 運営会社
運営会社
PDFのテキスト読み込み方法についてご紹介致します。
近年、請求書などの紙から電子化の流れが急速に進んでいます。
UiPathではPDFを簡単に扱えるアクティビティが用意されていますので、今回はパッケージのインストールからPDFのテキストの読み取り方法をご紹介致します。
PDFアクティビティパッケージのインストール
PDFを取り扱う為のアクティビティはデフォルトではインストールされていない為、パッケージを追加する必要があります。
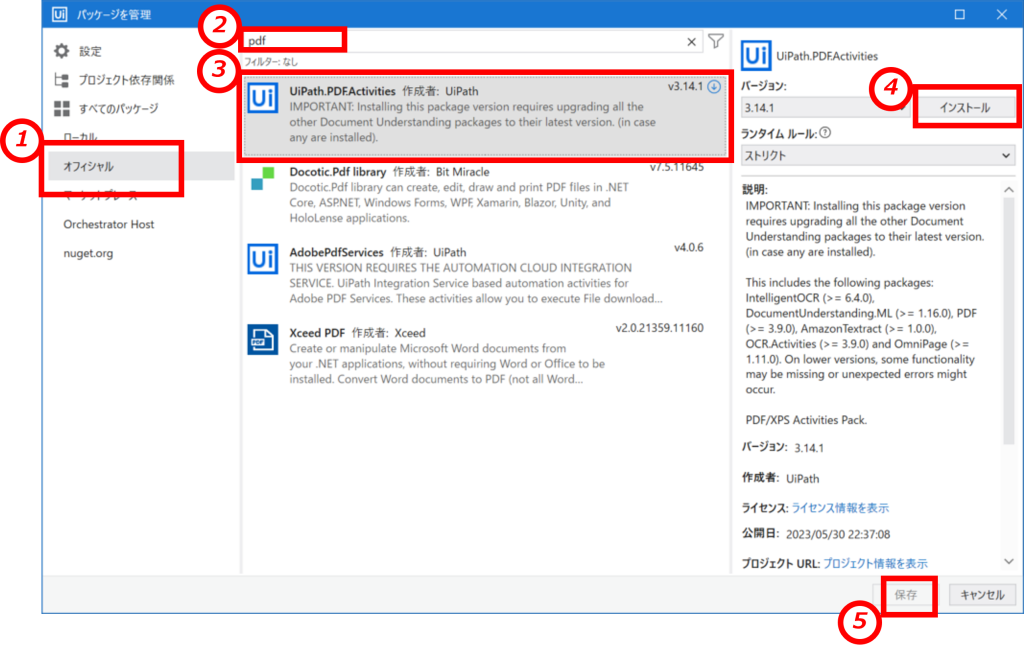
「デザイン」タブの上部のリボンよりパッケージを管理をクリックします。

「パッケージを管理」ウィンドウが開きますので
①左の枠内の「オフィシャル」を選択
②検索窓に"PDF"と入力
③中央の枠にUiPathオフィシャルのPDFパッケージが表示されるので選択
④インストールをクリック
