 運営会社
運営会社
Alteryxで探索的データ分析を行う方法を紹介します。
こんにちは!ShintaroInomataです。
本記事では、Alteryxで探索データ分析を行うためのツールや方法を紹介していきたいと思います。
今回は、Kaggleで公開されているクレジットカード顧客のデータセットを加工したものを使用していきます。データセットの詳細はこちらから確認できます。
探索的データ分析とは
探索的データ分析(Exploratory Data Analysis:EDA)とは、データの特徴や構造を把握するために行う初期段階の分析手法です。統計的手法や可視化を通じて、データに潜むパターンや傾向、外れ値などを発見し、仮説の構築や後続の分析方針を明確にするために活用されます。
EDAでよく使われる主な手法には、以下のようなものがあります。
- 統計量の確認(平均値・中央値・分散など)
- 分布の可視化(ヒストグラム、箱ひげ図など)
- 相関関係の把握(散布図、相関係数など)
- カテゴリ別の傾向分析(棒グラフ、クロス集計など)
データのクリーニング
いざEDAを始めようとしても、データが整理されていなければ、正確な分析は困難になります。例えば、欠損値や不要な記号などが存在したままでは、正しい集計やグラフ化を行うことができず、分析の妨げとなる恐れがあります。
そこで活用したいのが「データクレンジングツール」です。このツールを使えばクリーニング作業を簡単かつ効率的に行うことができるので、まずはこのツールでデータを整えていきます。
データクレンジングツール
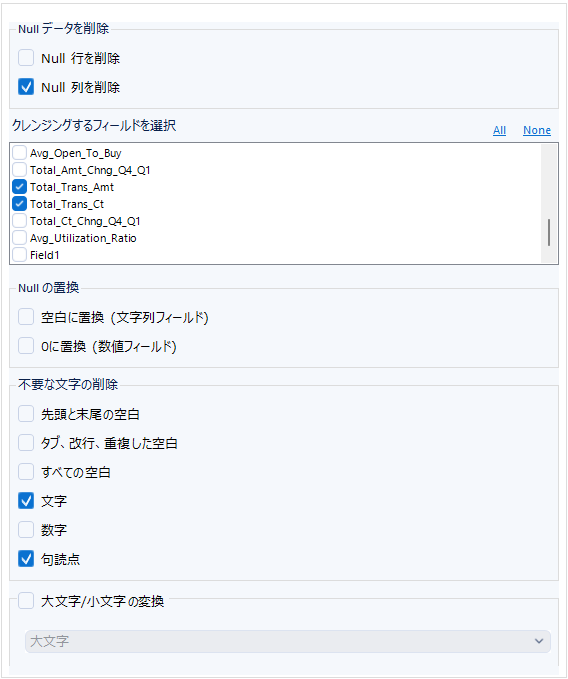
データクレンジングツールは、「準備」カテゴリの中にあります。

このツールのできることとして、
- Null行とNull列の削除
- Null値を文字列フィールドの場合は空白に、数値フィールドの場合は0に置換
- タブ、改行、空白、文字、数字、句読点の削除
- 大文字/小文字の変換
が可能です。
データを確認すると、「Total_Trans_Amt」は桁区切り付きの数値が格納されており、「Total_Trans_Ct」には数値であるべき箇所に不要な文字が混入しています。さらに「Field1」という不要なフィールドが含まれています。
このようなデータの不備は、実務におけるデータ分析では日常的な発生するもので、事前に適切なクリーニングを行わなければいけません。
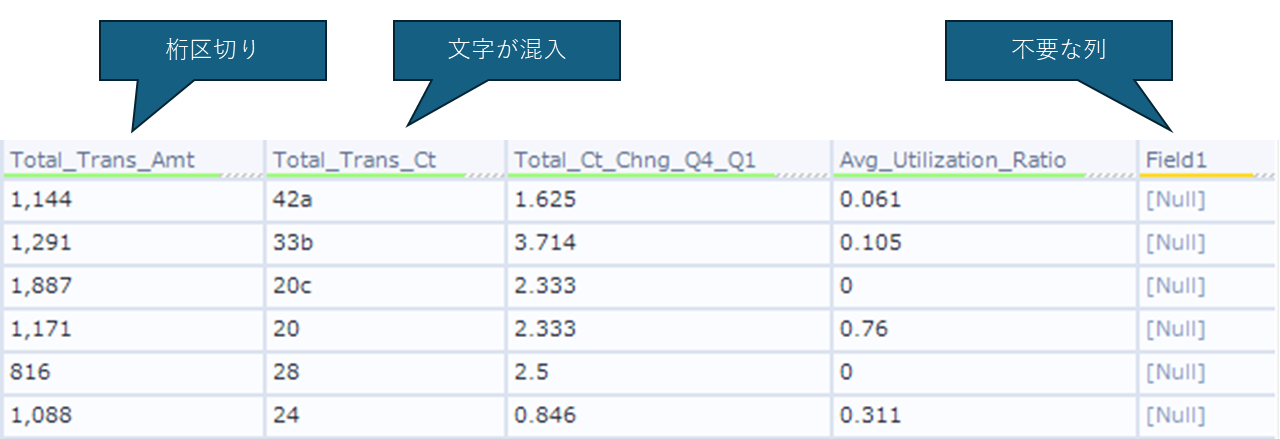
