 運営会社
運営会社
【AlteryxTips】AlteryxでWebスクレピングをしてみました
こんにちはMJです。
今日はAlteryxでWebスクレピングをする方法についてご紹介します。
Webスクレイピングとは
Webスクレイピングとは、データを抽出したい対象が明確であり、特定のWebサイトを追跡してデータを保存する技術です。
通常、PythonのBeautifulSoupライブラリを使用してデータを抽出しますが、今回はAlteryxのダウンロードツールと正規表現ツールを利用してデータを抽出してみます。
1. スクレイピングするページの指定
データを抽出するページとして、総務省統計局のe-Statを選定しました。
このサイトは、日本のさまざまな公共データや統計情報を一元的に提供し、政府機関、地方自治体、研究機関などが収集したデータを一般の人々も簡単にアクセス・活用できるようになっています。

特に、ほぼ毎日データが更新されるため、Alteryxのツールを活用して自動化し、新規追加データを確認することで、参考になると考えました。新着情報一覧ページ
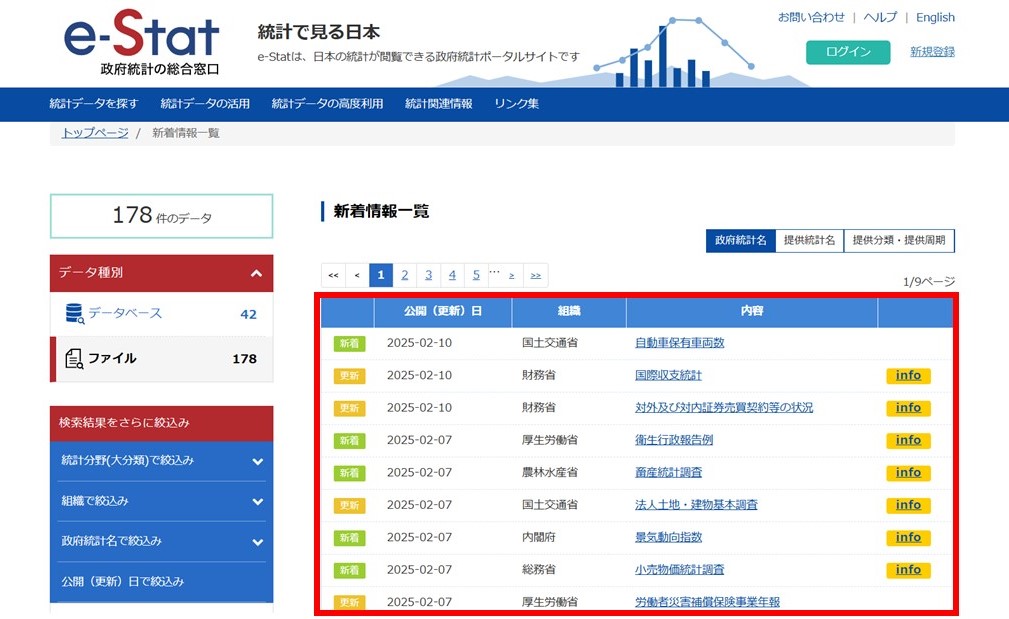
それでは、「新着情報一覧」テーブルの「新規フラグ」「更新日」「組織」「内容」「URL」を抽出してみます。
2. HTML構造の分析
まず、Webスクレイピングで最も時間がかかる部分として、抽出したいデータを取得するために「新着情報一覧」テーブルのHTML構造を分析する必要があります。
Webページ上で、右クリック → 検証 や Ctrl+Shift+C を押して、抽出対象のHTMLコードを確認します。
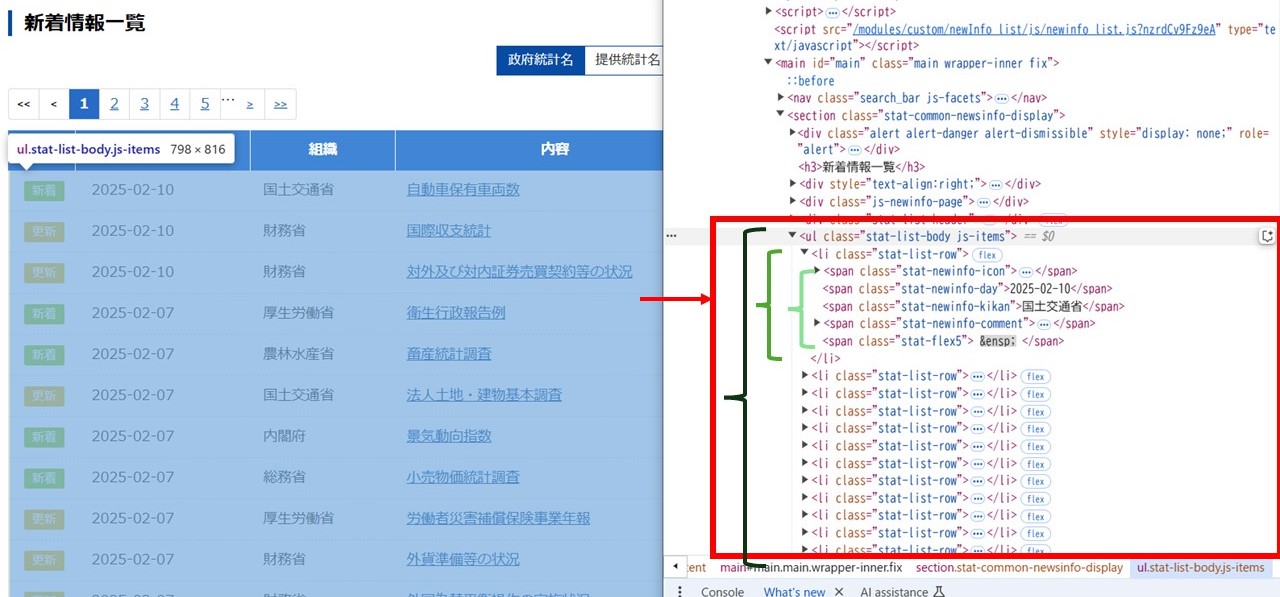
