 運営会社
運営会社
Wordファイル(docx)に含まれているテーブルのデータをAlteryxで抽出する方法を紹介します
Microsoft Wordファイルに含まれているテーブルデータを抽出したいことがあると思いますが、本記事ではAlteryxでそれを行う方法をご紹介します。
Wordファイル(docx)は内部的にはXMLファイルなので、一度ZIP形式にして解凍後、出てきたXMLファイルを解析してテーブルのデータを取得する方法もありますが、正直なところ、ZIP解凍して、出てきたファイルを読み込んで、とステップも多いですし、XML解析する手間も考えると正直面倒なので、Pythonツールを使って行いたいと思います。
入力ファイル
入力ファイルとしてはこのような適当なファイルを作ってみました。
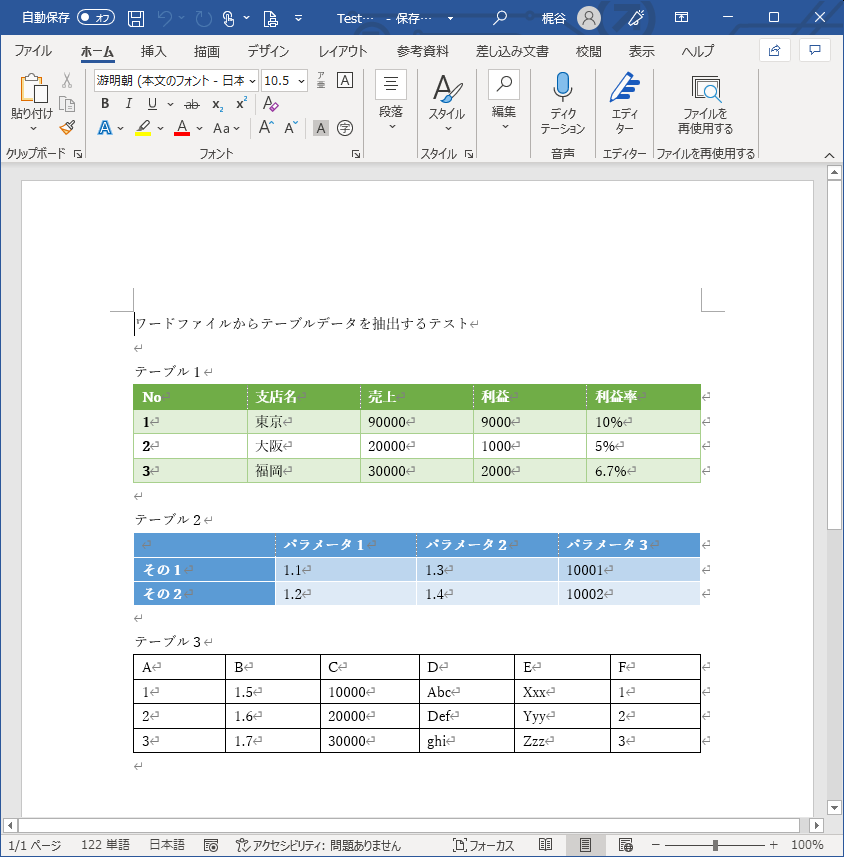
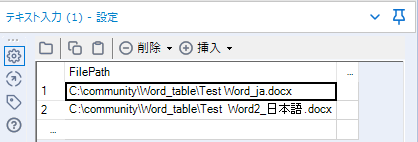
このようなファイルを今回は2つ用意し、テキスト入力ツールに入れておきます。
PythonPackageの事前準備
それでは、今回はPython-docx fa-external-linkというライブラリを使用していきます。
パッケージのインストールは、普通にAlteryxのデフォルトの機能で可能です。実際のやり方としては、PythonツールのJupyter Notebookにて以下のコードを入力し、実行します。
Package.installPackages(['python-docx'])
これでエラーが出なければOKです。
一度実行すれば、パッケージがPCにインストールされるため、以下のようにコメントアウトを推奨します。
#Package.installPackages(['python-docx'])
コメントアウトしなくても、少し動作速度が遅くなるだけです。
Pythonコード
今回は、複数ファイルが来ても処理できるように、入力レコード数回ファイルパスを変えながら処理するコードになっています。
Python-docxパッケージは、Document関数にファイルパスを指定することでdocxファイルを読み込み可能です。
document = Document(filepath)
テーブル要素を抜き出すにはtablesを参照します。
tbl = document.tables