⑤保存をクリック(画像では保存ボタンがグレーアウトされていますが、インストールが完了すればクリックが可能となります)
上記の流れでアクティビティの使用が可能となります。
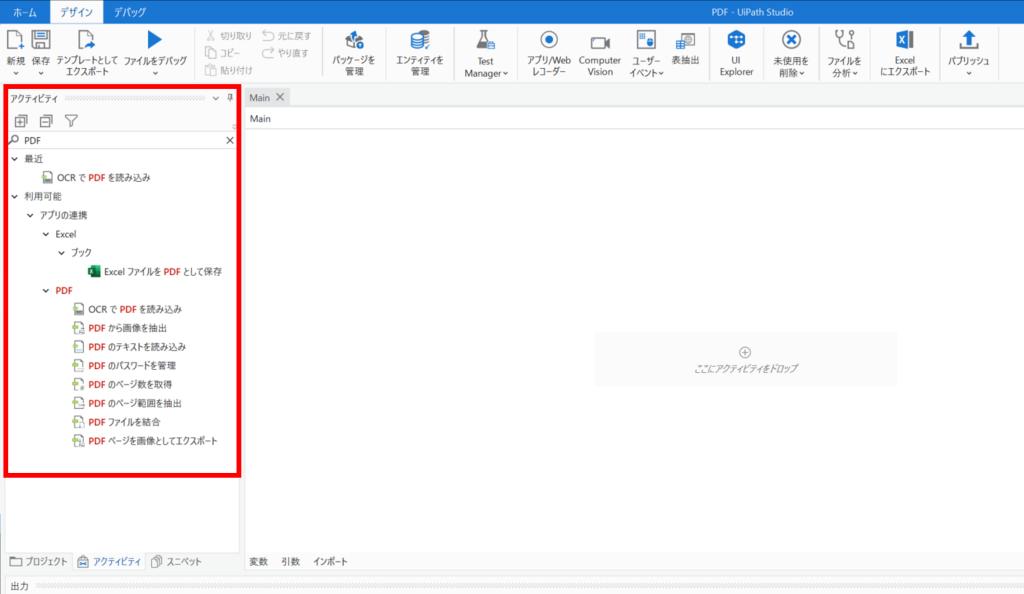
保存後、PDFアクティビティがアクティビティ一覧に表示されます。
アクティビティ一覧→利用可能→アプリの連携→PDFにてPDF操作関連のアクティビティが表示されます。
設定方法
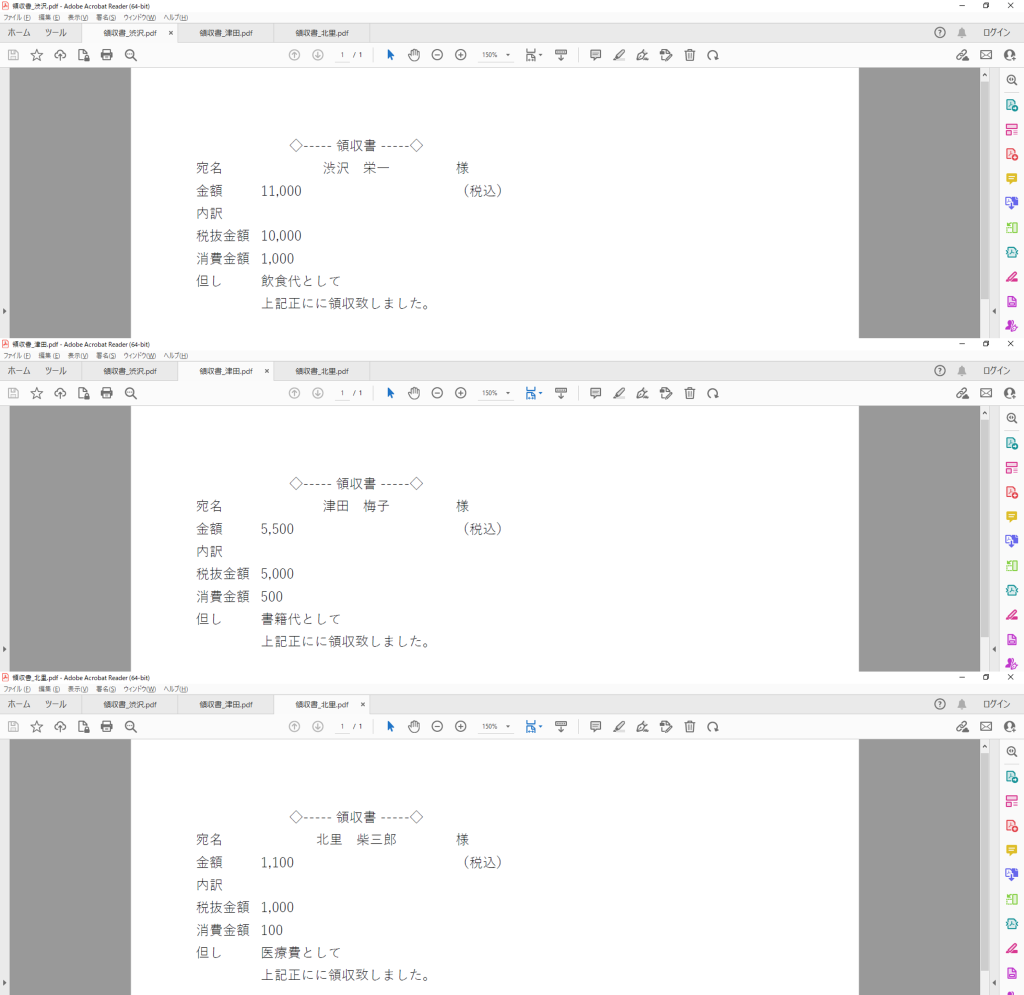
今回はPDFにテキストとして保存されている文字を読み取りたいと思います。サンプルとして以下のPDFを用意致しました。
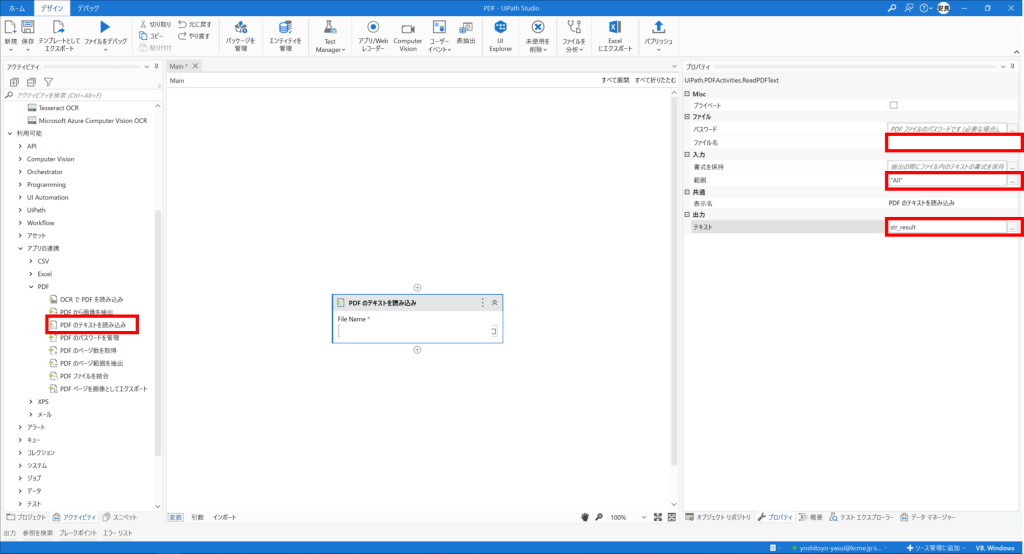
対象のフォルダに保存されているPDFを全て読み込むシチュエーションにて進めていきたいと思います。PDFの読み込みは"PDFのテキストを読み込み"アクティビティを使用します。