運営会社
運営会社
ThoughtSpotウェビナー「SpotMap」(2026年6月)についてご紹介いたします
AkimasaKajitaniです。本ブログ記事は、2026年にSpotMapという新たに始まったウェビナーシリーズの内容についてブログに書いているシリーズです。
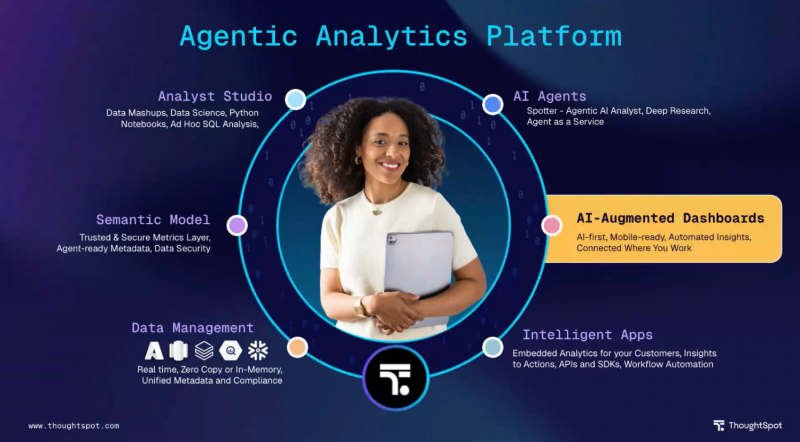
SpotMapウェビナーって何?
SpotMapウェビナーは、ロードマップをご紹介するウェビナーシリーズとなっており、毎月第一木曜日に開催されます。ThoughtSpotの製品分野として6つあり、年2回ずつ行われる、とのことです。
SpotMapへの登録はこちらのリンク からできます。
今回のアジェンダ
今回はとうとう・・・Analyst Studioについてです。
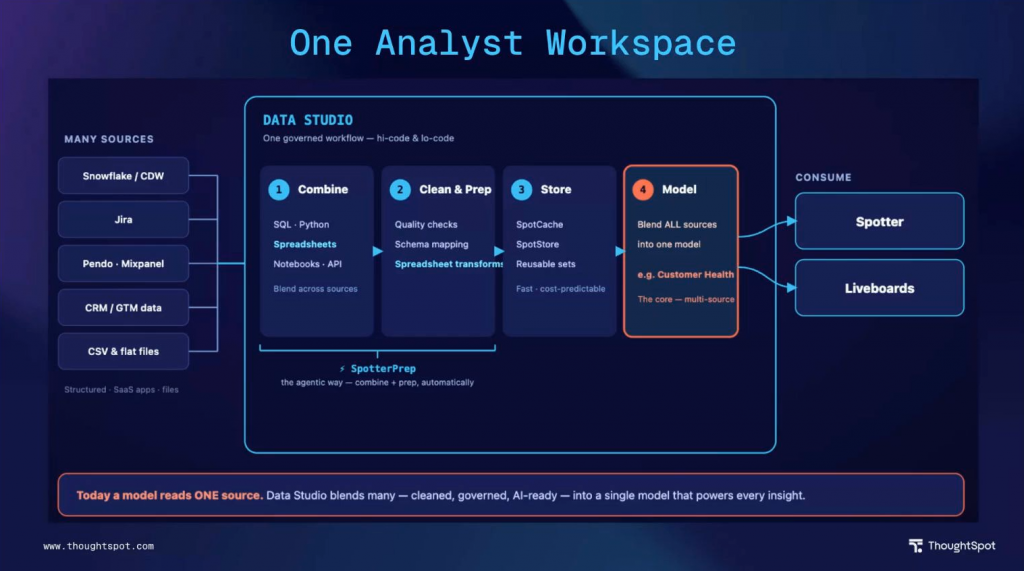
どうやら、そもそもAnalyst Studioという名称が変わるのか、上のスライドではData Studioという名称が登場しています。
このData Studioは、様々なデータソースからデータを読み込み、SQL、Pythonノートブックなど、さらにはスプレッドシートスタイルでデータを加工し、SpotCacheに保存することで、ThoughtSpotエコシステムで利用する、という流れになります。
そしてこのデータ加工の部分はSpotterPrepというものが利用できるようです。
