 運営会社
運営会社
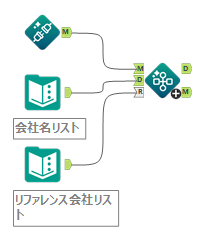
Alteryxツールアイコン「表記標準化ツール」(Precision Match Tool)をご紹介します
 表記標準化ツール(Precision Match Tool)
表記標準化ツール(Precision Match Tool)
[GenAI]カテゴリの[表記標準化]ツールを紹介します。
概要
Precision Match(表記標準化)ツールは、Designerのファジーマッチツールのように、文字列データに対してあいまい一致を行い、マッチングリストとマッピングテーブルを作成するツールです。
マニュアルによると、以下のようなことができるようになっている、とあります。
Perform a fuzzy match-like operation on string data to standardize different variations of the same phrase to a single value.(文字列データに対してあいまい一致のような操作を実行し、同じフレーズのさまざまなバリエーションを単一の値に標準化します。)
つまり、Designerのファジーマッチツールと同じことをLLMを使って行う、ということになります。
このツールを使うためには?(契約関係)
本ツールはエディションベースの契約(Alteryx Oneでの契約)かつ、AI Builderのオプション契約がある場合のみ、LLMリストが取得されます(AI Builderは、Intelligence SuiteとGenAIツールが利用できるオプション契約です)。
また、ベーシックユーザーロールの方(Basic Creator)は利用できません。フルユーザーロール(Full Creator)の権限が必要です。
入出力
入力
- M入力
LLMのモデル入力用インプットです。「LLM上書き設定」ツールの出力を接続してください。
- D入力
実際の「Precision Match」を行いたいデータを入力します。
- R入力
オプション入力です。正規化したときにこの入力にあるデータに合わせこんでいくことになります。
