運営会社
運営会社
MeCabで手軽に形態素解析を行う方法をご紹介します
日本語のテキストマイニングを行う場合、一番ベーシックとなるのが形態素解析です。ここでは、AlteryxのPythonツールで利用できる形態素解析用のパッケージ「MeCab」を使う方法をご紹介します。
ところで、形態素解析といえば、MeCabです。ただ、以前はPythonやRから使う際もインストーラを使ってインストールを行う必要がありましたが、MeCab-Python3パッケージの出現により、別途インストールが不要となりました。これにより、手軽に形態素解析を始めることができるようになりました。
MeCab-Python3のパッケージのインストール方法
MeCab-Python3を使用する前に、Microsoft Visual C++ 再頒布可能パッケージのインストールが必要になります。これは、Microsoftのホームページからダウンロードし、インストール願います。
次に以下の一文をPythonツールのJupyterNotebookに記入します。これでMecab-Python3が利用可能です。
Package.installPackages(['mecab-python3'])
また、辞書が必要になるので、unidic-liteもインストールしましょう。unidicを使いたい、ということであれば、別途ローカルにダウンロードする必要があります。
Package.installPackages(['unidic-lite'])
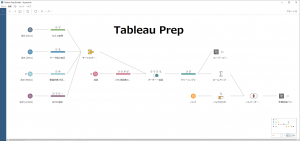
入力データとワークフロー
それでは、適当な例文にはなりますが、MeCabで形態素解析してみたいと思います。
「明日は目黒川で花見をします。」
ワークフローとしては以下のような形になります。

MeCabの使い方
まず、いちばん簡単な形でMeCabを使ってみたいと思います。Pythonのコードとしては以下のとおりです(パッケージのインストールなどは上で行なった通り実施済みとします)。
from ayx import Alteryx
import pandas as pd
import MeCab
#unidicを一度インストールしてしまうと、辞書のパス(-rオプションと-dオプション)を明示的に指定する必要があります
import unidic_lite
dic_path = unidic_lite.__path__[0].replace('\\','/') + '/dicdir/'
rc_path = unidic_lite.__path__[0].replace('\\','/') + '/dicdir/mecabrc'
mecaboption = "-r '" + rc_path + "' -d '" + dic_path + "'"
#MeCabインスタンス作成
mecab = MeCab.Tagger(mecaboption)
#データ読み込み
contents = Alteryx.read("#1")
#形態素解析処理実行
values = mecab.parse(contents.loc[0,'Field1']).splitlines()
#出力用にDataFrame作成
df = pd.DataFrame(values,columns=['MeCab output'])
# データ出力
Alteryx.write(df,1)
unidic_liteがインストール済みで、unidicをインストールしてなければ、mecaboptionを作成している5~9行目は不要です。unidicをインストールしている場合は、明示的に辞書のパスを指定する必要があるので、このようなコードを追加しています。
MeCabをインポート後、Taggerメソッドのインスタンスを作成します。この時、辞書のパスなどをオプションで渡すことができます。その後、parseメソッドでテキストを形態素解析することができます。
ただ、得られた結果は若干加工しないとそのままではAlteryxのワークフローに渡せません(Alteryxに渡すデータは、データフレーム型である必要があります)。その部分は、19行目です。
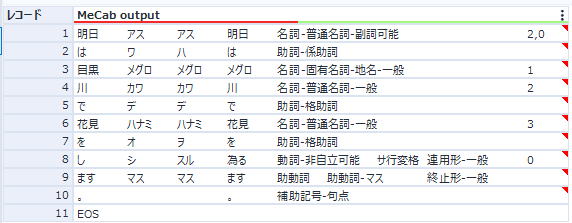
なお、parseメソッドで得られる結果は以下のような形になります。分かち書きされた各要素自体が改行コードで区切られているので、splitlines()メソッドで分割しています。その詳細はさらにタブ区切りで区切られています。そして最後になぜかEOSが入っています。
['明日\tアス\tアス\t明日\t名詞-普通名詞-副詞可能\t\t\t2,0',
'は\tワ\tハ\tは\t助詞-係助詞\t\t\t',
'目黒\tメグロ\tメグロ\tメグロ\t名詞-固有名詞-地名-一般\t\t\t1',
'川\tカワ\tカワ\t川\t名詞-普通名詞-一般\t\t\t2',
'で\tデ\tデ\tで\t助詞-格助詞\t\t\t',
'花見\tハナミ\tハナミ\t花見\t名詞-普通名詞-一般\t\t\t3',
'を\tオ\tヲ\tを\t助詞-格助詞\t\t\t',
'し\tシ\tスル\t為る\t動詞-非自立可能\tサ行変格\t連用形-一般\t0',
'ます\tマス\tマス\tます\t助動詞\t助動詞-マス\t終止形-一般\t',
'。\t\t\t。\t補助記号-句点\t\t\t',
'EOS']
今回はこのまま出力してみましょう。
それぞれタブ区切りとハイフン区切りをAlteryxで処理すると、以下のようになります。
実際のコード
複数行を読み込み処理を行うためのワークフローおよびPythonのコードは以下の通りとなります。さらにPython内でタブ区切りの分割までは済ませています。