プロパティにて入力ファイル名と出力変数を指定するのみなので設定は簡単です。範囲についてはデフォルトでは"All"となっていますが、ページ指定や("1"で1ページ目)やページ範囲("1-3"1から3ページ)などの設定が可能です。
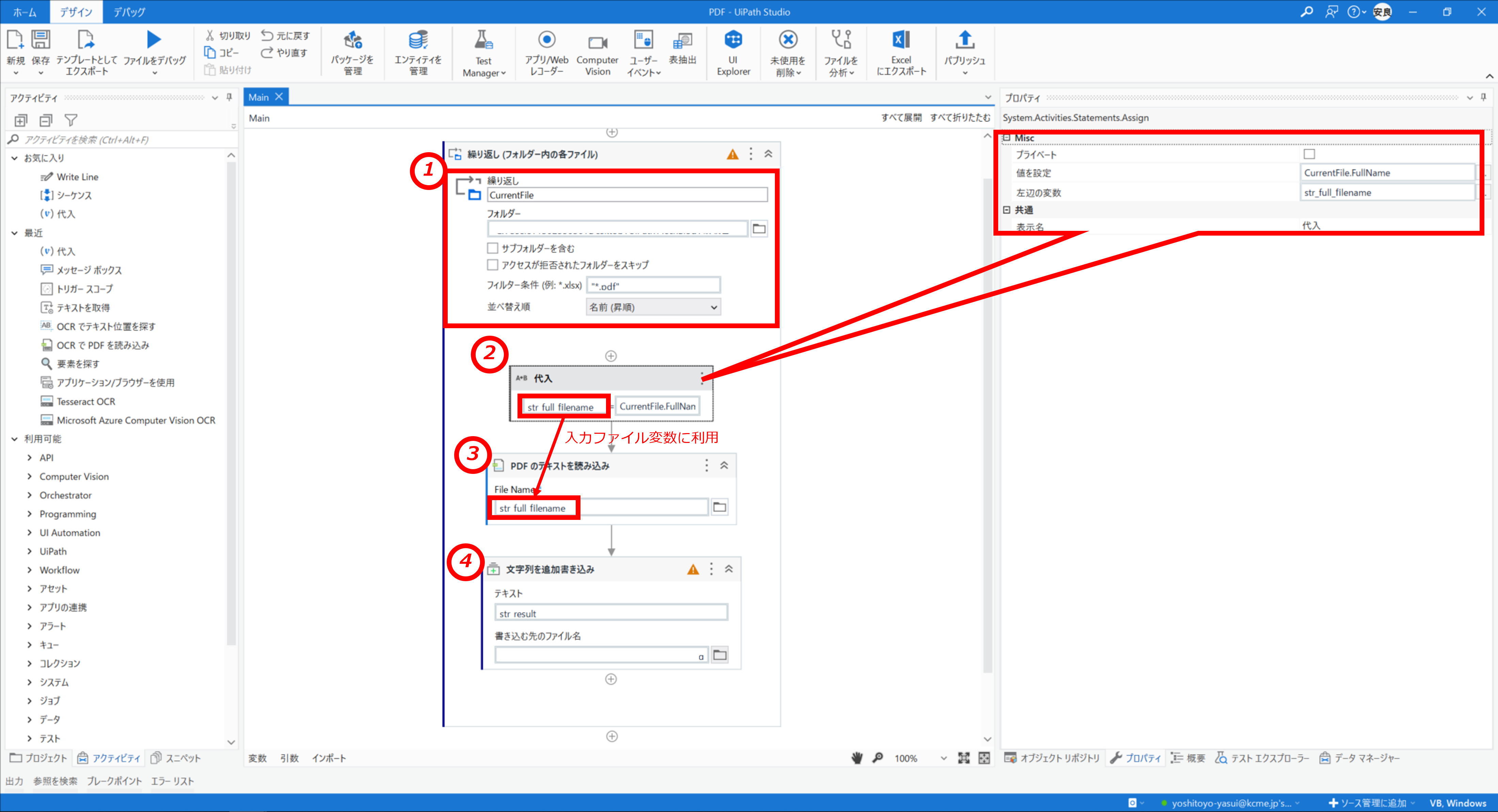
今回はフォルダ内すべてのPDFを読み取る為、デフォルトでインストールされている"繰り返し(フォルダー内の各ファイル)"アクティビティを使用します。こちらもフォルダー欄に対象のフォルダのパスを指定するのみですので簡単に設定可能です。
処理の流れ
- 繰り返しアクティビティにより対象フォルダ内のファイルの情報を順次変数CurrentFileに格納
PDF以外のファイルを"PDFのテキストを読み込み"に指定するとエラーとなりますので、フィルター条件に"*.pdf"を指定してPDF以外のファイルを除いています。 - 変数CurrentFileよりファイルのフルパスを抽出