以下の画像がツールの設定画面です。
クレンジングしたいフィールドを選択して、取り除きたい要素をチェックボックスで選ぶだけです。
これで、不要なフィールドや要素を取り除き、データをきれいに整えることができました。
データの調査
次にデータの調査を行っていきます。具体的には、欠損値や外れ値の有無、統計量(平均値・中央値・分散など)などの確認が主な目的になります。
こうした情報を事前に把握しておかないと、後続の集計や可視化、機械学習モデルの構築において、誤った前提に基づいた分析を行ってしまう可能性があり、結果の信頼性が大きく損なわれてしまいます。
Alteryxの「データヘルスツール」と「フィールドサマリーツール」では、データの構造や品質を把握でき、問題のある個所をスムーズに発見することができます。
データヘルスツール
データヘルスツールは、「Machine Learning」カテゴリの中にあります。
※データヘルスツールは「Alteryx Intelligence Suite」に含まれるツールであり、標準のAlteryx Designerには含まれていないオプション機能です。
![]()
このツールは接続されたデータセット内の各フィールドの品質を自動で評価してくれます。特別な設定は必要なく、3つの出力が得られます。
ここでは、実際に入力したデータセットの結果を各出力ごとに確認していきます。
S出力
各フィールドごとに、「欠損値」、「一意性」、「外れ値」、「単一値」といった指標に基づいてスコアリングが行われます。また、合わせて推奨案も提示できます。
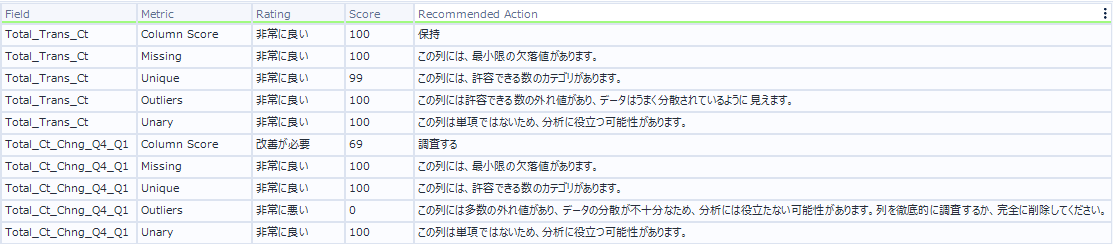
この後に使用する「Total_Trans_Ct」は、データ品質が「非常に良い」ことが確認できます。
R出力
Rアンカーに「閲覧ツール」を接続することでデータ全体の傾向を直感的かつ視覚的に把握することができます。
以下の画像がレポート結果です。

レポート結果から、今回のデータは全体的に品質が良いことが分かります。行単位・列単位の欠損値に関しては、いずれも健全性スコアが100%になっており、欠損値に関しての不安はなさそうです。一方で、外れ値の健全性に関しては、57%の列が「非常に悪い」と判定されており、外れ値に注意が必要なデータであることが読み取れます。
O出力
先ほどのR出力から、外れ値に注意が必要であることが分かりましたが、O出力ではさらに詳しく、外れ値のレコードIDやフィールド名、対象の値を教えてくれます。
