字列を分割し、インデックスで指定した順番の要素を返します。
Sample1
下の例では、区切り文字として空文字を指定することで、文字列を 1 文字単位で扱い、指定した位置の文字を取得しています。
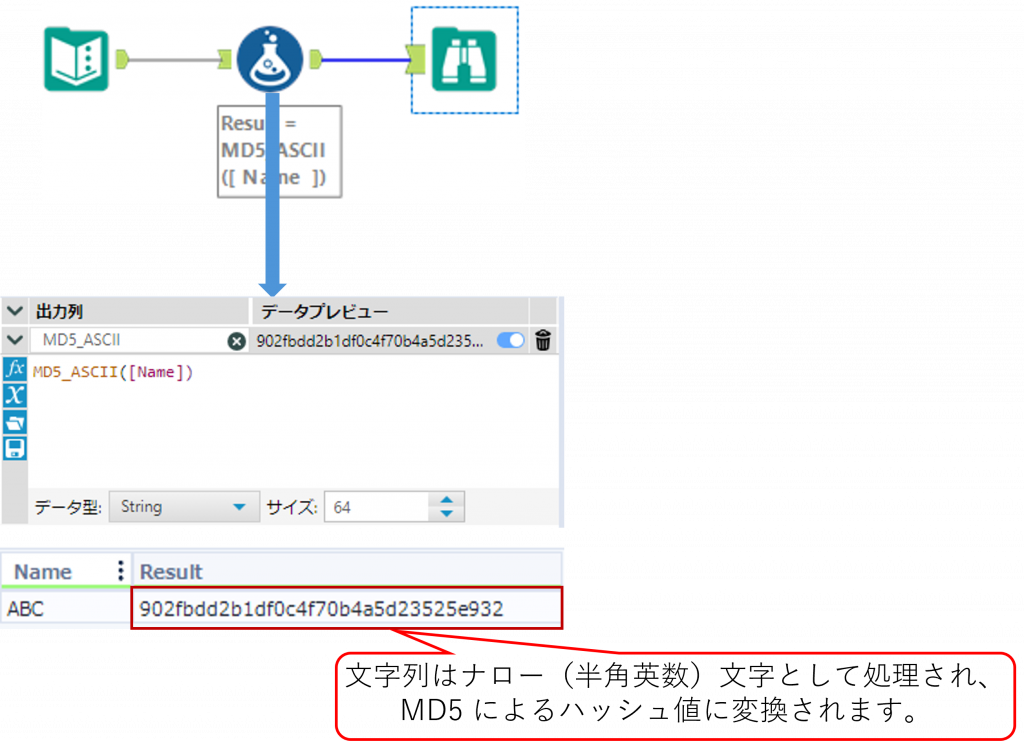
MD5_ASCII ・・・ASCII 文字列から MD5 ハッシュ値を生成
MD5_ASCIIMD5_ASCII は、文字列を ASCII として扱い、MD5 アルゴリズムによるハッシュ値を返します。
Sample1
下の例では、半角英数字のみで構成された文字列を入力し、文字列をそのまま ASCII として処理して MD5 のハッシュ値を生成しています。
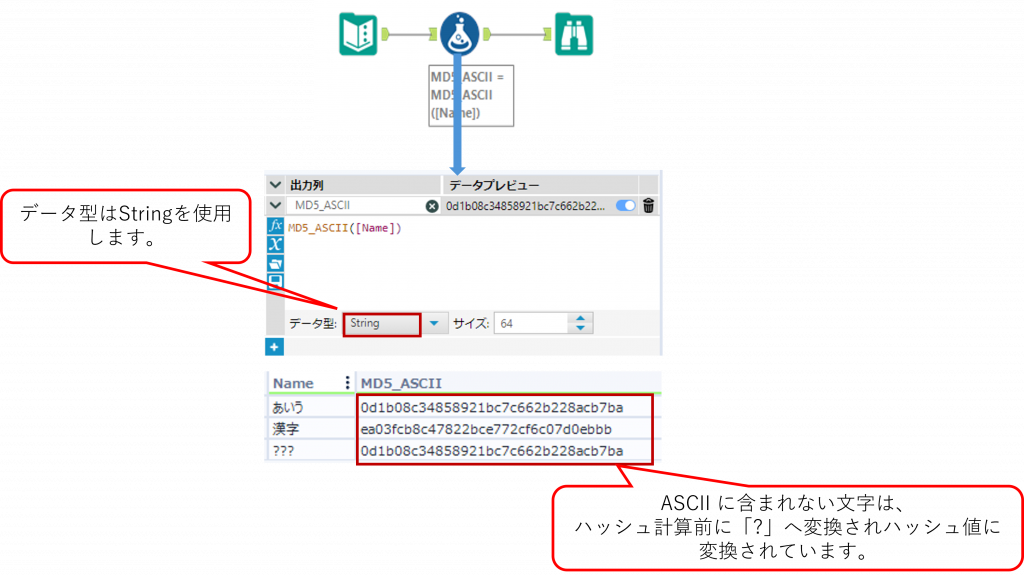
Sample2
下の例では、日本語や全角文字など ASCII に含まれない文字を入力した場合に、文字列が ハッシュ計算前に内部的に「?」へ変換され、その結果を基に MD5 のハッシュ値が生成されることを示しています。入力のフィールドの値自体は変更されませんが、ASCII に含まれない文字を内部的に「?」