CurrentFile.FullNameにてフルパスを抽出し、"PDFのテキストを読み込み"の入力変数に代入 - PDFの読み込み
- 読み込んだ文字列をテキストに追記
- 全てのファイル分を繰り返し...
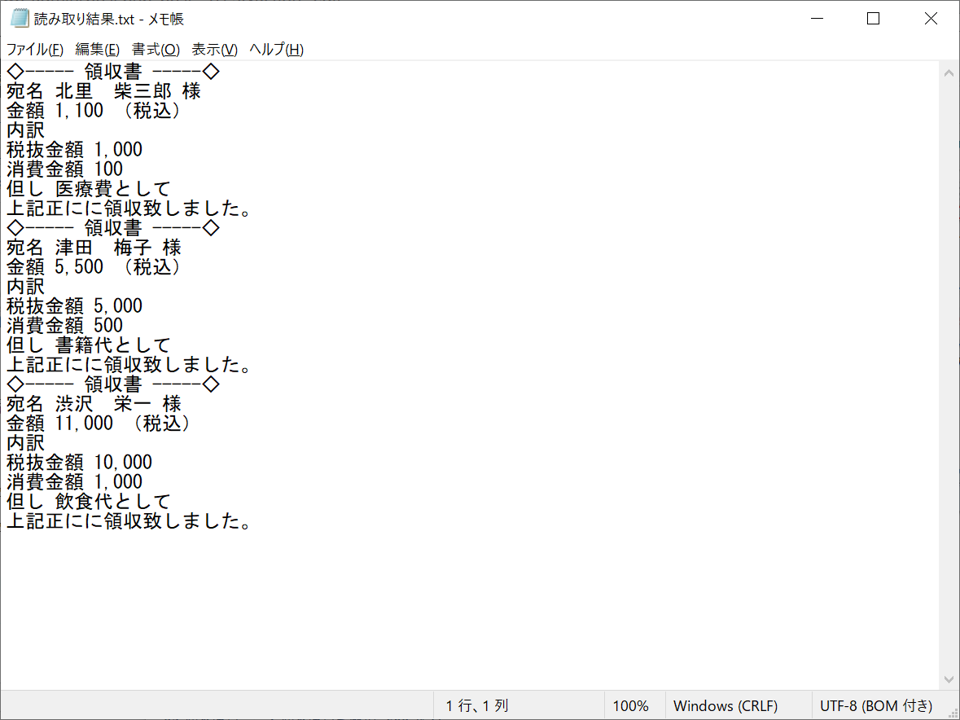
こちらが読み取り結果となります。
まとめ
きれいに読み取ることができました!
ただ、このままでは金額の突合や用途の集計などでの利用には向かないので、UiPathの文字列操作関数による整形やAlteryxなどのETLツールによる整形及び表形式への変換など、データの活用にはもう一工夫必要となります。
また、今回はテキスト情報を読み取りましたが、テキストではない画像の読み取りには、サードパーティ製のOCRとの連携やUiPathのAIドキュメント処理製品であるDocument Understandingの導入などにより、よりよい自動化の道が拓けるかと思うのでぜひ検討して頂けたらと思います。