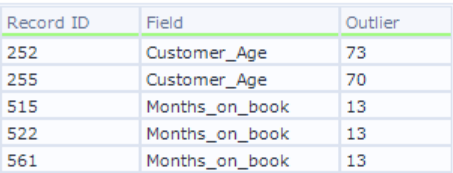
今回はこれらの外れ値に対して特別な処理は行いませんが、特定の機械学習モデルにおいては、外れ値がモデル性能に悪影響を与えることがあるため、必要に応じて別途対策を講じる必要があります。
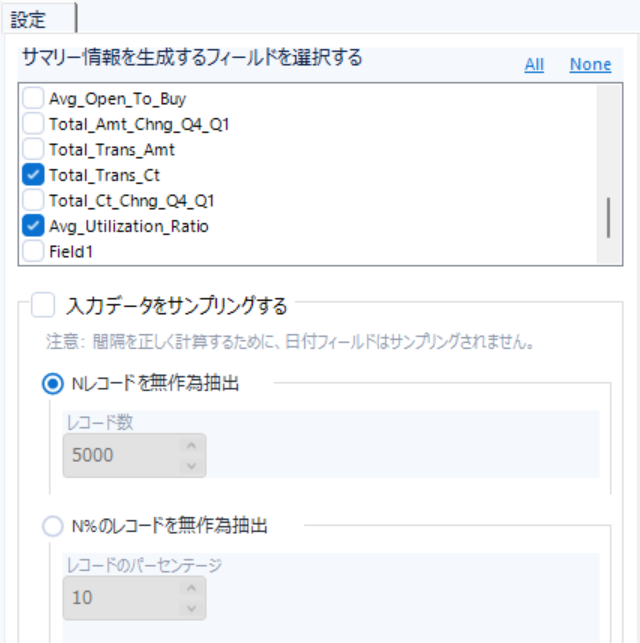
フィールドサマリーツール
フィールドサマリーツールは「データ調査」カテゴリの中にあります。

このツールでは、接続されたデータセットに対して、統計的な要約情報を自動で集計・可視化できるツールです。
主に以下のことが可能です。
- 基本統計量などの出力
- 一意性や欠損値の確認
- 散布図の確認(数値フィールドのみ)
このように、調査したいフィールドを選択するだけで準備は完了します。
以下の画像はR出力に「閲覧ツール」を接続して得られた結果です。テーブル形式で確認したい場合は、O出力で確認できます。
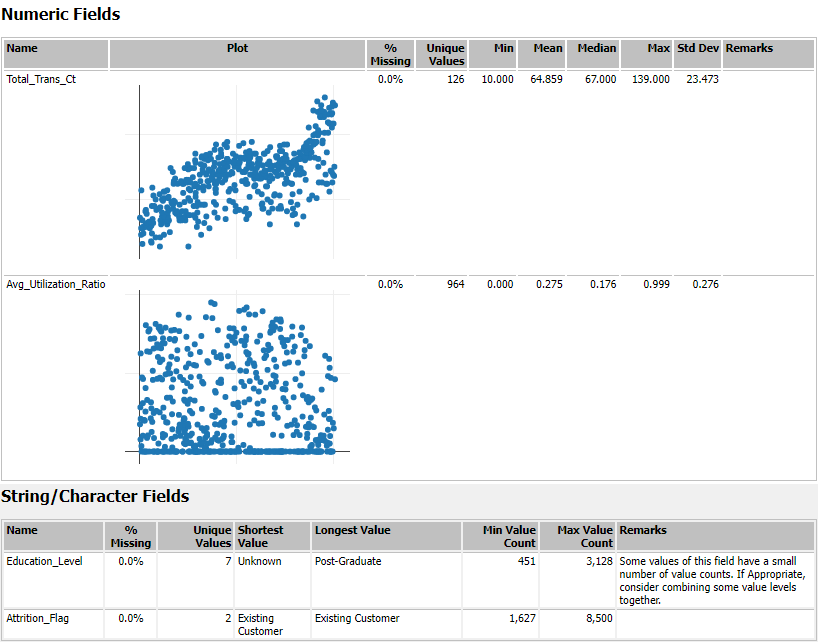
各フィールドの基本統計量や散布図を確認することができます。
また、見てわかるように数値型・文字列型など、フィールドのデータ型に応じて表示される内容が異なります。
データの可視化
最後にデータの可視化を行っていきます。
EDAでは、統計量だけではなく、グラフなどを用いた視覚的な確認も非常に重要です。
Alteryxの「散布図ツール」と「インタラクティブチャートツール」では、数値間の関係性やカテゴリ別の傾向を把握することができます。
散布図ツール
散布図ツールでは、「データ調査」カテゴリの中にあります。

このツールでは、2つの数値フィールドの関係性を可視化する散布図を作成することができます。これにより、相関関係や分布の傾向、外れ値の存在などを直感的に把握することができます。さらに、クラスターのようなグループ分けの兆候や、非線形な関係性の検出にも非常に有効で、データの構造を深く理解するのに役立ちます。
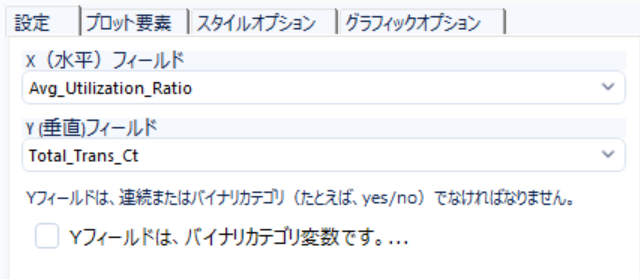
X軸に「Avg_Utilization_Ratio」、Y軸に「Total_Trans_Ct」を設定します。
「Avg_Utilization_Ratio」はクレジット枠の利用率、「Total_Trans_Ct」はクレジットカード取引の総数になります。
以下の画像が出力になります。