HTMLコードを確認した結果、<ul> タグの中に <li> タグで各行のデータが格納されており、 <li> タグの中の <span> タグごとに情報が保存されていることを確認しました。
3. AlteryxでWebページのHTMLコードを取得
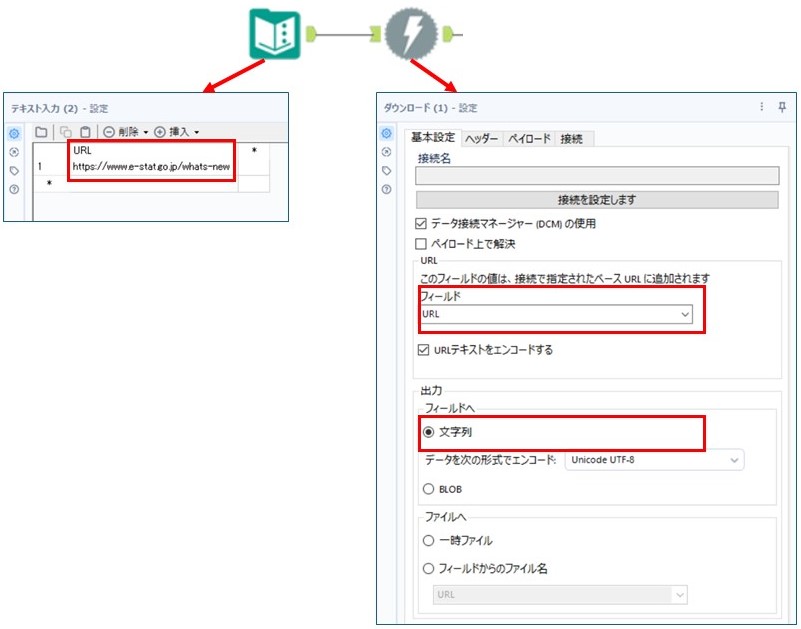
それでは、ダウンロードツールを使用して、「新着情報一覧」ページの情報を抽出してみます。
まず、テキスト入力ツール を利用して、ページのURLを入力します。
次に、ダウンロードツール でURLを指定し、出力形式を「文字列」に設定します。
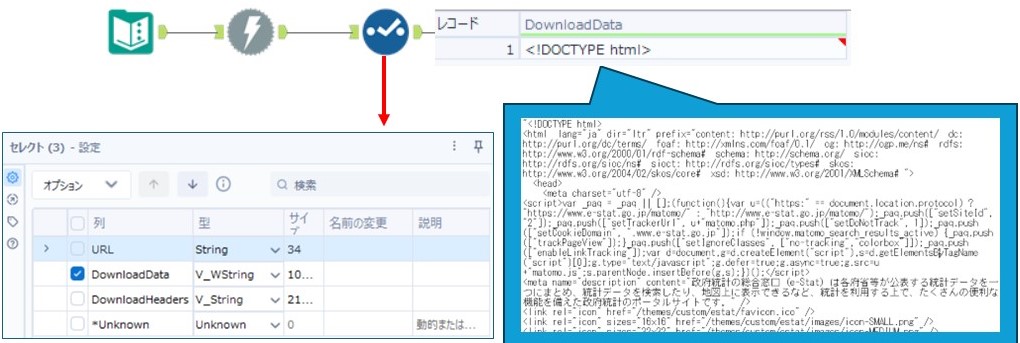
このワークフローを実行し、データを正常に取得できた場合、DownloadHeaders フィールドに 200 の値が入り、DownloadData フィールドに HTMLコード が保存されていることが確認できます。