テーブルが取得できたら、行ごとに抜き出します。これはrowsを参照する形になります。
row = tbl.rows
あとは各セルから値を取得したいのですが、さらにまだcellsを参照しなければなりません。
cell = row.cells
ようやくこれで値を取得できます。
value = cell.text
はい、これを実際にコードに落とすと以下のようになります。
from ayx import Alteryx
from docx import Document
import pandas as pd
#入力データをPython内に読み込み
df1 = Alteryx.read("#1")
lines=[] #出力用データ保存用
#ファイルごと、テーブルごとに読み込み実行
for index, files in df1.iterrows():
filepath = files['FilePath']
document = Document(filepath) #Wordドキュメント読み込み
tbl_num=0 #テーブルNo初期化
for tbl in document.tables:
tbl_num += 1
for row in tbl.rows:
values=[filepath,tbl_num]
for cell in row.cells:
values.append(cell.text)
lines.append(values) #出力用にデータを追加
#データ出力用にPandasフレームへ入力
df = pd.DataFrame(lines)
# データ出力
Alteryx.write(df,1)
Alteryxワークフロー
ここからAlteryx側に戻ります。
Pythonツールからのアウトプットは以下のようになります。
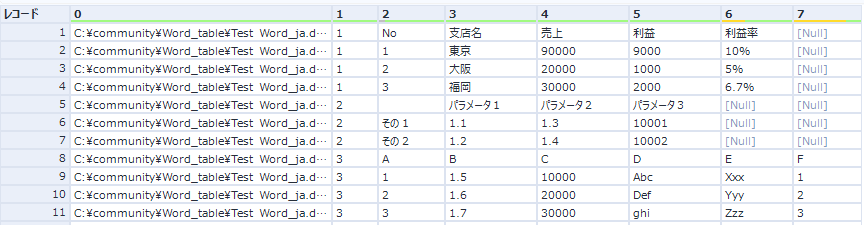
最初のフィールドは、ファイルパス、2つ目のフィールドは各ファイル内のテーブル番号になるので、それぞれセレクトツールで名前をつけておきましょう。その後の2以降のデータフィールドについては動的リネームで修正しましょう。
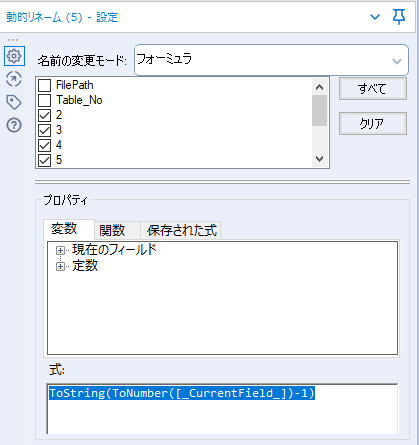
式:
ToString(ToNumber([_CurrentField_])-1)
最終的なWFは以下のようになります。