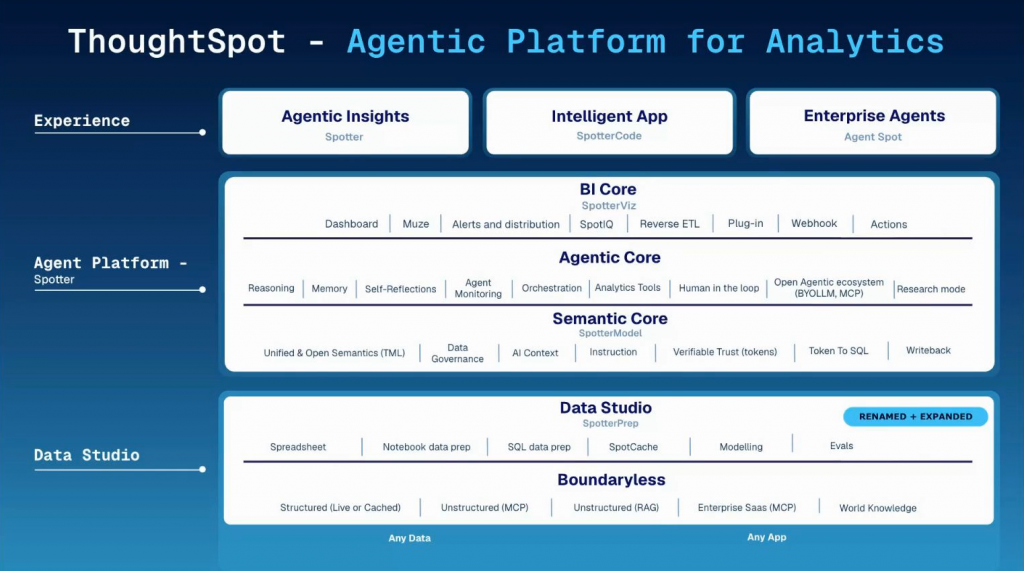
さて、このスライドは、Data StudioがThoughtSpotエコシステムのどこに位置づけられるのか、を示したものになります。ウェビナーの内容によると、
Data Studio は、エンドツーエンドのアナリストの作業全体をサポートするプラットフォームであり、スプレッドシート、ノートブック、データ保存用の SQL ストレージ、スポットキャッシュ、モデリング、評価など、データ内で設定したいあらゆるコアデータ運用ツールを提供します。
とのことです。ThoughtSpotの検索やSpotterで分析するにも、根幹となるデータ、これを準備するのがData Studio、ということになります。
さて、こちらのスライドでは現在できることと、直近の追加機能が表現されています。

一つはデータマッシュアップといっていますが、複数のデータソースからクロスソース結合ができる、ということです。Snowflake、Databricks、BigQueryだけではなく、Cloud版のExcel、SharePoint、OneDriveなどにあるExcelなど、あらゆるデータを取り込むことができます。CSVデータももちろん取り込めます。その他のデータベースなども利用可能です。
ここからはデモが行われ、複数のデータソースからデータを取り込むデモが行われています(動画13分あたり)。