この後、使用するデータは DownloadData フィールドの値なので、セレクトツール を使用して他のフィールドを削除します。
4. 正規表現ツールを用いたデータ抽出
ダウンロードツールで取得したHTMLコードから、正規表現ツールを使って必要なデータを抽出する作業を繰り返します。
まず、<ul> タグの中に <li> タグが各行のデータとして格納されているため、<ul> タグ内のデータを抽出する正規表現 を作成します。
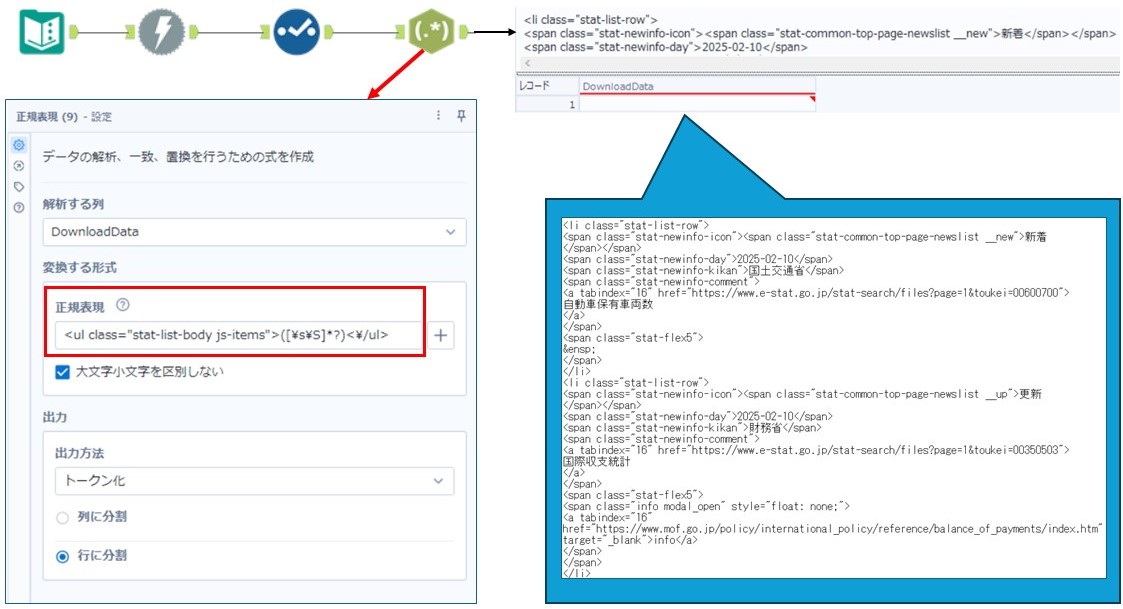
次に、<li> タグ内の情報を1行ごとに分割するために、正規表現ツールで出力方法で「トークン化の行に分割」を実行します。
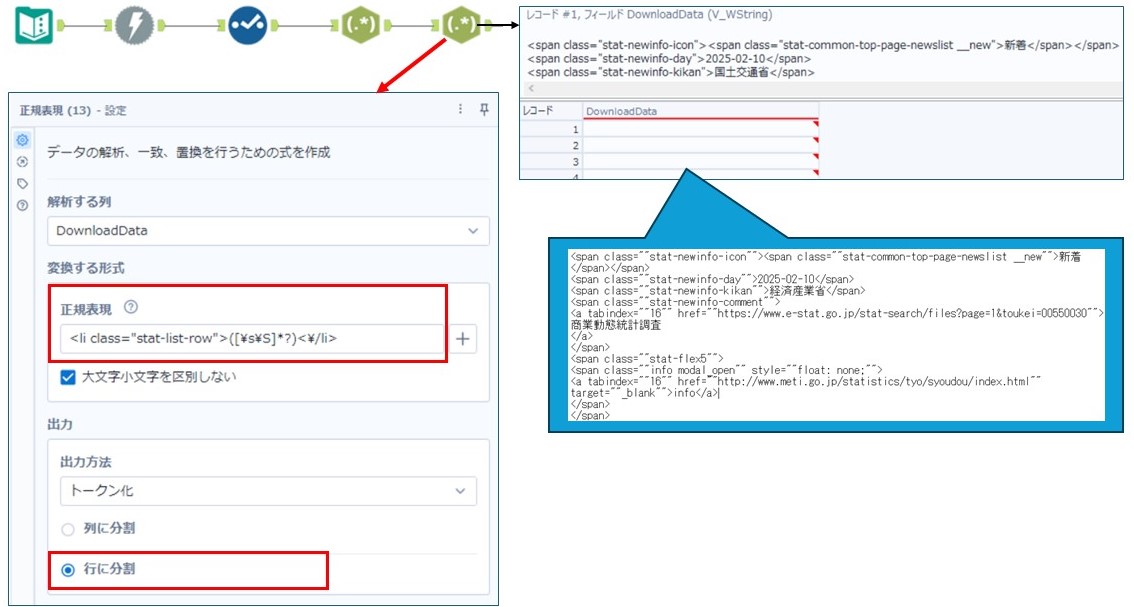