出力
- D出力
D入力に対して本ツールで作成したマッピングテーブルを適用した結果が出力されます。
- M出力
マッピングテーブルが出力されます。
設定項目
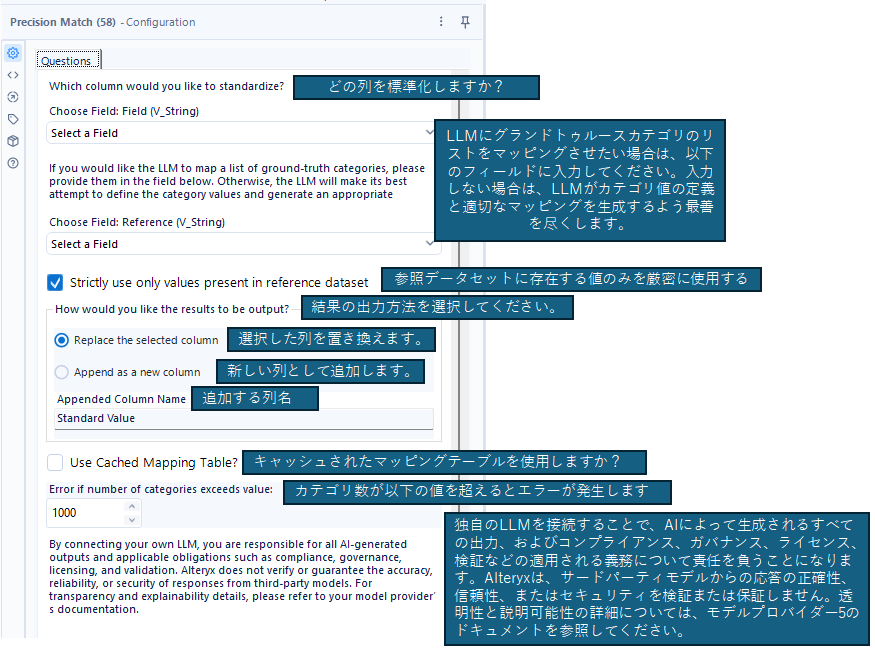
こちらが設定画面です。
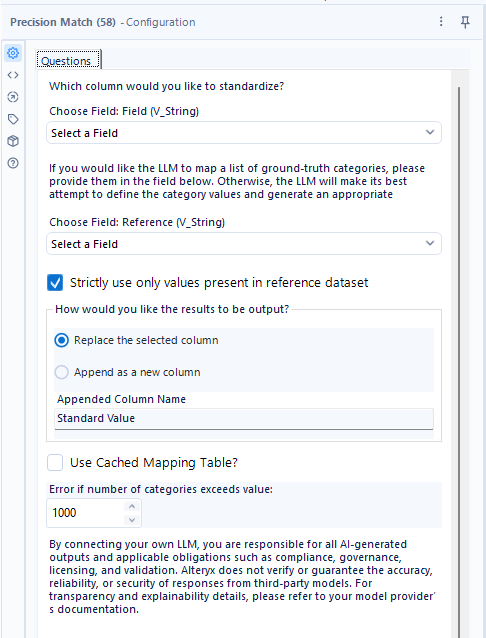
UIが全部英語なので全て翻訳してみましょう。
使い方
それでは実際のサンプルを見てみましょう。今回はPrecision Matchのサンプルワークフローを見て、どんなことができるか見てみましょう。
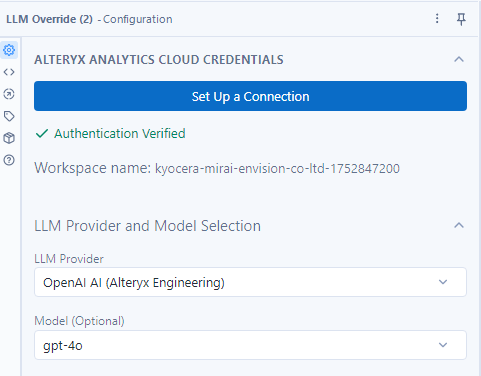
なお、今回のモデルの設定(LLM設定上書きツール)は以下のとおりです。
例1:Standardizing Date(日付データ)
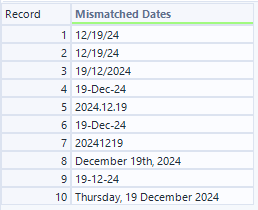
今回のインプットとしては様々な日付データが入ってきています。
インプット(D入力)
設定
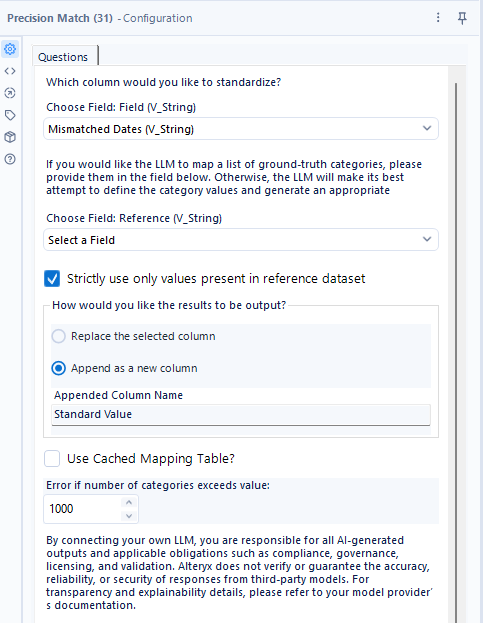
設定はほぼChooseFieldくらいですが、今回は結果を付加するため「Append as as new column」で設定しています。
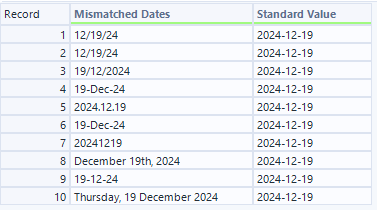
アウトプット
- D出力(D入力に対して標準化したデータを付加したデータ)
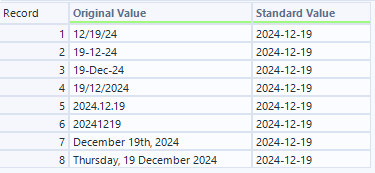
- M出力(LLMからのマッピング出力)
実際に使うのは、D出力側でしょうか?M出力はあとで再利用するために利用可能です。実際、LLMのトークンの消費やワークフローの実行速度を考えると、事前にマッピングデータをこのツールで作成しておき、本番ではマッピングデータを使う、としたほうが理想的かと思います。日付くらいならマッピングテーブルも現実的でしょうか・・・。
例2:Standardizing Time(日時データ)
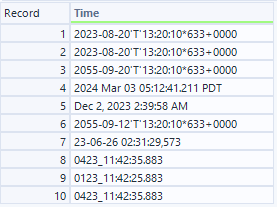
