運営会社
運営会社
AlteryxでGoogle Cloud PlatformのCloud Natural Language APIを使って日本語のテキストマイニングを行う方法
Alteryxで日本語のテキストマイニングを行うにあたり、一番手軽な方法はGoogle Cloud PlatformのCloud Natural Language APIを使う方法かと思います。Cloud Natural Language APIは有料ではありますが、5,000ワードまでは無料で利用することが可能です。
Cloud Natural Language APIで何ができるの?
それではCloud Natural Language APIで何ができるのか、箇条書きにしてみます。
- 感情分析(Sentiment Analysis)
- エンティティ分析(Entities Analysis)
- エンティティ感情分析(Entity Sentiment Analysis)
- 構文解析(Syntax Analysis)
- コンテンツの分類(Classifying Content)
※ GCPの入門ガイド fa-external-linkより
感情分析(Sentiment Analysis)
文章がポジティブ(肯定的)かネガティブ(否定的)かニュートラル(肯定的でも否定的でもない)かを判断することができます。
口コミの評価やSNSの書き込みなどが肯定的か否定的かというのを分析することができます。
エンティティ分析(Entities Analysis)
文章に、既知のエンティティ(著名人やランドマークなどの固有名詞)が含まれているかどうか調べ、それに関する情報を返します。
エンティティ感情分析(Entity Sentiment Analysis)
感情分析とエンティティ分析を合わせた結果が取得できます。
構文解析(Syntax Analysis)
文章を一連の文とトークン(単語)に分解し、トークンについては言語情報が取得できます。いわゆる形態素解析が可能です。
コンテンツの分類(Classifying Content)
文章から何に対して書かれた文章か判断し、コンテンツのカテゴリを出力します。例えば、映画について書かれていれば「Movies」、ソフトウェアについて書かれていれば「Software」などと判別可能です。カテゴリのリストはGoogle社のドキュメント fa-external-linkに記載されています。
ただし、残念ながら2022年3月時点で日本語は未対応です。
APIの使い方