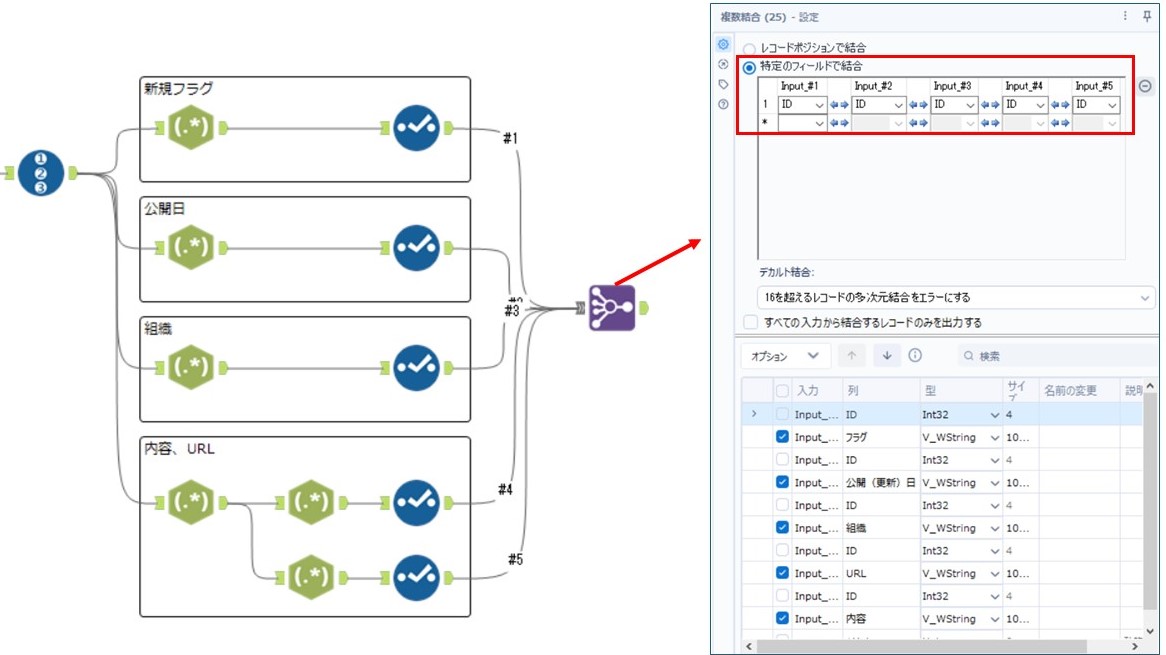
その後、レコードIDツール を使用して各行にIDを付与し、 <span> タグ内の [新規フラグ、更新日、組織、URL、内容] のデータを、それぞれの正規表現を使って抽出します。
抽出が完了したら、複数結合ツール を使用して、IDフィールドを基準にデータを結合します。
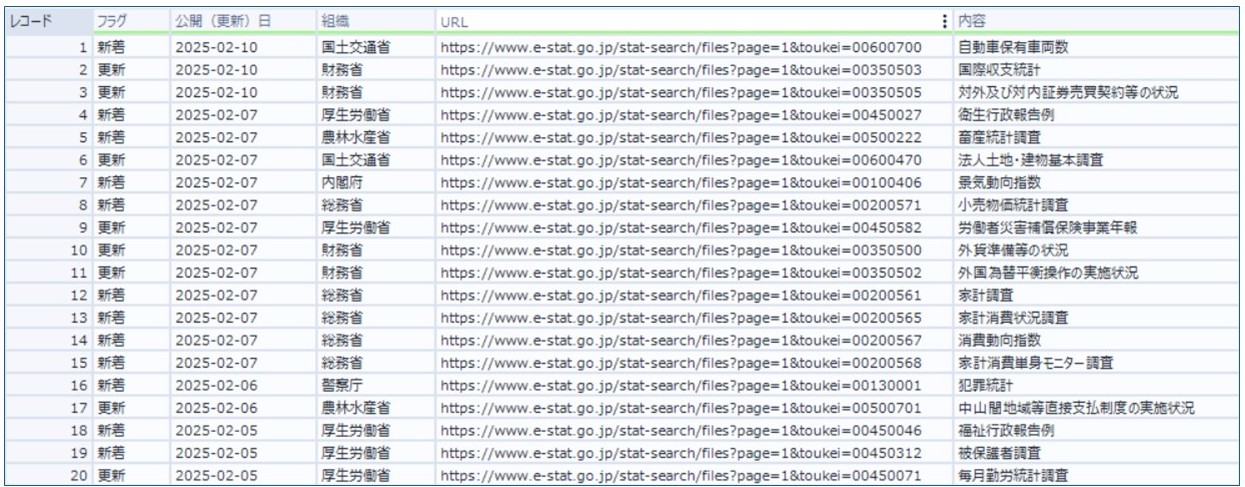
そうしますと、e-Statの「新着情報一覧」ページから、新たに追加・更新されたデータテーブルを抽出することができました。
まとめ
このように、ダウンロードツールと正規表現ツールを活用し、AlteryxでWebスクレイピングを実行してみました。
特定のWebサイトの構造を分析し、正規表現を使ってデータを抽出する工夫をすれば、簡単に自動化できると思います。