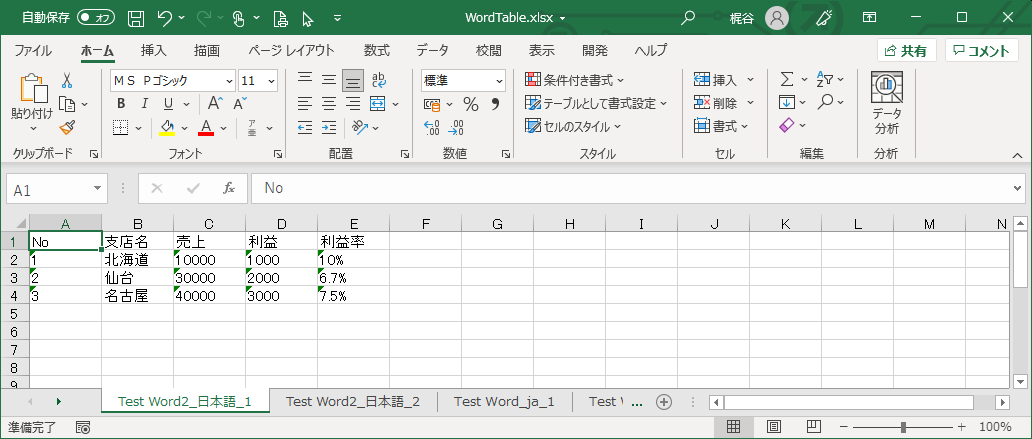
出力として2つのファイルで以下のようになります。
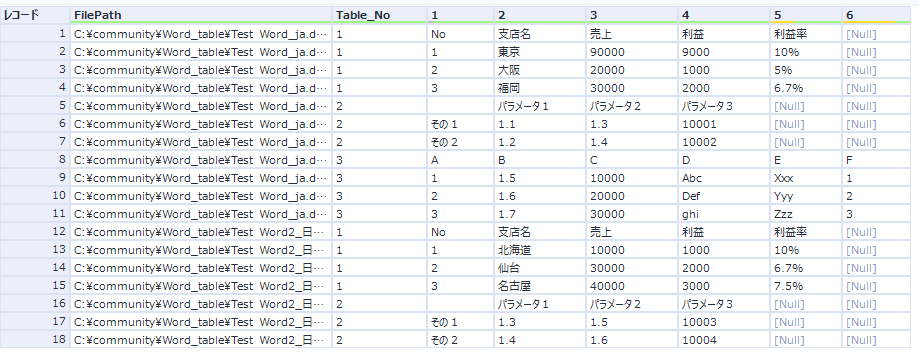
実際に中身を利用しようとすると、様々なケースが考えられますが、フィルタで個別のテーブルごとにデータストリームを分けていく形になるかと思います。
今回は、とりあえずExcelファイルにシートをわけて保存する方向で進めてみましょう。
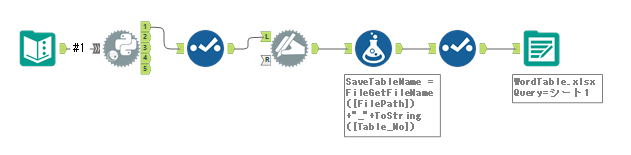
各テーブルごとにグループ化して保存する場合は、データ出力ツールの「フィールドからファイル/テーブル名を取得する」機能を使います。そのために、まずフォーミュラツールを使って各テーブルごとにグループを区別するフィールドを作ります。今回であれば、ファイル名とテーブル番号から作成することが可能です。ファイルパスをそのまま使うと長すぎるためファイル名を使いたいと思います。
FileGetFileName([FilePath])+"_"+ToString([Table_No])
これで、ファイル名+"_"+テーブル番号、のような形式になります。
データ出力ツールの設定は、以下の通りとなります。
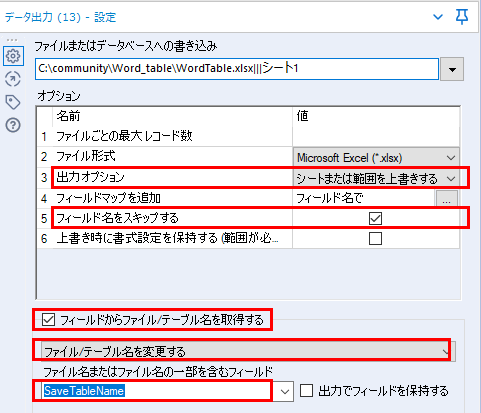
ポイントは、以下のとおりです。
- 出力オプション : シートまたは範囲を上書きする
一つのExcelに複数シートを書き込む場合は必須のオプションです。
- フィールド名をスキップする : チェックを入れる
このオプションを使うことで今回フィールド名がデータ行の中に埋まっているのを解決します。
- フィールドからファイル/テーブル名を取得する : チェックを入れ、「ファイル/テーブル名を変更する」に設定
今回必須のオプションです。「ファイル名またはファイル名の一部を含むフィールド」で指定したフィールドの値でグループ化されて保存されます。
最終のワークフローは以下のとおりです。
出力結果
最終アウトプットは以下のような形で各ファイルの各テーブルごとにシートをわけて保存されます。
サンプルワークフロー
Word_table_sample fa-download
※Alteryx Designer v2021.3.3.63061時点の情報です










