 運営会社
運営会社
first/last_value関数を使った株価(スナップショット)データのモデリングをThoughtSpotで行う方法
AkimasaKajitaniです。
データ分析の際、各期間の最初と最後を取りたいようなデータというものがあります。例えば倉庫の在庫数などは月初または月末の在庫を知りたい、といった要望があるかと思いますし、株価などは取引開始の時の株式の金額、取引終了の時の株式の金額を、始値、終値といった定義でみます。
これらはいわゆるスナップショットデータ(ストックデータ)と呼ばれることが多いかと思いますが、これらをどうやってThoughtSpotでモデリングすれば良いのでしょうか?売上データなどのトランザクションデータとは異なり、少し注意が必要です。
今回は株価データを元にモデリングをしてみましょう。
株価データとは?
まず、株価データはどのように構成されるのか見てみましょう。以下は日経平均のデータです。
| 日付 | 始値 | 高値 | 安値 | 終値 | 前日比 | 前日比% | 売買高(株) |
|---|---|---|---|---|---|---|---|
| 2026/02/19 | 57,472.08 | 57,709.82 | 57,362.01 | 57,467.83 | +323.99 | +0.57 | 2,322,600,000 |
| 2026/02/18 | 56,734.27 | 57,392.89 | 56,734.27 | 57,143.84 | +577.35 | +1.02 | 2,269,460,000 |
| 2026/02/17 | 56,819.37 | 56,926.24 | 56,135.12 | 56,566.49 | -239.92 | -0.42 | 2,274,570,000 |
| 2026/02/16 | 57,212.97 | 57,219.20 | 56,748.18 | 56,806.41 | -135.56 | -0.24 | 2,470,480,000 |
出典:https://kabutan.jp/stock/kabuka?code=0000&ashi=day
