運営会社
運営会社
Alteryxツールアイコン「スキーマ変換ツール」(Schema Fit Tool)をご紹介します
 スキーマ変換ツール(Schema Fit Tool)
スキーマ変換ツール(Schema Fit Tool)
[GenAI]カテゴリの[スキーマ変換]ツールを紹介します。
概要
スキーマ変換ツールは、手持ちのデータをお手本となるデータに合わせこむようにデータを自動的にLLMに変換させるツールです。LLMは変換用のPythonコードを作成するだけで、実際の変換はPythonコードで行われます。

T入力がTarget入力ということで、お手本データを入れるところです。S入力がSource入力ということで、変換したい元データを入力します。Mは認証情報をいれるところなので、LLM設定上書きツールの結果を入力してください。
名前は英名でSchema Fitツールですが、実態はTransformationツール(ETLのTの部分)といっても過言ではありません。それを反映してか、日本語名は「スキーマ変換」となっています。
このツールを使うためには?(契約関係)
本ツールはエディションベースの契約(Alteryx Oneでの契約)かつ、AI Builderのオプション契約がある場合のみ、LLMリストが取得されます(AI Builderは、Intelligence SuiteとGenAIツールが利用できるオプション契約です)。
また、ベーシックユーザーロールの方(Basic Creator)は利用できません。フルユーザーロール(Full Creator)の権限が必要です。
入出力
入力
- M入力
LLMのモデル入力用インプットです。「LLM上書き設定」ツールの出力を接続してください。
- T入力
Target入力ということで、ここに入力したデータの形式に合わせこむようにLLMがアウトプットを作ってくれます。
- S入力
Source入力ということで、ここに入力したデータが変換元になります。
出力
- T出力
Transformation出力ということで、変換に使ったPythonコード、どのような変換をしたか、という情報が出力されます。
- D出力
実際にS入力が変換された結果が出力されます。
設定項目
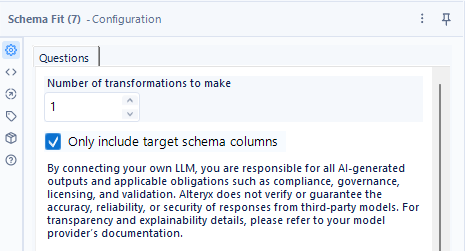
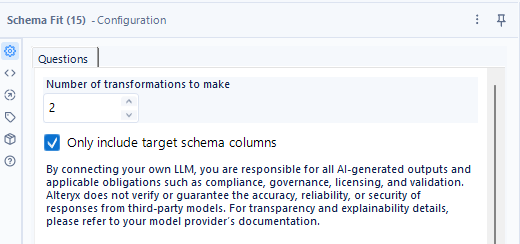
設定画面は以下のとおりです。非常にシンプルで、「Number of transformations to make」というオプションと、「Only include target schema columns」という2つのオプションしかありません。
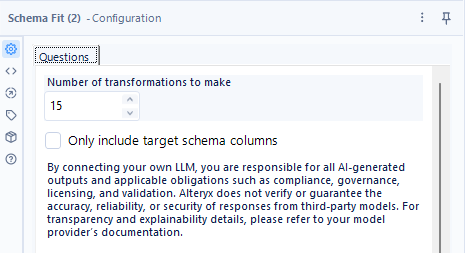
UIが英語なので日本語にしてみます。
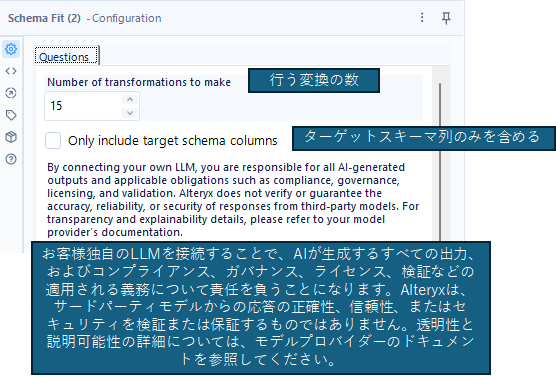
設定項目はわずか2つです。「Number of transformations to make」は「行う変換の数」で、S入力のデータからT入力のデータに変換する作業の数と考えてよいかと思います。
「Only include target schema columns」は、T入力に入力された列のみ残すオプションです。この場合、チェックが入っていると、S入力の余計な項目は出力されません。
使い方
サンプルワークフローを元に使い方を解説していきます。
例1:Fitting a schema(単純な例)
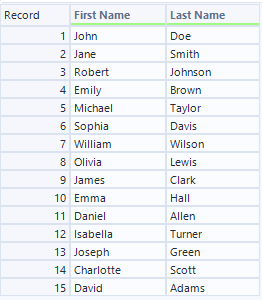
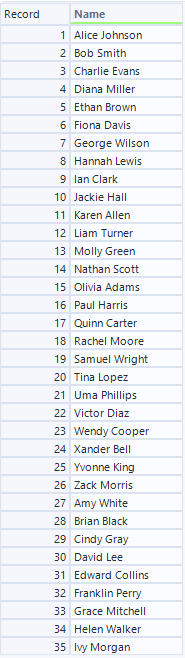
最初の例は非常に単純な例で、Name列をFirst NameとLast Nameに変換するというタスクです。
入力
- インプット(T入力)
- インプット(S入力)
設定
出力
- T出力
T出力は、コードとその説明(カラム名:Transformation Step)が出力されます。
今回のワークフローの結果のTransformation Stepカラムの内容は以下のとおりでした。
The "Name" column should be split into two separate columns: "First Name" and "Last Name". The values in "Name" can be transformed by using string manipulation to extract the first and last names.(「名前」列は「名」と「姓」の2つの列に分割する必要があります。「名前」列の値は、文字列操作を使用して変換することで、名と姓を抽出できます。)
コードは以下のようなPythonコードが出力されました。
import pandas as pd
import re
# Check if 'Name' column exists in the DataFrame
if 'Name' in df.columns:
# Split the 'Name' column into 'First Name' and 'Last Name'
try:
split_names = df['Name'].str.split(' ', n=1, expand=True)
if split_names.shape[1] == 2:
df['First Name'] = split_names[0].str.strip()
df['Last Name'] = split_names[1].str.strip()
else:
raise ValueError("The split operation did not result in exactly two columns.")
except Exception as e:
print(f"Error processing 'Name' column: {e}")
else:
print("Column 'Name' does not exist in the DataFrame.")
# Drop the original 'Name' column if it was split successfully
if 'First Name' in df.columns and 'Last Name' in df.columns:
df.drop(columns=['Name'], inplace=True)
- D出力
T出力で作られたPythonコードを使って処理された結果がこちらです。
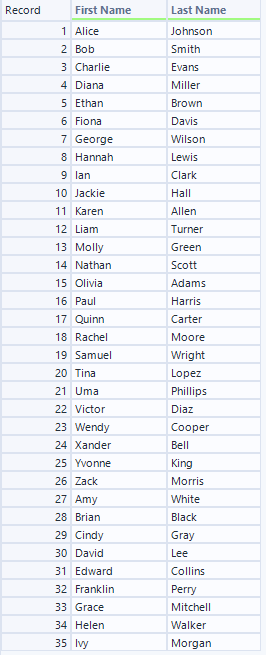
1項目に入っていた名前が、見事First NameとLast Nameに分かれています。
例2:Transformatin Settings(変換設定を変更)
2つ目のサンプルは、「Number of transformations to make」のオプションを2に変更した場合のサンプルです。
入力
- T入力
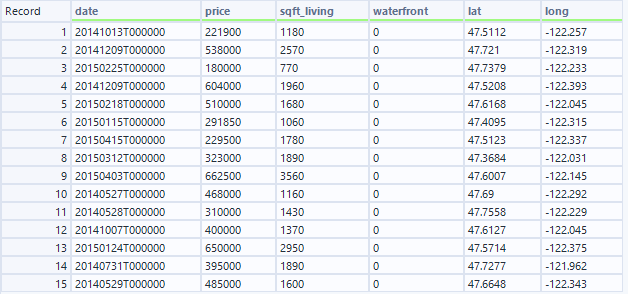
- S入力