データとしては例1と同じく様々な日付と時間データが入ってきています。
インプット(D入力)
設定
設定はほぼChooseFieldくらいですが、今回も結果を付加するため「Append as as new column」で設定しています。
アウトプット
- D出力(D入力に対して標準化したデータを付加したデータ)
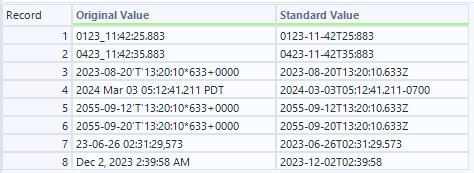
さすがに、「0423_11:42:35.883」みたいなデータは標準化できてないですね。ただ、かなり様々な表記を直してくれています。
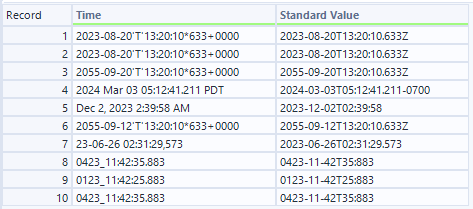
- M出力(LLMからのマッピング出力)
例3:Categorization Max Setting(カテゴライズ最大設定)
これは、上2つのサンプルと異なり、カテゴライズしたときの数を制限する設定を確認するためのものです。
インプット(D入力)
例2と同じです。

設定
この設定では、「Error if number o ategories exceeds value」に4の設定が入っています。これは、マッピング出力側に4つ以上あった場合、出力を抑制する、ということになります。
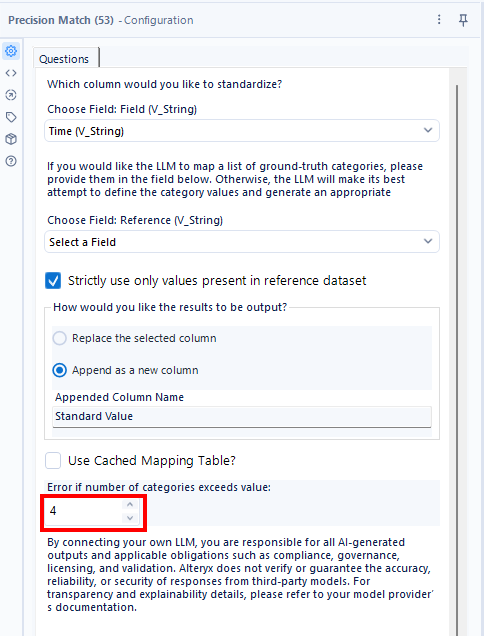
アウトプット
- D出力(D入力に対して標準化したデータを付加したデータ)
抑制されたため、結果はすべてNullになっています。
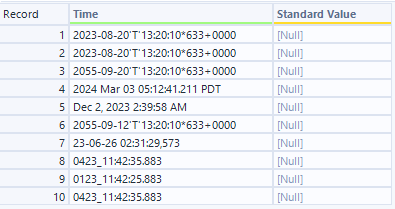
- M出力(LLMからのマッピング出力)
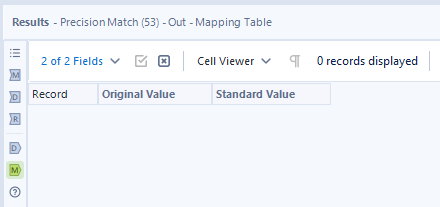
以上のように、意図した通り結果は出ませんでした。
ちなみに、この設定にひっかかると、以下のようにエラーが出るようになっています。
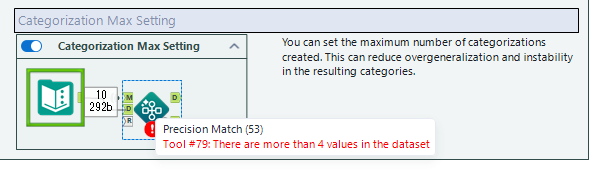
例4:日本語の会社名でやってみました
サンプルデータだけでは面白くないので、日本語で会社名を適当に作って(弊社名含む)でやってみました。みなさん見たいのはこれですよね?