へ変換してハッシュ計算を行っています。この処理は String 型の文字列を ASCII として扱うことを前提としているため、Unicode を前提とする W_String 型には使用できません。
補足
MD5 は大文字・小文字・空白の違いを区別して処理します。そのため、入力文字列が異なる場合は、生成されるハッシュ値も異なります。
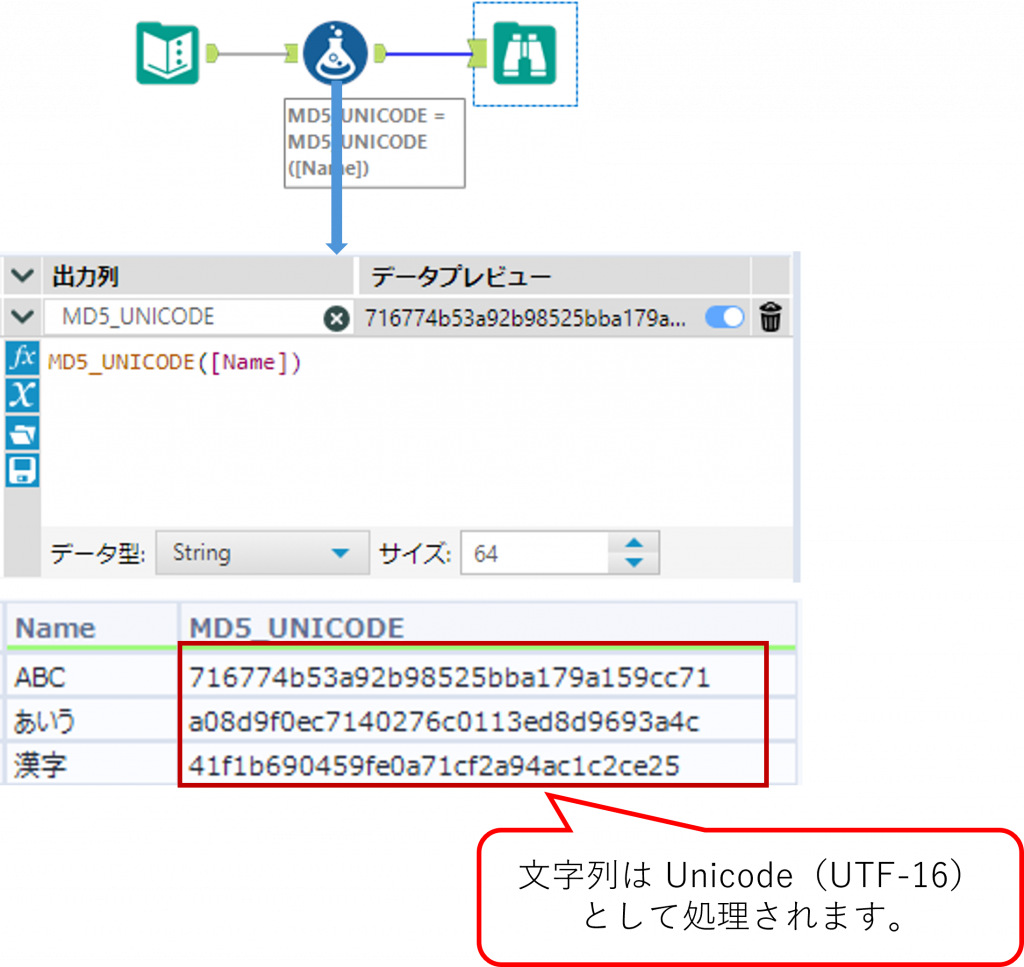
MD5_UNICODE ・・・Unicode 文字列から MD5 ハッシュ値を生成
MD5_UNICODEMD5_UNICODE は、UTF-16(Unicode)で保持されている文字列を対象に、MD5 のハッシュ値を返します。
Sample
下の例では、半角文字列および全角文字列を Unicode(UTF-16)として処理し、MD5_UNICODE によりハッシュ値を生成しています。
Unicode として文字列を扱うため、同じ「ABC」であってもMD5_ASCII とは文字の扱いが異なり、生成されるハッシュ値は異なります。また、日本語を含む文字列も変換されることなく、そのまま処理されます。
MD5_UTF8 ・・・UTF-8 文字列から MD5 ハッシュ値を生成
