 運営会社
運営会社
Alteryxツールアイコン「正規表現ツール」(Regular Expression Tool)をご紹介します
 正規表現ツール(Regular Expression Tool)
正規表現ツール(Regular Expression Tool)
[パース]カテゴリの[正規表現]ツールについて紹介します。
概要
このツールはPerl5正規表現を用いて、「置換」「トークン」「パース」「一致」の処理を実施するツールになります。
正規表現とは?
設定項目の説明の前に正規表現ツールを理解するために正規表現について簡単に説明します。
正規表現とは、「いくつかの文字列を1つの形式で表現する」方法です。メタ文字「.^$[]*+?|()」 を使用して様々な表現を行います。
基本的な正規表現について説明します。
任意文字 「.」
「.」は任意の1文字を表します。
例えば「私は.です」の正規表現と一致する文字列を検索すると
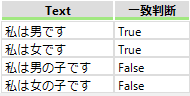
となります。「私は」と「です」の間が1文字でない「私は男の子です」、「私は女の子です」は一致しないと判断されます。これを「私は...です」の正規表現にすると任意の3文字となり
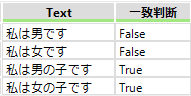
「私は男の子です」「私は女の子です」が一致と判断されます。
ゼロ回またはそれ以上の繰り返し 「*」
「*」は一つ前の文字をゼロ回以上繰り返すとなります。 「.」と組み合わせると任意の文字と表現できます。
「私は.*です」と表現すると以下の様になります。
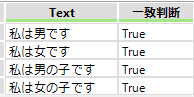
「私は*です」では「は」の繰り返しになりますので結果は以下の様になります。
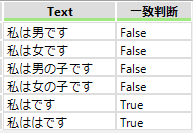
この時0回も含みますので「私です」も対象になります。
![]()
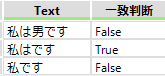
1回またはそれ以上の繰り返し 「+」
「+」 は1回以上の繰り返しになります。「私は+です」と表現すると以下の様になります。
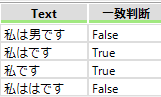
0回または1回の繰り返し 「?」
「?」は0回または1回の繰り返しです。「私は?です」と表現すると以下の様になります。
文字列の先頭 「^」
「^」 は文字列の先頭の文字を表します。「^私は.*」と表現すると「私は」で始まる任意の文字列になります。
文字列の最後 「$」
$は文字列の終わりの文字を表します。「.*です$」と表現すると「です」で終わる任意の文字列になります。