from ayx import Alteryx
import pandas as pd
import MeCab
#unidicを一度インストールしてしまうと、辞書のパス(-rオプションと-dオプション)を明示的に指定する必要があります
import unidic_lite
dic_path = unidic_lite.__path__[0].replace('\\','/') + '/dicdir/'
rc_path = unidic_lite.__path__[0].replace('\\','/') + '/dicdir/mecabrc'
mecaboption = "-r '" + rc_path + "' -d '" + dic_path + "'"
#MeCabインスタンス作成
mecab = MeCab.Tagger(mecaboption)
contents = Alteryx.read("#1")
lines = [] #出力用データ保存用
i = 0 #レコードカウンタ(元の文章)
j = 0 #レコードカウンタ(分かち書き後)
for txt in contents['Field1']: #※1 ループ
j = 0
values = mecab.parse(txt).splitlines()
for value in values:
lines.append((str(i)+"\t"+str(j)+"\t"+value).split('\t'))
j = j + 1
del lines[-1] #最後のレコードは「EOS」のため削除
i = i + 1
df = pd.DataFrame(lines,columns=['Record_No','No','表層','発音','読み','原型','品詞','活用型','活用形','アクセント型'])
#dicrcファイルに記載のフォーマットで定義される(https://clrd.ninjal.ac.jp/unidic/faq.html)
# データ出力
Alteryx.write(df,1)
複数レコードが入ってきても処理できるように、ループを組んでいます(※1の部分です)。
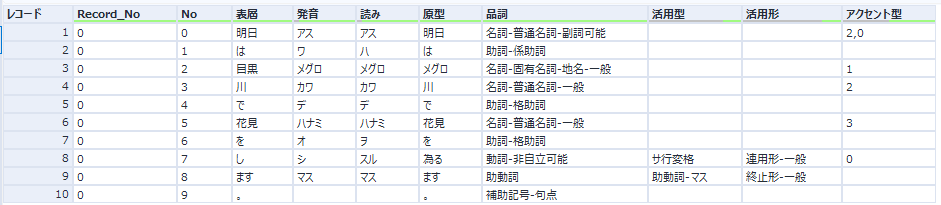
最終的な結果は以下のとおりです。

問題なく形態素解析が完了しています。
サンプルワークフロー
MeCab_python3_Sample fa-download
- MeCab-Python3基礎.yxmd ・・・ シンプルなバージョン
- MeCabを使う.yxmd ・・・ 複数レコードに対応したバージョン
参考URL
mecab-python3 fa-external-link
PythonでMeCabを動かそうとしたらmecabrc ファイルが無いというエラーが出たので原因を調べた fa-external-link
マクロ版

written by AkimasaKajitani