MD5_UTF8UTF-8 形式の文字列を入力として、MD5 アルゴリズムによるハッシュ値を返します。
Sample
下の例では、「ABC」「あいう」「漢字」を入力し、文字列を UTF-8 として処理した場合に生成されるMD5 のハッシュ値を示しています。

補足補足(比較例)
下の例は、「ABC」「あいう」「漢字」「???」を入力した場合のMD5_ASCII、MD5_UNICODE、MD5_UTF8 の結果を比較したものです。
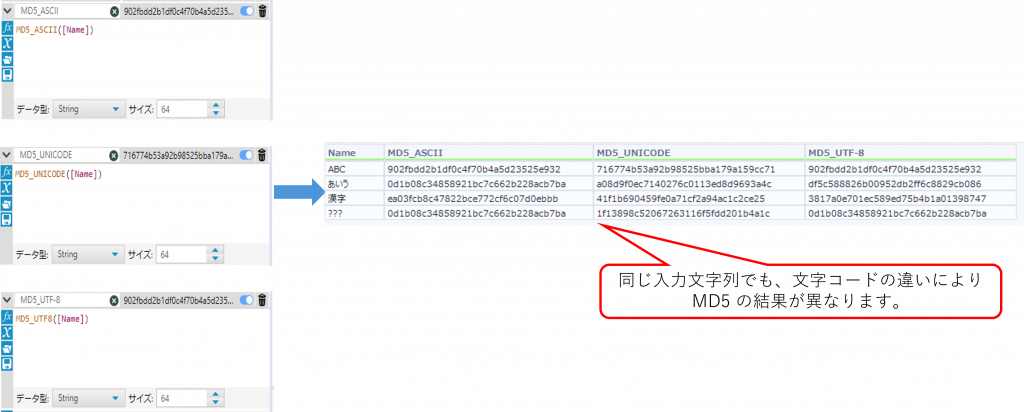
この比較から、文字コードの違いによりMD5 の結果が変わることが分かります。MD5_ASCII は全角文字を「?」に置換して処理しますが、
MD5_UNICODE と MD5_UTF-8 は文字列をそのまま扱います。そのため、日本語や漢字を含む場合は、関数ごとに異なるハッシュ値が生成されます。
サンプルワークフローダウンロード
Formula_Function_String fa-download
※Alteryx Designer 2025.1.2時点の情報です