デモの中では、Snowflakeから読み込んだ一つのテーブル(SELECT * FROM tablename)をいったんデータセットとして保存します。次に、Google Sheetsにある別のデータを取り込みます(これは一つのデータセットになります)。さらに、Slackから入手したCSVファイル(ローカルデータ)をData Studioにアップロードします。これでまたデータセットが作成されます。全部でこれで3つのデータセットができたわけです。
次に、Use a Datasetというメニューから3つのデータセットを読み込んでおきます。動画からスクショしたのですが解像度が悪くて見にくいのですが、左のメニューに三つのデータがあることがわかります(画像が荒くて申し訳ないです)。
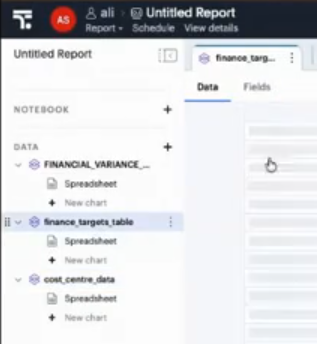
ここからQueryデータセットを作成します。それぞれのデータセットは特に元のデータソースがなんであれ(今回はCSVファイルとGoogle Spreadsheet、そしてSnowflakeです)、いずれもSELECT文でJOINすることができます。
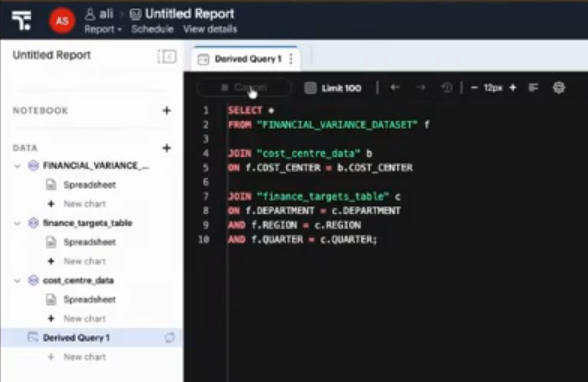
通常、データソースが異なると一つのSQL文の中に書けないのですが、これはすばらしいですね。
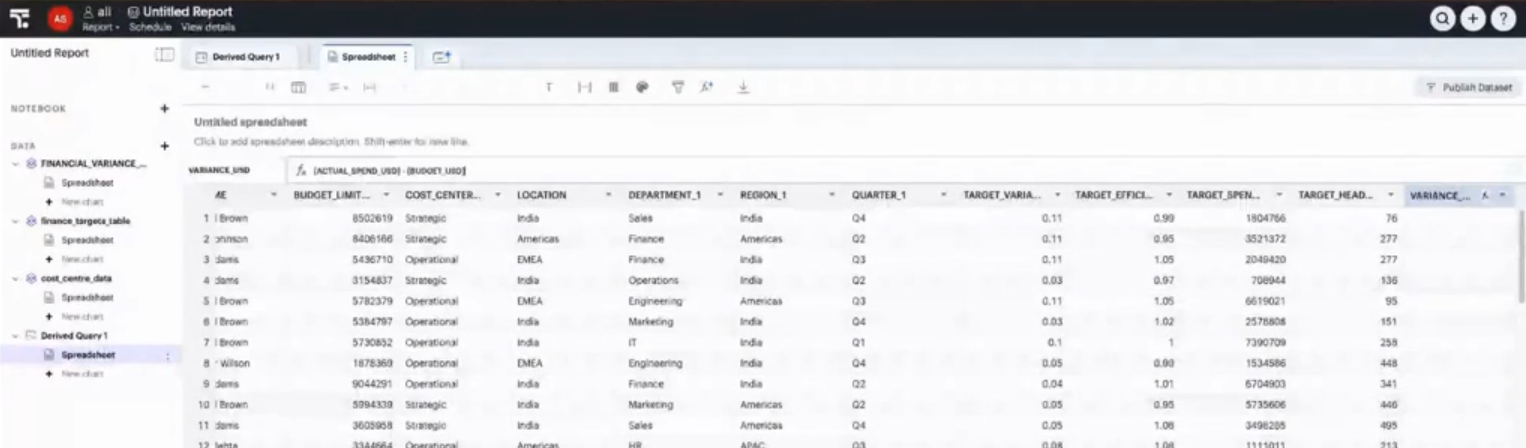
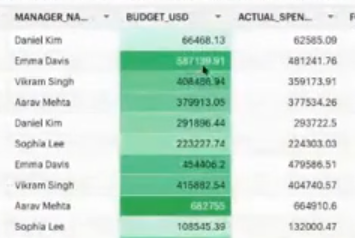