ダウンロードツールに対して、各APIのエンドポイント(URL)を設定し、分析したい文章をJSON形式で渡すことで利用できます。ダウンロードツールに設定する必要があるものは以下のとおりです。
- URL:APIのエンドポイントのURLとAPIキー
- ヘッダー:Content-Typeの設定
- ペイロード:分析したい文章をJSON形式で
今回は、感情分析を例に見ていきたいと思います。ちなみに、Cloud Natural Language APIはほぼどれも同じ使い方で、エンドポイントのURLが異なるくらいの違いしかありません。
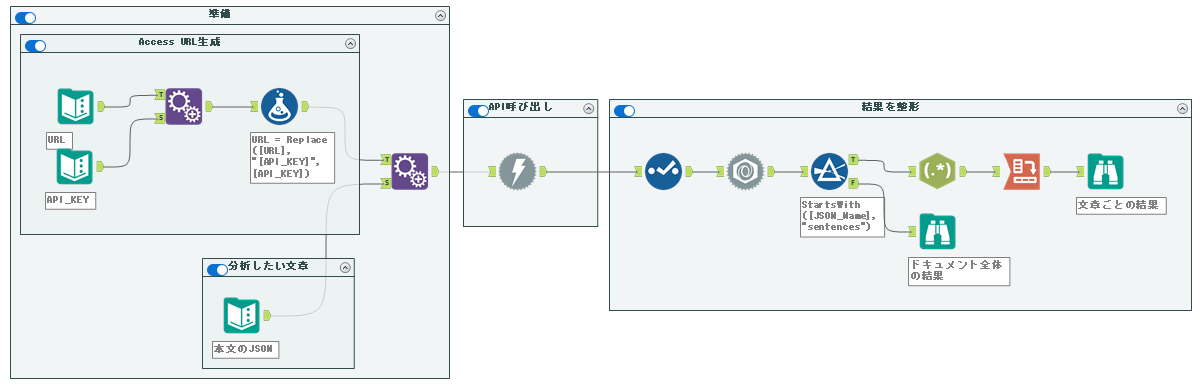
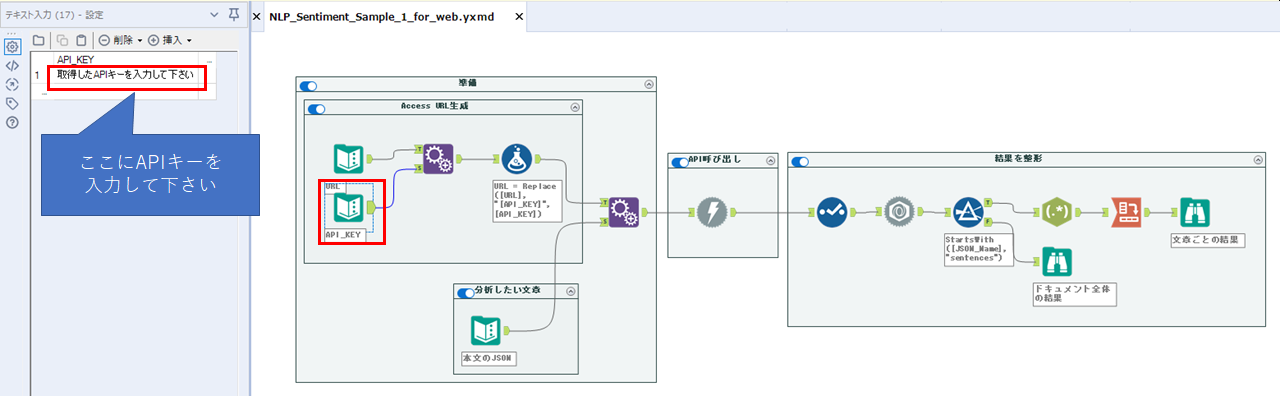
なお、実際のワークフローとしては以下のような形になります。
URL
URLは各APIごとに異なります。感情分析のドキュメント fa-external-linkを見てみると、以下のようにコードのサンプルが書かれています。
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
--data "{
'encodingType': 'UTF8',
'document': {
'type': 'PLAIN_TEXT',
'content': 'Enjoy your vacation!'
}
}" "https://language.googleapis.com/v1/documents:analyzeSentiment"
これは、curlという簡単にRestAPIを使えるようにしたコマンドラインツール用のコードです(curlはもともとLinuxでよく使われていましたが、Windowsも10から標準で入っています)。
上のソースの一番下にURL(https://language.googleapis.com/v1/documents:analyzeSentiment)が書いてありますが、これが感情分析のAPIのエンドポイントです。
実際にセットするURLとしては、APIキーを含める必要があるので、以下のようになります。
https://language.googleapis.com/v1/documents:analyzeSentiment?key=[ABC123...]なお、この最後の[ABC123...]というところはAPIキーが入ります。APIキーの取得はGoogleのドキュメント fa-external-linkを参照してください。
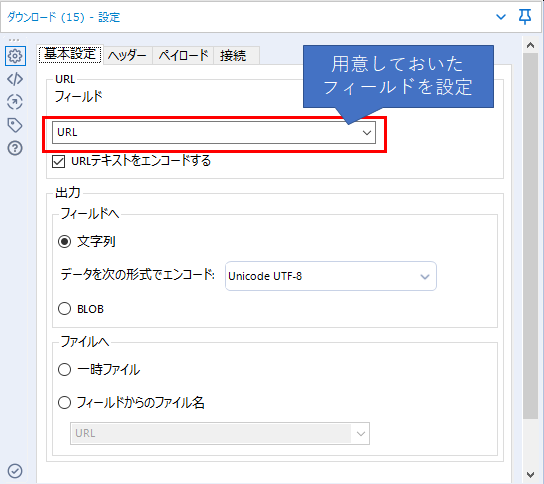