この中でも、始値、高値、安値、終値については以下のような定義となります。
- 始値は、その期間に最初についた価格
- 高値は、その期間で最も高く取引された価格
- 安値は、その期間で最も安く取引された価格
- 終値は、その期間に最後についた価格
これを毎日のデータで考えると、その期間というのは「その日」ということになります。一方で、これを週で見たい、となったら「その週」に変える必要があります。高値、安値は、最大値、最小値なので、集計は簡単で、どのようなソフトでも持っている最大値、最小値を出力する関数で事足ります。一方、始値、終値は、その期間の最初と最後の値を取らないといけません。
まとめると、集計は以下のように行う必要があります。
| 項目名 | 集計方法 |
|---|---|
| 始値(Open) | 始まりの値 |
| 高値(High) | 最大値 |
| 安値(Low) | 最小値 |
| 終値(Close) | 終わりの値 |
ThoughtSpotでの集計方法
ThoughtSpotではデフォルトの集計方法、という設定項目がモデルにあります。モデル画面の以下のスクショの「アグリゲーション」がそれに該当します。
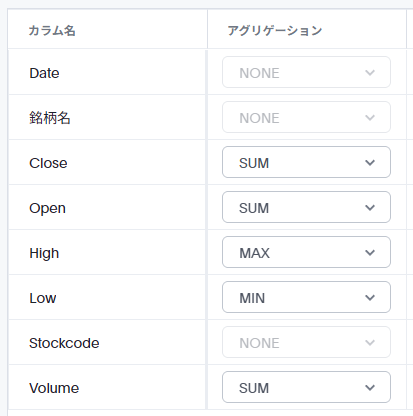
ここを適切に設定すれば、項目を検索ワードに指定した時点でここで設定した方法で計算してくれます。しかしよく見ると、最初の値、最後の値といった設定はありません。
このような状況に対応するために、ThoughtSpotでは、first_value関数、last_value関数が用意されています。例えば、上記データであれば、始値(Open)を以下のように計算することができます。
Open_first:
first_value ( sum( Open ), query_groups ( ) , { Date })
終値は以下のような計算式になります。
Close_last:
last_value ( sum( Close ), query_groups ( ) , { Date })
それぞれ項目名は、Open_first、Close_firstとしておきます。これにより、以下のように作成が可能です。