さらに、これはスプレッドシートスタイルで閲覧することができます。そしてこのスプレッドシートスタイルの中ではGUIを使ってデータを加工することができます。
例えば、右端の列は新しく作成したものですが、数式(ここでは単なる引き算ですね)を入れて項目を作成しています。
関数も色々とあるようです。IF文なども使えます。
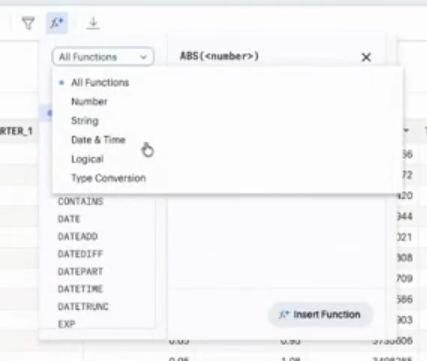
また、フィルターなどもかけられます。
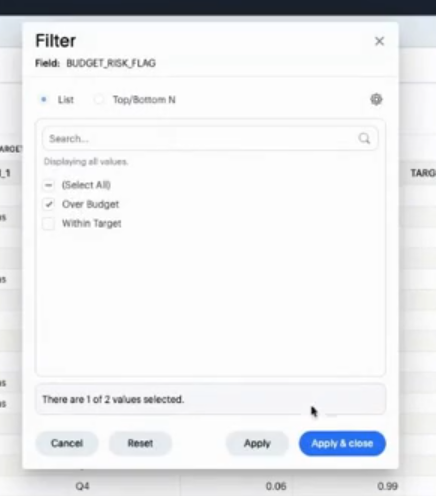
さらには、色をつけたりも出来ます。
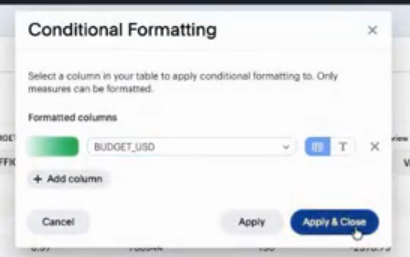
このような感じでデータセットが完成したら、ThoughtSpotにパブリッシュするということになります。
次に、ここまでは従来のやり方でしたが、今はAIの時代です。AIを使ったモダンな方法もできるようになっています。

ここからはまたデモとなります。ThoughtSpotのモデルの画面にあるQualityというタブが最初に提示されました。
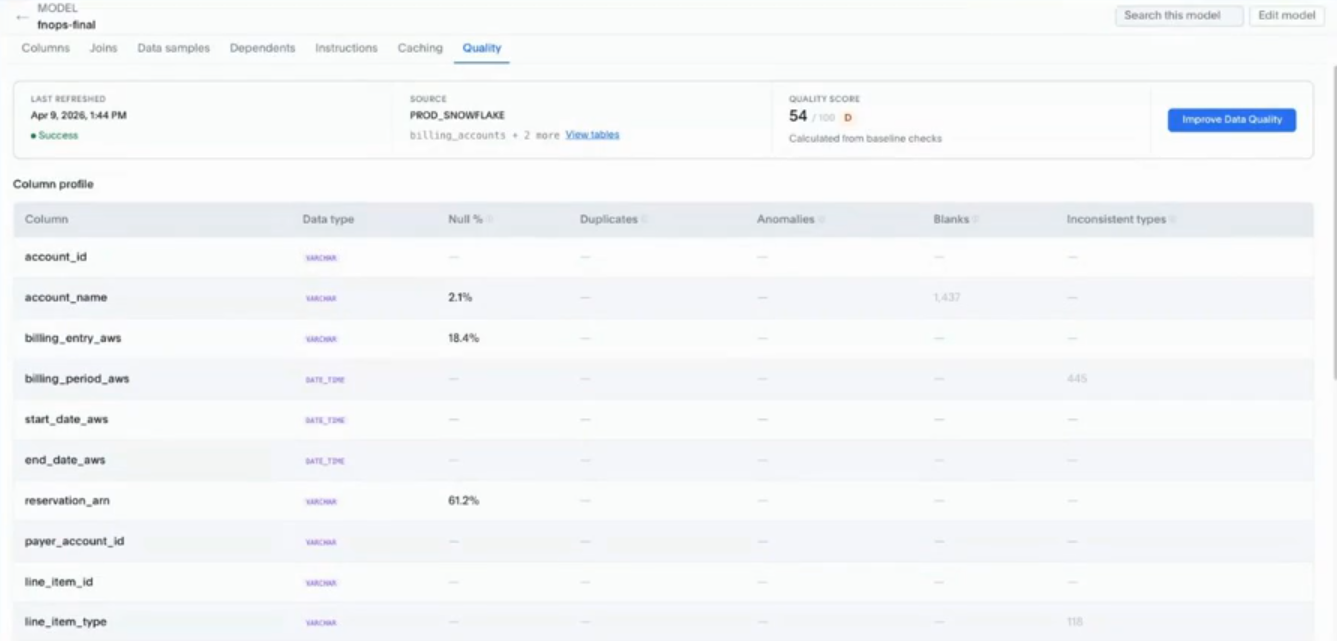
ここでは、クオリティスコアというものと、各カラムにどれくらいNullがあって、空白があって、というのをサマリーしていて確認できます。この右上の青い「Improve Data Quality」をクリックすると、以下のような画面になります。
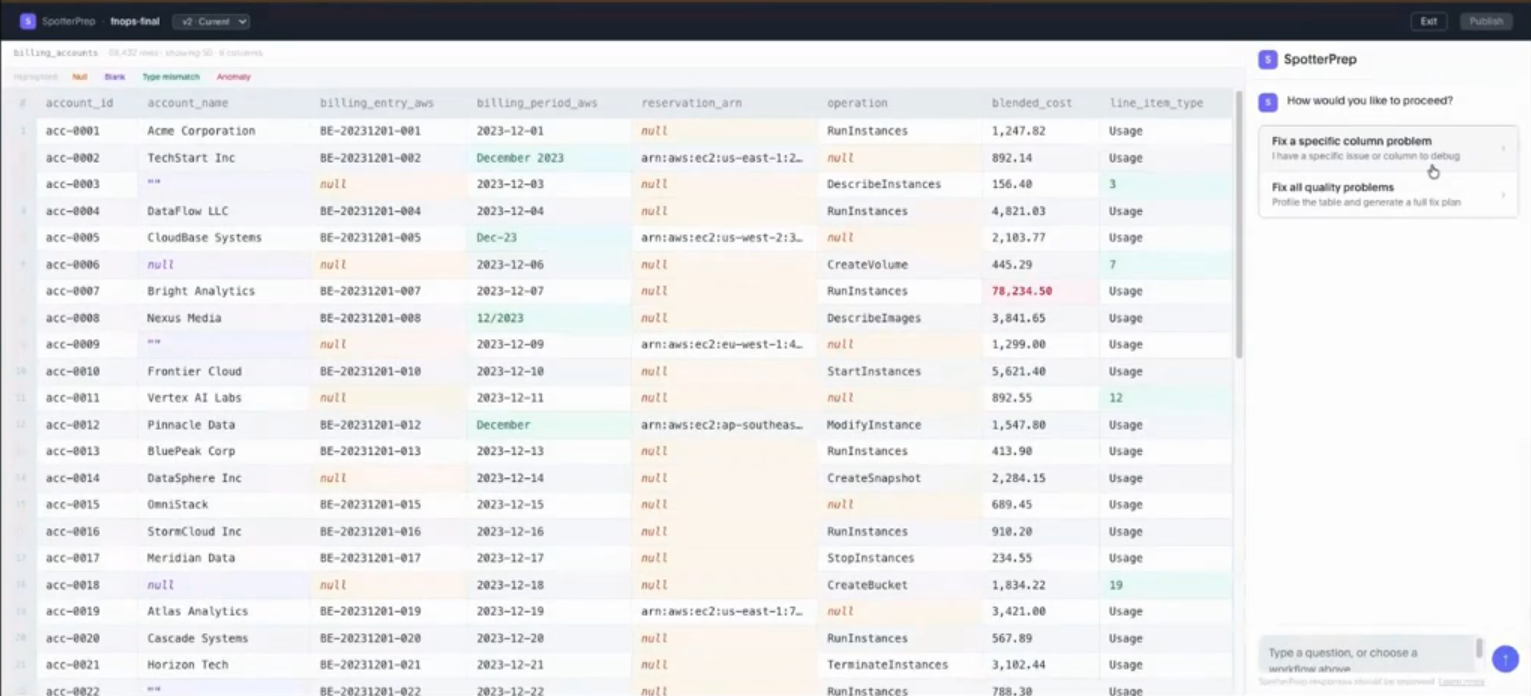