ダウンロードツールの設定では、URLはフィールドとしてあらかじめ用意しておき、基本設定タブのURLのところで用意したフィールドを選択します。
ヘッダー
上のcurlのソースで「H」から始まっているのがヘッダーです。つまり以下の部分です。
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
1行目は、「Authorization: Bearer」とあるので、認証部分になりますが、今回はAPIキーを使っているので省きます。
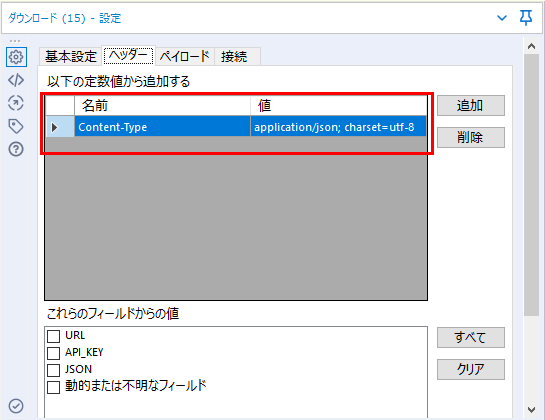
2行目はContent-Typeで、これはこのまま同じようにダウンロードツールにセットします(ヘッダータブにて追加ボタンをクリックし、名前と値を入力します)。
ペイロード
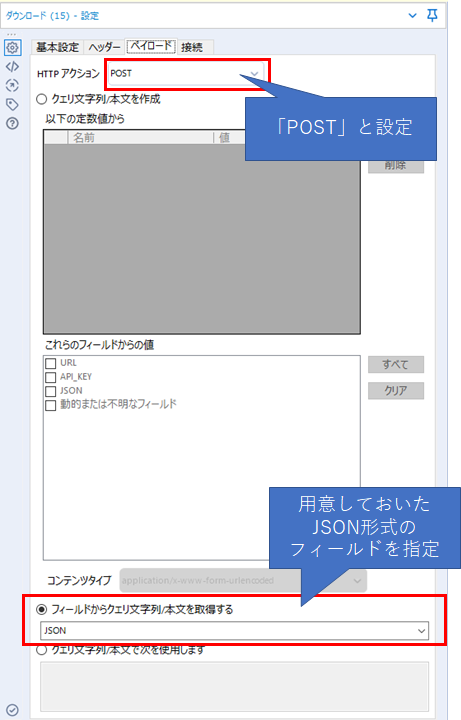
HTTPアクションは、Curlのソースでも以下のように記載ある通り「POST」を選択するようにしましょう。
curl -X POST \
本文は、curlのコードの「--data」以降の部分が該当します。このcontentのところにある「Enjoy your vacation!」というのが実際に分析したい文章になります。なお、typeはHTMLとPLAIN_TEXTが選択でき、HTMLにすると、文章内に含まれるHTMLタグを削除して分析を行なってくれます。
--data "{
'encodingType': 'UTF8',
'document': {
'type': 'PLAIN_TEXT',
'content': 'Enjoy your vacation!'
}
}"
この部分が実際にAPIに入力するデータとなります。この形式がいわゆる「JSON」形式です。
{ 'encodingType': 'UTF8', 'document': { 'type': 'PLAIN_TEXT', 'content': 'Enjoy your vacation!' } }
これをこのままテキスト入力ツールに貼ればOKですが、文章に「'(シングルクオート、一重引用符)」があるとおかしくなるので、ダブルクオテーション(二重引用符)に変えてから貼り付けましょう(ちなみに、文章内に二重引用符があるとおかしくなるので、エスケープ処理というのが必要になりますが、後ほど説明します)。
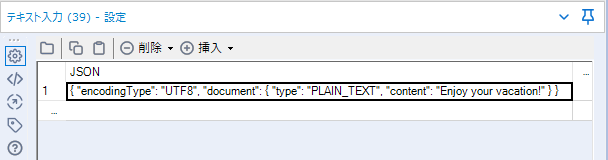