お手本に合わせるなら、Date列の表記変更、price列は数値のみ、sqft_livingは・・・どうするんですかね?waterfrontはYes/Noで0もしくは1にするのでしょうか?これはちょっとわかりにくい・・・。coordinatesは緯度経度に分割という感じです。いろいろなタスクを行う必要があるように見えます。少なくとも5つのタスクはありそうです。
設定
設定は以下の通りで、「Number of transformations to make」を2に設定します。
出力
- T出力
T出力の結果は以下のとおりですが、2行出てきました。
1行目は以下の通りでした。
The "date" column needs to be transformed from a Date type to a String type and reformatted into the "YYYYMMDDTHHMMSS" format. The dates in the source schema need to be converted to a string representation that appends "T000000" to each date.(「date」列を日付型から「YYYYMMDDTHHMMSS」というパターンに従う文字列形式に変換する必要があります。具体的には、既存の日付値の末尾に時刻「T000000」が含まれるように再フォーマットする必要があります。)
つまり、最初のdate列が処理された、ということになります。それに対応するPythonコードは以下のとおりです。
import pandas as pd
import re
# Check if the 'date' column exists in the DataFrame
if 'date' in df.columns:
try:
# Convert the 'date' column to datetime format
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# Handle any NaT values that might occur due to conversion issues
if df['date'].isna().any():
raise ValueError("Conversion issues found in 'date' column.")
# Format the date to the target schema format
df['date'] = df['date'].dt.strftime('%Y%m%dT%H%M%S')
except Exception as e:
print(f"Error processing 'date' column: {e}")
else:
print("Column 'date' does not exist in DataFrame.")
2行目は、以下のような変換が行われました。
The column "waterfront" should be transformed from a string representation of yes/no values to an integer representation, where "yes" is converted to 1 and "no" is converted to 0.(列「ウォーターフロント」は、はい/いいえ値の文字列表現から整数表現に変換する必要があります。ここで、「はい」は 1 に変換され、「いいえ」は 0 に変換されます。)
waterfront列のコード変換が行われたようです。それに対応するコードは以下のとおりです。
# Validate that the 'waterfront' column exists in the DataFrame
if 'waterfront' in df.columns:
# Map 'yes' to 1 and 'no' to 0, converting to int
df['waterfront'] = df['waterfront'].astype(str).str.strip().map({'yes': 1, 'no': 0}).astype('float').astype('int')
else:
print("Column 'waterfront' does not exist in the DataFrame.")- D出力