SpotterPrepのチャットウィンドウで、「Fix all quality problems」をクリックすると自動的に処理が始まります。
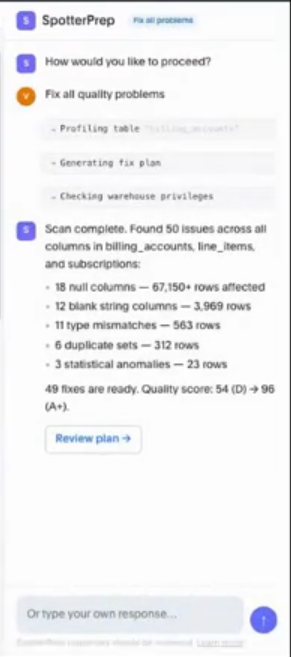
実際にどのような処理をするか、というのを確認できます。
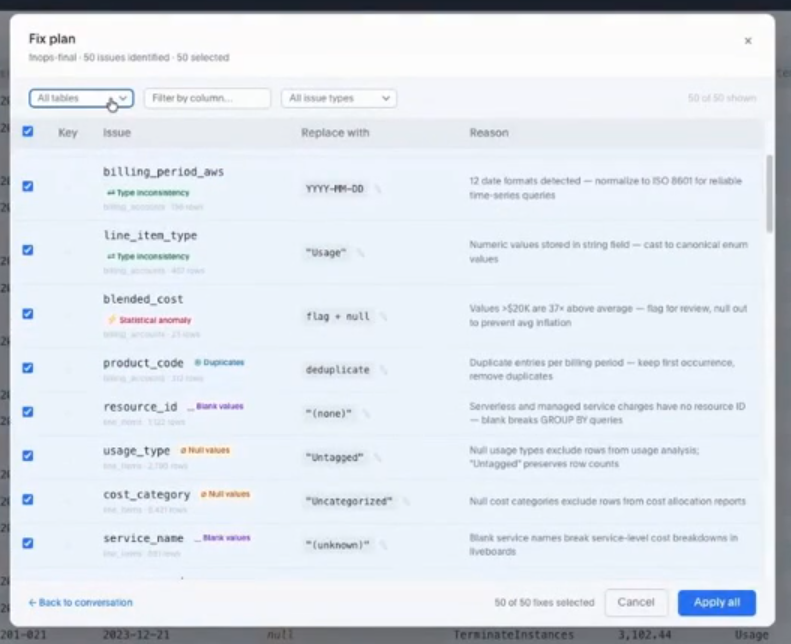
これによって、品質スコアは91まであがりました。
さて、ウェビナーの話は価格的なところに向かいます。

以前に比べてキャッシュできる容量は大きくなりました。以前は組織ごとに100Gでしたが、大きく改善されているとのことです。データ加工はもちろんですが、DWHの費用を抑えるためにキャッシュすることもできます。キャッシュすればいくらクエリを投げてもDWHの費用はかかりません。

さて、時代が進むにつれ、技術的なものとビジネスの距離が縮まっており、それでもまだまだ技術とビジネスの間にはギャップがあります。ThoughtSpotとData Studioがこのギャップを埋める、ということです。このシステムにより、データ読み込み、複数データの結合、そして分析まですべてのデータ分析に関わるものを解決することができます。

また、「このスプレッドシートをライブデータ上で直接操作することはできますか?」という質問が多くでているようで、「さらにそのデータを書き戻すことも考えられますが、現在これらは開発中」とのことです。
デモの中では、ThoughtSpotの検索画面から、Spreadsheetタイプの画面にそのまま切り替えて動作していました。
その他、元のスライドに戻り解説が追加されています。
- Native Spreadsheetsはすでにアーリーアクセス
- 組織ごとのサイズも100Gになっています。
- データセットごとのサイズも15Gになっています。
- SharePointやOneDriveに保存されているデータも統合可能
また、Analytics StudioをData Studioとして統合し、ThoughtSpot内で完全なアナリストワークフローを実現するのが最も重要としています。
また、ライブデータに基づいたスプレッドシートの提供、そして、書き戻し機能も利用可能になる予定です。
コーディングの軽減のために、SpotterPrepが利用できるようになります。また、自然言語を用いたAIコーディングも導入されるようです。
まとめ
Analyst StudioがどこまでThoughtSpotに統合されるのかわかりませんが、かなりシームレスに使えるようになっていくような方向性があるように感じました。確かに、わざわざThoughtSpotから離れてAnalyst Studioを起動するより、ThoughtSpotの中ですべての作業ができると便利ですよね。
また、スプレッドシート型のインターフェースによりライブクエリデータの加工もなかなか刺激的です。さらに書き戻しもできるようになるとほぼパーフェクトな形になるような気がします。