ちなみに、言語設定も可能ですが、基本はオートで認識してくれます。ただ、漢字のみの文章などだと中国語と誤認識されるケースもあるので、その場合は、以下のように言語設定を含めます。なお、サポートされている言語はこちら fa-external-linkを御覧ください。
{ 'encodingType': 'UTF8', 'document': { 'type': 'PLAIN_TEXT', 'language': 'JA', 'content': '休暇を楽しみましょう' } }
今回はJSON形式で用意したフィールドを指定するため、「フィールドからクエリ文字列/本文を取得する」を選択します。
以上を踏まえて、ダウンロードツールの設定は以下のようになります。
結果を見る
ダウンロードツールに出力される結果は、DownloadData、DownloadHeadersという二つの項目に出力されます。
![]()
DownloadHeadersは、返ってきたヘッダー情報で、エラーがあればここに出力されます。正常な場合は、頭に「HTTP/1.1 200 OK」などと出力されます。JSONの書き方などミスっていると「HTTP/1.1 400 Bad Request」などのエラーコードが返ってきます。詳細は「HTTP ステータスコード」などで検索いただければと思います。Wiki fa-external-linkも参考になりますね。
欲しい結果は、DownloadDataフィールドに入ってきます。中身を見てみましょう。
{
"documentSentiment": {
"magnitude": 0.9,
"score": 0.9
},
"language": "en",
"sentences": [
{
"text": {
"content": "Enjoy your vacation!",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
]
}
中身はJSON形式で返ってきています。このままだと扱いにくいので、JSONパースツールでテーブル形式にしてみたいと思います。
結果整形部分のワークフローは以下のようになります。
まず不要なフィールドをセレクトツールで消しておきましょう。というのが、API呼び出しに使ったURLや本文がそのまま残っていると、JSONパースツールを使うときに大量にそのデータがコピーされてしまいます。
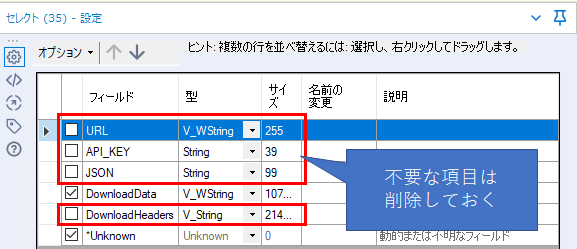
JSONパースツールの設定はあまりありません。
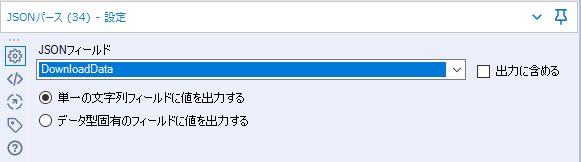
「出力に含める」は基本的にチェック不要です。無駄にサイズの大きな結果データがコピーされてしまいます。