いずれかの文字列 「|」
「|」はorに当ります。「私です|私はです」と表現すると「私です」もしくは「私はです」に該当する文字列になります。
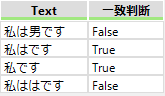
いずれかの1文字 []
[]で囲むと、いずれかの1文字となります。「私は[男女は]です」と表現すると「私は男です」「私は女です」「私ははです」となります
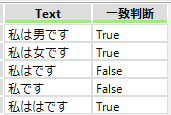
[]内で^を使用すると、先程説明した^の意味が変わります。「私は[^男女]です」と表現すると男もしくは女以外の文字となります。
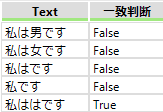
文字のグループ化 ()
()で囲むとグループとして判断されます。例えば「私は+です」だと「は」1文字を繰り返しでしたが、「(私は)+です」とすると「私は」を繰り返すに変わります。
基本的な正規表現は以上となります。その他にも応用的な表現が多種存在します。
設定項目
正規表現ツールの設定は、「対象フィールドの選択(パースするフィールド)」「正規表現」「出力メソッド」の3つに大きく別れます。
対象フィールドはプルダウンから選択します。
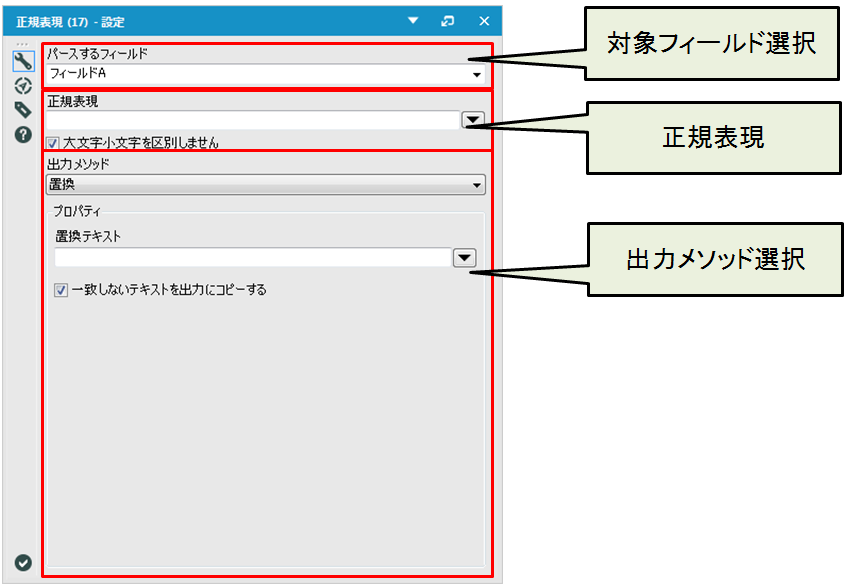
正規表現
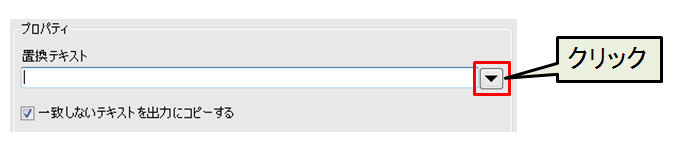
正規表現を入力する時は 右側の▼をクリックすると、入力補助がありますので利用して正規表現を作成できます。
出力メソッド
出力メソッドには4つの方法があります。
| 出力メソッド | 処理内容 |
|---|---|
| 置換 | 正規表現が一致した場合、指定したテキストに置換します。 |
| トークン | 正規表現に一致する部分に分割します。 |
| パース | ()で囲ったグループ正規表現に分割します。 |
| 一致 | 正規表現に一致するかを「true」「false」で出力します。 |
・置換
基本的な使い方として、置換後のテキストを入力するものになります。
サンプル:
| 正規表現 | 「.*男.*」(男という文字を含む) |
| 置換テキスト | 「一致します」 |
注意対象フィールドのサイズは変更されませんので、置換後テキストは対象フィールドのサイズ内であることが必要です。

「男」を含むTextが置換されました。このツールで置換する場合は「置換テキスト」の項目に設定された内容に置き換えになります。元のデータを置換後にも利用する場合は「グループ」を利用します。
マークを利用した置換
例えば先程の「.*男.*」を「(.*)(男)(.*)」にすると3つの「マークされたグループ」に別れます。
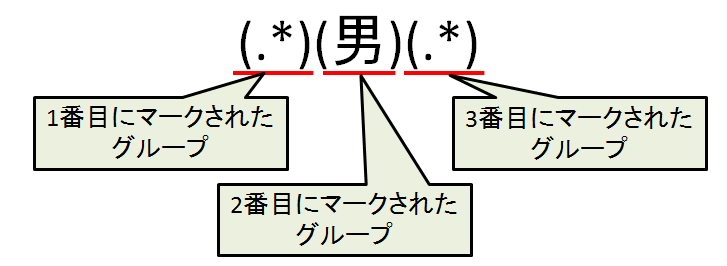
この「マークされたグループ」は置換テキストに含める事が可能です。「置換テキスト」の右端の▼をクリックすると次の補助メニューが開きます。

置換後のテキストに「$1」を指定すると、上の正規表現に該当するレコードが「1番目にマークされたグループ」に置換されます。
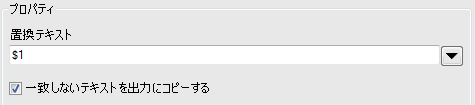
男を含むTextが「1番目のマークされたグループ」「私は」のみとなりました。

「マークされたグループ」と任意のテキストを組み合わせます。置換テキストを「$1父$3」としてみます。
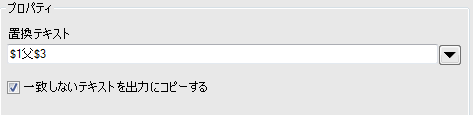
正規表現に一致した「私は男です」が「私は父です」に置換されました。