検索キーワード:

検索結果(ピボットテーブル利用):
また、ThoughtSpotは、時間バケットと呼ばれる時間の単位を容易に切り替えが可能です。これにより、推移グラフにおいて自由に年単位、月単位、週単位、日単位などを行き来することができます。
例えば、以下は日単位の株価です(このデータで一番詳細な粒度です)。
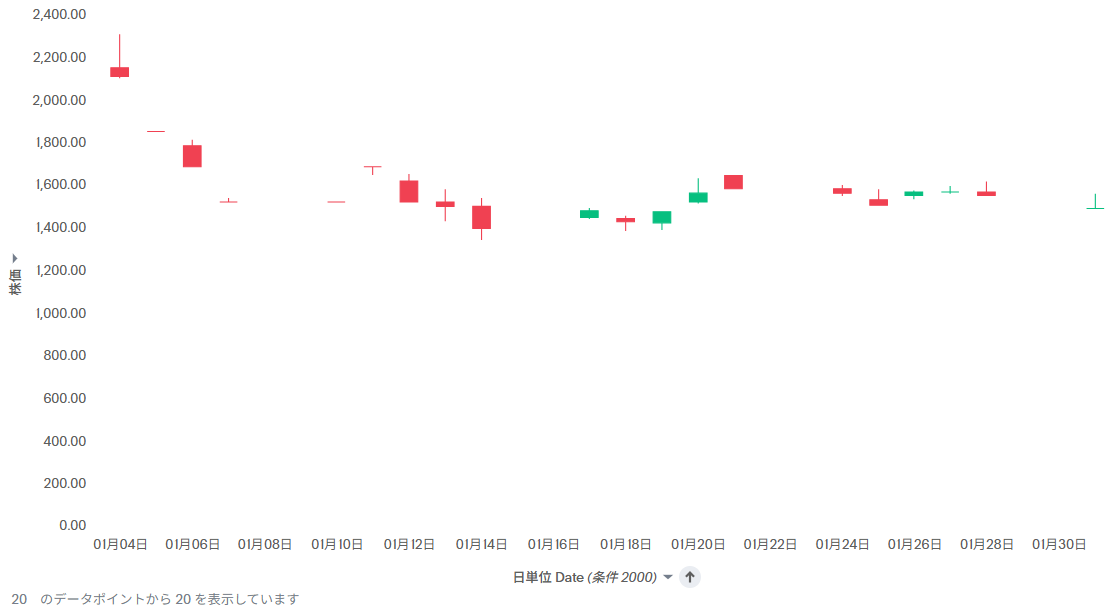
ここで、x軸の▲をクリックすると、以下のように時間のバケットの変更が可能です。

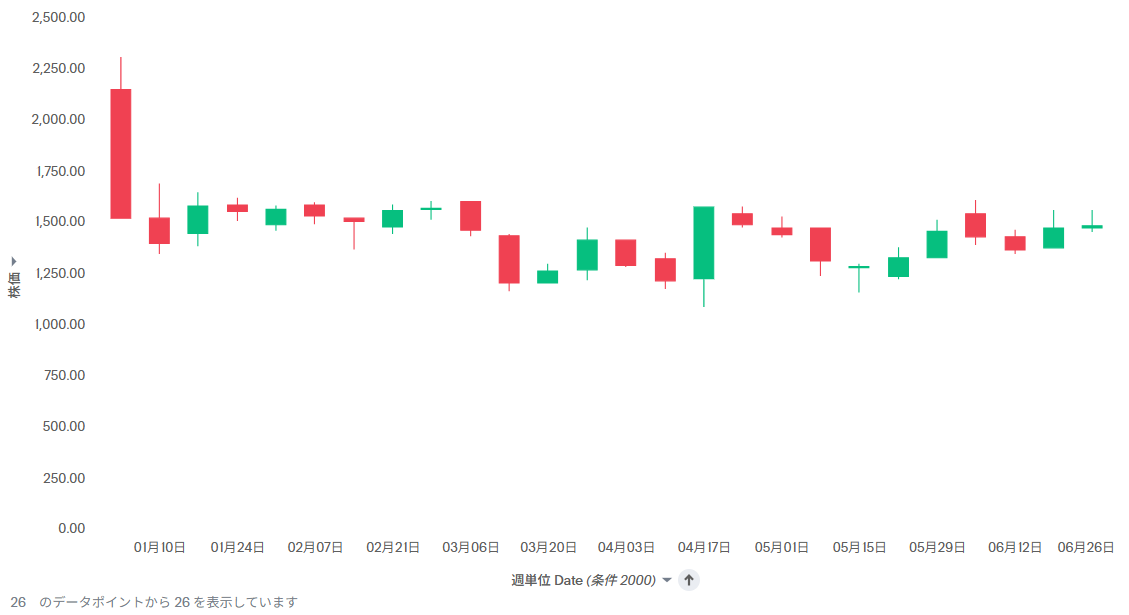
例えば、週単位にしてみました。
厳密に考える場合
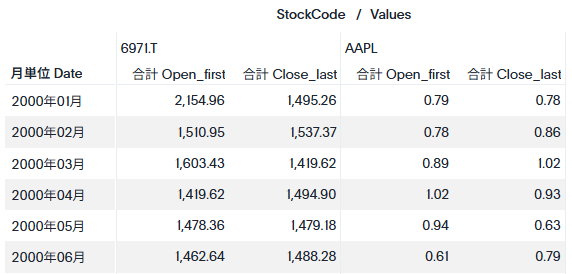
ところで、株式の市場が異なる場合、以下のように始まりの日が異なることがあります(例えば、以下の表で見ると、6971.Tは日本の市場で、AAPLはアメリカの市場なので株式のやり取りの開始日が異なり、2000/1/3の6971.Tは空白(データなし)となっています)。
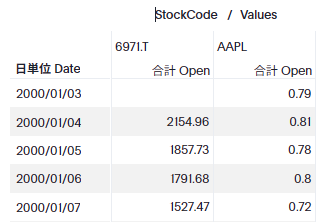
例えば、ここで1月の始値の平均を取りたいといった場合、1/4の6971.Tと1/3のAAPLの平均を取りたいとします(通貨が異なりますが、今回は無視しましょう。ここでは話を簡略化するために同じ通貨という前提で考えてください)。この場合、StockCodeを検索キーワードから抜き、先程の数式に「平均」キーワードを付加します。これにより以下のような検索キーワードとその結果を見ることができます。
検索キーワード:

検索結果:
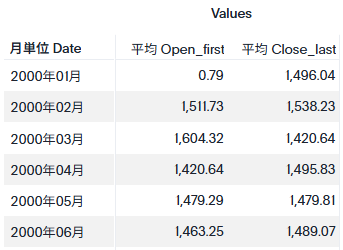
上の表から、1月のOpen_firstがうまく取れていないように思います。見た感じ、0.79という値が入っているためAAPLの1月3日分のみで平均を取った結果となっているようです。これは、StockCodeを無視して日付の中で一番古い日付のみを使って計算をしているからです。それでは、StockCodeごとに古い日付を取り、その平均を取るにはどうすれば良いのでしょうか?