もう一つのオプションの「単一の文字列フィールドに値を出力する」「データ型固有のフィールドに値を出力する」は今回は前者にしています。
これによる結果は以下のとおりです。
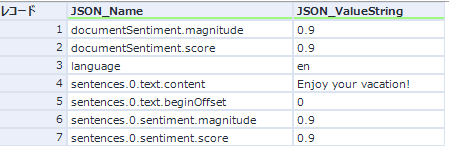
本の形式よりは見やすくなったかと思います。
結果の見方はGoogle社のドキュメントを確認して頂いた方が良いかと思いますが、どこにあるのか見つけるのはなかなか大変かもしれません。結論としては、Google社のドキュメントの「リファレンス」の中にあります。
magnitudeは0以上の数値で、感情の絶対的な大きさとなります。
scoreは、感情のスコアで、否定的な感情を-1.0とし、肯定的な感情を1.0とした間の値を取ります。
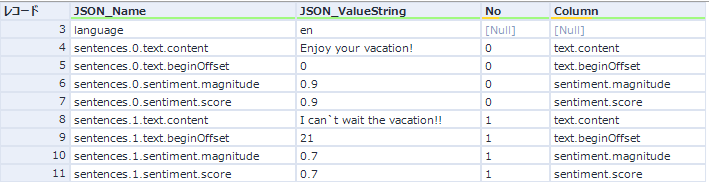
また、ドキュメント全体のスコアと各文章のスコア二つが出力されます。例えば、二つの文章がある場合は以下のように出力されます。
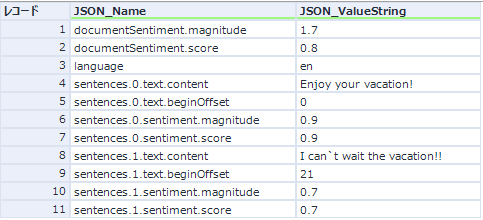
JSON_Nameのsentencesで始まる部分が各文章のスコアになりますが、sentencesの後に続く数字が文章ごとに自動的に振られる連番です。
なにげにこの縦持ちの持ち方だと扱いにくいので、ここからもう少し扱いやすい形式にしていきましょう。まず、sentencesで始まる行について取り出した後、正規表現ツールを使ってNoとカラム名に分けてみたいと思います(もちろん、列分割ツールやフォーミュラツールで整形することも可能です。初心者の方はそちらの方がわかりやすいかと思いますが、今回はスマートに正規表現ツールで行います)。
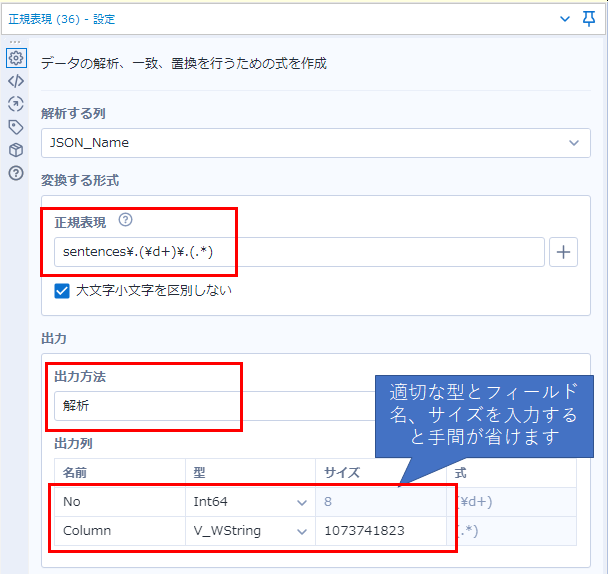
正規表現式は、以下のとおりです。
sentences\.(\d+)\.(.*)
ドット「.」は正規表現では「なんでもいい一文字」という意味になるので、「\」でエスケープする必要があります(頭に\をつけて「\.」と表現することで、ドットそのものを表現できます)。「\d+」は数字1文字以上を指します。この設定で以下のようなデータとなります。
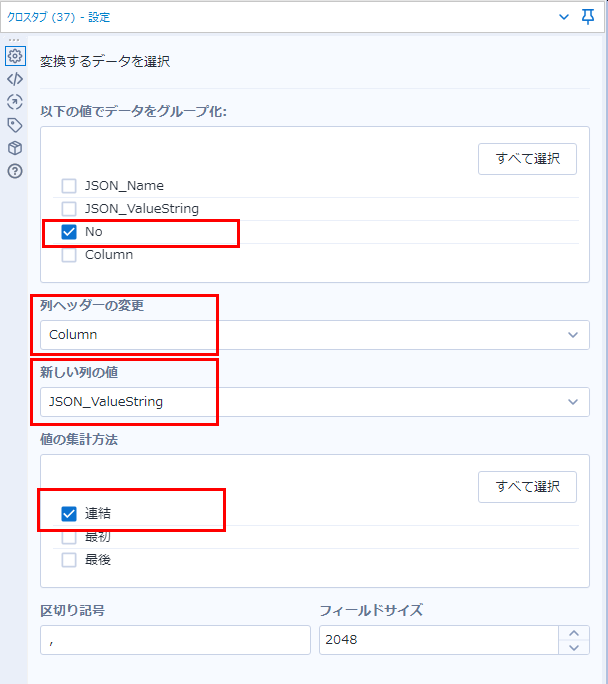
最後にクロスタブでデータを横持ちにします。
最終結果は以下の通りです。

なお、最初に入力する本文が複数レコードある場合は若干ワークフローの改変が必要です(最終の結果がまぜこぜになってしまいます)。
感情分析以外を使うには?