$& テキスト全文検索
$&は入力された「テキスト全文」を意味します。置換テキストを「[$&]は置換対象です」としてみます。
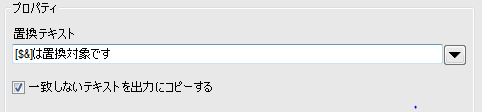
正規表現に一致した「私は男です」が置換されました。

$$ $キャラクター
置換テキストで「$1」など「マークされたグループ」として使っているため置換テキストで「$」の文字を使いたい場合は「$$」と表記します。

Text「100」が「$ 100」に置換されました。

・トークン化
正規表現に一致する部分に分割します。トークン化を選択するとプロパティが変化します。
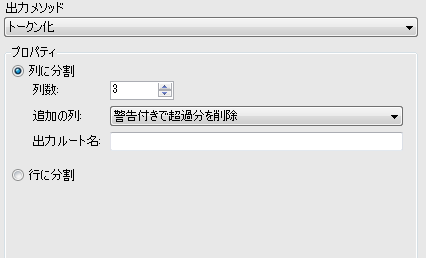
列に分割、行に分割については「テキストを列に分割」ツールをご参照ください。
このツールは正規表現に一致した部分で分割するわけではありませんのでご注意ください。
例えば正規表現を「は」として実行してみます。正規表現に一致するのは「は」の1文字ですので次の様になります。

また正規表現を「.」任意の1文字とすると文字列を1文字づつに分割できます。

・パース
()で囲んだグループ正規表現に分解します。パースを選択するとプロパティが変化します。
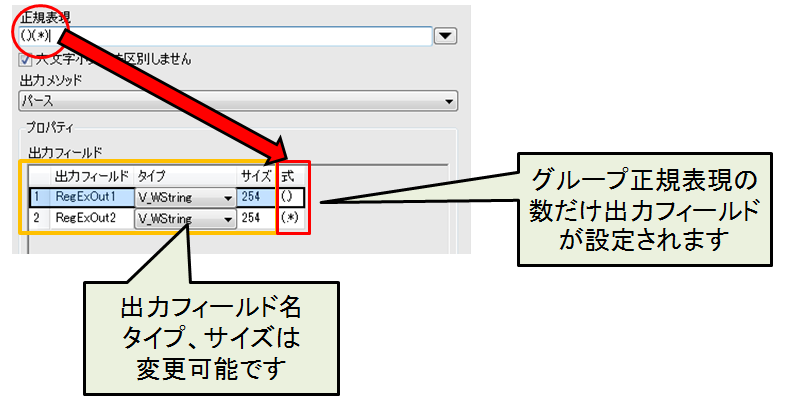
例えば「(.*)(は)(.*)」とすると、自動的に「(.*)」と「(は)」と「(.*)」の3つのフィールドに分割されます。

この時4レコード目の「ははは」の分割パターンは
①「は」「は」「は」
②「はは」「は」「空白」
の2つのパターンが考えられます。Alteryxで採用されるのはパターン②です。
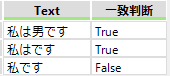
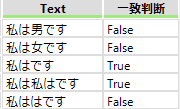
・一致
正規表現に該当するかを「True」「False」で出力します。一致を選択するとプロパティが変化します。
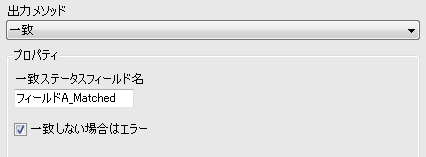
「True」「False」を出力するフィールド名を入力します。
例えば「(.*)(は)(.*)」で実施した場合次のようになります。
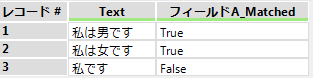
「一致しない場合はエラー」にチェックを入れると一致しないレコードが存在すると「結果」ウィンドウにエラーとして出力されます。
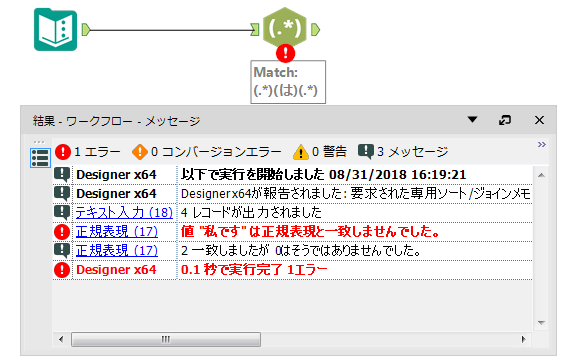
※Alteryx Version 2018.2.5時点での情報です