正直なところ、結果としては中途半端になっていますね。date列の変換とwaterfrontのyesが1に、noが0に変換されたくらいで、確かに2つの変換が行われていますが、どのように変換するものを選択しているのかは不明です。
さて、このtransformation設定を5にするとどうなるでしょうか?

いい感じにできてますね。どのように変換したのでしょうか?T出力を見てみましょう。

- The "date" column needs to be transformed from a date type to a string format that follows the pattern "YYYYMMDDTHHMMSS". Specifically, the existing date values should be reformatted to include the time "T000000" at the end.(「date」列を日付型から「YYYYMMDDTHHMMSS」というパターンに従う文字列形式に変換する必要があります。具体的には、既存の日付値の末尾に時刻「T000000」が含まれるように再フォーマットする必要があります。)
- The column "waterfront" needs to be transformed from a string representation of categorical values ("yes", "no") to integer values (0 for "no" and 1 for "yes").(「waterfront」列を、カテゴリ値(「yes」、「no」)の文字列表現から整数値(「no」の場合は0、「yes」の場合は1)に変換する必要があります。)
- The "coordinates" column should be split into two separate columns: "lat" and "long". The latitude and longitude values can be extracted from the string representation of the coordinates and converted to float type. The existing coordinate format "(latitude, longitude)" needs to be parsed to extract these values correctly.(「coordinates」列を「lat」と「long」の2つの列に分割する必要があります。緯度と経度の値は、座標の文字列表現から抽出し、float型に変換できます。これらの値を正しく抽出するには、既存の座標形式「(latitude, longitude)」を解析する必要があります。)
- The column "sqft_living" needs to be converted from a String type to an Int type. Additionally, the values should be transformed by removing the "^2" suffix and converting the remaining string to an integer after removing any commas (e.g., "10,000" becomes 10000).()「sqft_living」列をString型からInt型に変換する必要があります。さらに、値は「^2」サフィックスを削除し、残りの文字列をカンマを削除して整数に変換する必要があります(例:「10,000」は10000になります)。
- The column "price" needs to be transformed from a String type containing formatted currency values into an Int type by removing the dollar sign, commas, and converting the values to integers.(列「price」は、ドル記号とカンマを削除し、値を整数に変換することで、フォーマットされた通貨値を含むString型からInt型に変換する必要があります。)
つまり、「Number of transformations to make」設定を増やすと、一つずつ変換する内容が増える、ということですね。
バグっぽい動き
特定の1つのワークフローで同時に複数のスキーマ変換ツールを使うと、内部のテンポラリ的に作成しているファイルがかぶり、実行できないのでコントロールコンテナで一つずつ動くようにする必要があります。

まとめ
- Schema Fit(スキーマ変換ツール)ツールについて説明しました
- 用意されているサンプルワークフローについて解説しました
- 処理時にPythonコードを作成しているので、結果が出てくるまでに時間がかかります。Pythonコードも出てくるので、2回目以降はこの出てきたPythonコードを再利用したほうが効率も良いかと思います。Pythonコードについては読み込み、書き出し部分は入っていないので、そのあたりの組み込み作業が必要なのは注意ポイントかもしれません(それすらLLMのPromptツールに指示して作ればよいのかもしれません)。
※Alteryx Designer 2025.1.2.120 時点の情報です