その他のエンティティ分析、構文解析、エンティティ感情分析、コンテンツの分類を行いたい場合は、エンドポイントのURLが変わるだけです。
| 分析内容 | URL |
|---|---|
| 感情分析 | https://language.googleapis.com/v1/documents:analyzeSentiment |
| エンティティ分析 | https://language.googleapis.com/v1/documents:analyzeEntities |
| 構文解析 | https://language.googleapis.com/v1/documents:analyzeSyntax |
| エンティティ感情分析 | https://language.googleapis.com/v1/documents:analyzeEntitySentiment |
| コンテンツの分類 | https://language.googleapis.com/v1/documents:classifyText |
ただし、出力結果はそれぞれ異なりますので、出力結果の整形は個別に作り込む必要があります。
また、コンテンツの分類では「EncodingType」を送信するJSONに含めるとエラーになるので、含めないようにしてください(詳細はサンプルワークフローを御覧ください)。
実践的なワークフローにする
入力データはJSON形式にする必要がありますが、そのままJSONで送るとエラーになる文字がいくつかあります。そのような文字はエスケープする必要がありますが、ちょっと面倒なので、JSONビルドツールでエスケープ処理をする方法をご紹介します。
本来はJSONビルドツールでJSON形式にするのが筋ですが、正直なところ完璧なツールではありません(ずっとラボラトリーカテゴリに入っているのが理由かと思います)。JSON自体が複雑なデータ形式を扱えることもあり、作りたいJSONデータすべてに対応しきれていないのが現実です。
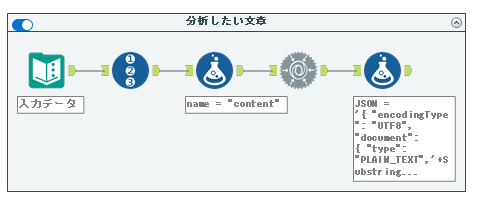
まず、JSONビルドツールの前の段階で以下のようなデータを作ります。

JSONビルドツールの設定は以下のとおりです。
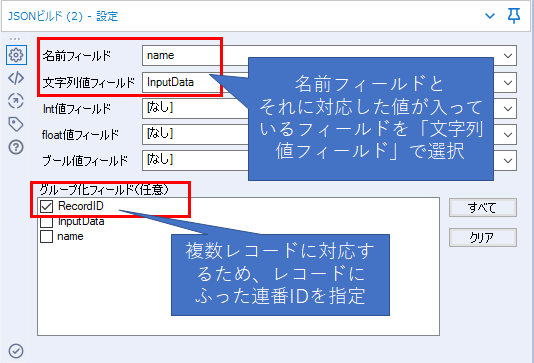
これで以下のようなデータができます。

実は、欲しいのは{}の中になるので、フォーミュラツールのSubString関数で頭とお尻のカッコを削除しつつ、最終形のJSON形式にします。以下のような数式を使います。
'{ "encodingType": "UTF8", "document": { "type": "PLAIN_TEXT",'+Substring([JSON],1,Length([JSON])-2)+'}}'
これで本文のJSON形式ができました。わざわざエスケープ処理を組み込まなくて良い方法となります(もちろん、Replace関数などを使ってエスケープ処理を行うことも可能です)。
その他のサンプル
感情分析以外の結果のサンプルをご紹介します(すべてサンプルワークフローで確認可能です)。
エンティティ分析
入力
私は今日みなとみらいに行きました。明日は目黒川で花見をしますが、写真は新しく買ったiPhoneで撮ろうと思います。
出力

エンティティ感情分析
入力
明日は目黒川で花見をしますが、写真は新しく買ったiPhoneで撮ろうと思います。最高の写真が撮れるはず!
出力

構文解析
入力
明日は目黒川で花見をします。
出力

コンテンツの分類
入力
Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show. Sundar Pichai said in his keynote that users love their new Android phones.
出力

※日本語未対応なので、英文での結果となります
サンプルワークフローダウンロード
GoogleNLP_Sample fa-download
サンプルとしていくつかファイルを同梱しています。
| NLP_Sentiment_Sample_1_for_web.yxmd | 本記事で使用したワークフロー |
| NLP_Sentiment_Sample_2_for_web.yxmd | 感情分析ワークフロー。実践的な形に変更しています。 |
| NLP_Entities_Sample_for_web.yxmd | エンティティ分析ワークフロー。 |
| NLP_EntitySentiment_Sample_for_web.yxmd | エンティティ分析+感情分析ワークフロー。 |
| NLP_ClassifyText_Sample_for_web.yxmd | テキスト分類ワークフロー。 |
サンプルワークフローからはAPIキーを抜いていますので、各自入手したAPIキーをテキスト入力ツールに入力して試して下さい。なお、APIキーの取り扱いについては十分注意願います。
マクロダウンロード

※Alteryx Designer バージョン 2021.4.1.04899時点の情報です
written by AkimasaKajitani