first_value_in_period、last_value_period関数
実は、ThoughtSpotにはfirst_value、last_valueと似たような関数がもう一つ準備されています。first_value_in_period、last_value_period関数という関数です。
これらの関数は、first_value、last_valueに対して4番目のオプションパラメータが追加されており、追加のパーティション列を指定することができます。
Open_first_period:
first_value_in_period(sum(Open),query_groups()+{StockCode},{Date},{StockCode})
Close_last_period:
last_value_in_period(sum(Close),query_groups()+{StockCode},{Date},{StockCode})
ちなみに、「query_groups()+{StockCode}」は、クエリに含まれる項目に対して強制的に「StockCode」も含めてクエリするということです。また、第四変数の「{StockCode}」は、追加となるパーティションを示しています。
これにより、以下のような検索キーワードを設定します。

結果は以下のとおりです。複数のStockCodeの平均値が計算されています。
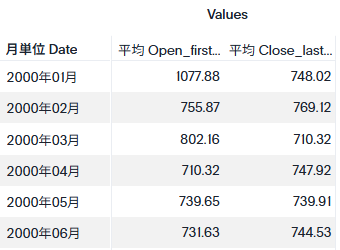
periodを使うかどうか、どのパラメータをどの変数で使うか、などはある程度パターン化して覚えたほうが良さそうです。
別のパターン(日付が統一されていない場合)
各市場の差を無視して、いずれかが一番古い場合に存在しない日付は空白にしたいとします。その場合は、以下のような式を使います。4番目の引数に指定がないため、全体で一番古い日付のみを基準とし、その日付に値がない場合は、Nullとなります。
first_value_in_period(sum(Open),query_groups()+{StockCode},{Date})
以下のような検索キーワードにします。

以下のように、左側は以前の数式で、右側が先程作成した計算式によるものです。確かに6971.Tの2000年1月の株価は空白(NULL)になっています。これは、AAPL側の方で2000年1月3日に値が入っていますが、6971.T側は2000年1月4日スタートになっているため、2000年1月3日の値がないのでNULLとなっている、ということです。
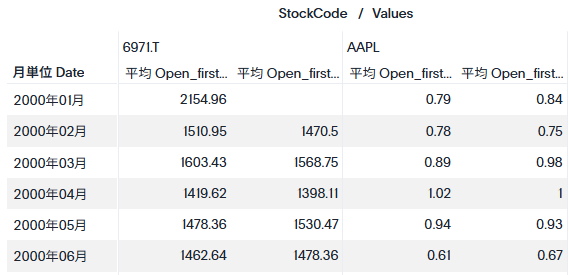
ほしいパターンによって数式を使い分けていただければと思います。
モデルと検索のどちらに計算式を配置すべきか?
もう一つ、重要なテーマについてお話します。
ThoughtSpotでは、データの検索時に数式を追加することが可能です。つまり、以下のように「データの検索」画面から「追加」ボタンで数式を追加することができます。
この場合、あくまでこの検索画面でのみ使える数式です。分析をする際、様々な数式を使うことがありますが、ワンショットの分析の際はこの画面で数式を作成することで、自分だけのものとして利用が可能です。一方で、始値、終値、といった項目は常に最初の値、最後の値を取るべきで、決して合計するものではないため、モデルに計算式を配置し、元々あった「始値」「終値」は各分析者に見せないのが望ましいです。つまり、分析者が誤って始値、終値を合計しない、ということが肝心です。
このように、基本的な使い方が決まっている場合はモデル側に数式を設定します。これにより、分析者が誤った集計を行わない、という利点があります。
モデル作成の場合、以下のようなデータモデルエディターで行うことになりますが、ここに「数式」という項目があるので、ここで計算式を設定することが可能です。
これによりモデルレベルで計算式を定義できるため、各分析者がまちまちの数式を作成して使うことを避けることができ、結果として分析の精度があがる、ということになります。
まとめ
今回は株価のデータを元に、スナップショット(ストック)のデータをThoughtSpotで可視化する時の方法についてご紹介しました。
これは、倉庫データ(月末在庫)や、会員データ(月末会員数)、銀行の残高(月末時点の残高)など、その時の状態を記録しており、単純に合計するとNGなデータであれば同様の対応が可能です。ぜひ応用して使っていただければと思います。
ちなみに、6971.Tは弊社グループ会社の京セラの株式コードです。
参考
- Last_value and first_value functions
https://docs.thoughtspot.com/cloud/26.2.0.cl/semi-additive-measures-value
- Last_value_in_period and first_value_in_period functions
https://docs.thoughtspot.com/cloud/26.2.0.cl/semi-additive-measures-period
ドキュメントにはその他の例も書かれているので、要件に応じて関数をうまく使うようにしてください。
※ThoughtSpotバージョン 26.3.0.cl-80時点の情報です
![【Alteryx関数シリーズ】数学関数の使い方[2025Ver.対応]](https://newssdx.kcme.jp/wp-content/uploads/2020/07/Alteryx関数キャッチ用-300x192.png)