選択した2変数の散布図が作成され、項目名の隣には、それぞれの変数の箱ひげ図が表示されます。
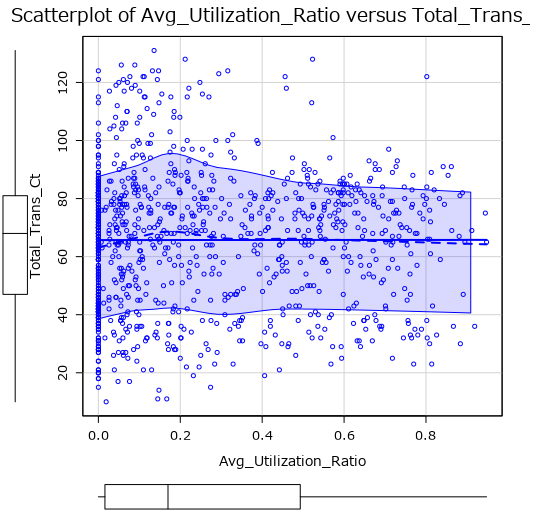
得られる示唆としては、以下のような傾向が見て取れます。
- 「Avg_Utilization_Ratio」の多くは0~0.2に集中しており、低利用率の顧客が多い
- 「Total_Trans_Ct」は30~90回にピークがあり、一部で100回を超える高利用者も存在
インタラクティブチャート
インタラクティブチャートツールでは、「データ調査」カテゴリの中にあります。

インタラクティブチャートでは、「棒グラフ」、「折れ線グラフ」といった様々なグラフを作成でききます。今回はその中でも、棒グラフを応用して、「100%積み上げ棒グラフ」を作りました。
インタラクティブチャートでの可視化や積み上げ棒グラフの作成方法は以下のサイトをご参照ください。

WeeklyAlteryxTips#73 インタラクティブチャートの積み上げ棒グラフに合計を表示する
以下の画像が作成した可視化結果になります。
横軸に「Education_Level」を、縦軸に既存顧客と離脱顧客の割合を示しています。これで各カテゴリにおける顧客の構成比を比較することができます。
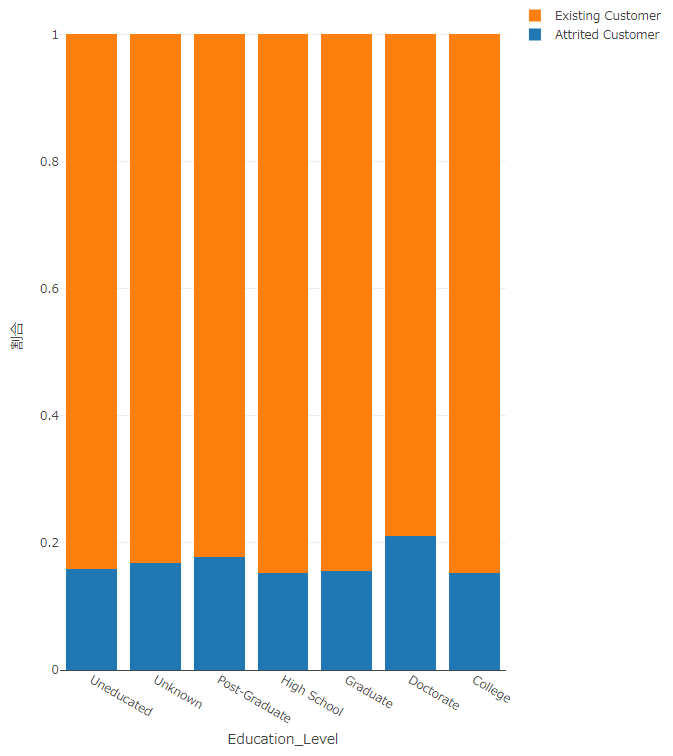
得られる示唆としては、以下の傾向が見て取れます。
- 「Doctorate」が最も解約率が高い
- 「College」や「High School」の解約率が低い
特に注目すべきは、「Doctorate」や「Post-Graduate」の解約率が意外と高いことです。これらの層は取れる選択肢が多く、より好条件のサービスを求めて離脱している可能性ががあります。一方で、「College」や「High School」層は、比較的安定した利用が見られ、長期的な顧客だと考えられます。このような考察は解約防止施策などの立案に活用できます。
まとめ
このように、Alteryxではコードを書かずに高度なEDAを手軽に行うことができます。
ぜひ皆さんも、お手元のデータを使ってAlteryxによるEDAを試してみてください!
参考記事とサンプルワークフロー
参考にしたAlteryxコミュニティ記事のURLになります。
今回使用したKaggleデータセットのURLになります。
Alteryxのサンプルワークフローになります。
※Alteryx Designer Version 2024.2時点の情報です。