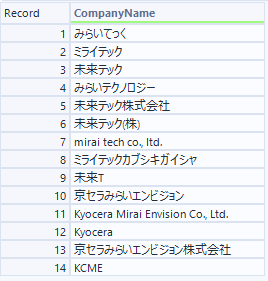
インプット(D入力)
Google Geminiさんに適当にお願いしたら、ミライテックという名称を勝手に作ってくれました。弊社名も別の例として記載してみました。
インプット(R入力)
Rインプットを使ったサンプルはありませんでしたが、ここにデータをいれると、これをリファレンスとしてくれます。
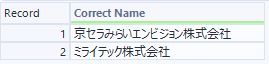
ここで「Kyocera」と入れていないので、結果に「Kyocera」は出てきません・・・。
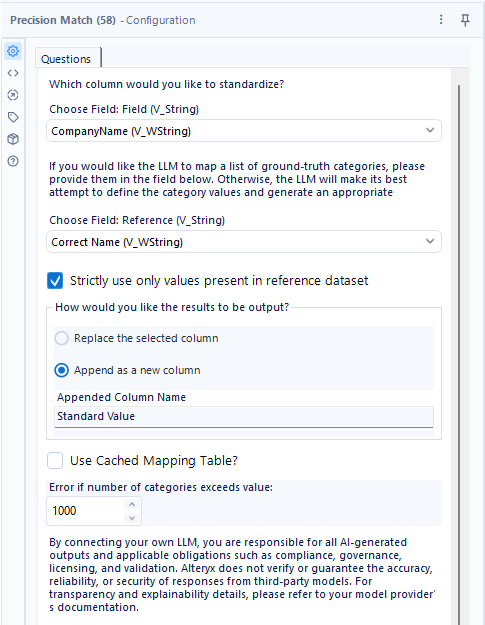
設定
以下の設定では、「Strictly use only values present in reference datset」にチェックを入れているため、リファレンス(R入力)にある名称を使ってマッピングをしてくれます。
アウトプット
- D出力(D入力に対して標準化したデータを付加したデータ)
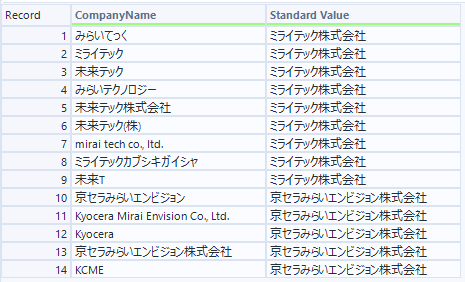
これは、、、すごいですね・・・。弊社の略称すら認識してくれました。Kyoceraはリファレンス入力にないので、弊社名として認識されてしまいました(まぁ、これはこれで意図したとおりです)。
- M出力(LLMからのマッピング出力)
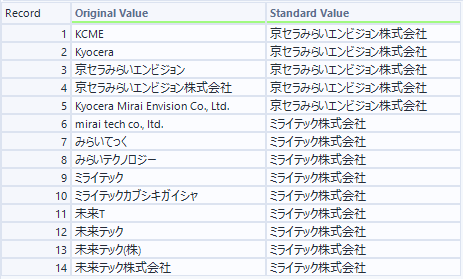
速度的に、この件数でも15秒くらいかかるので、フルのデータに対してこれを毎回実行するのは現実的ではないように思います。基本的にはマッピングフィールドを作成するという用途で使うべきかと思います(LLMコストもばかにならないですし・・・)。
マクロなので中身が見えちゃいますよね?
さて、このツールはマクロなので、中身を見ることができます。
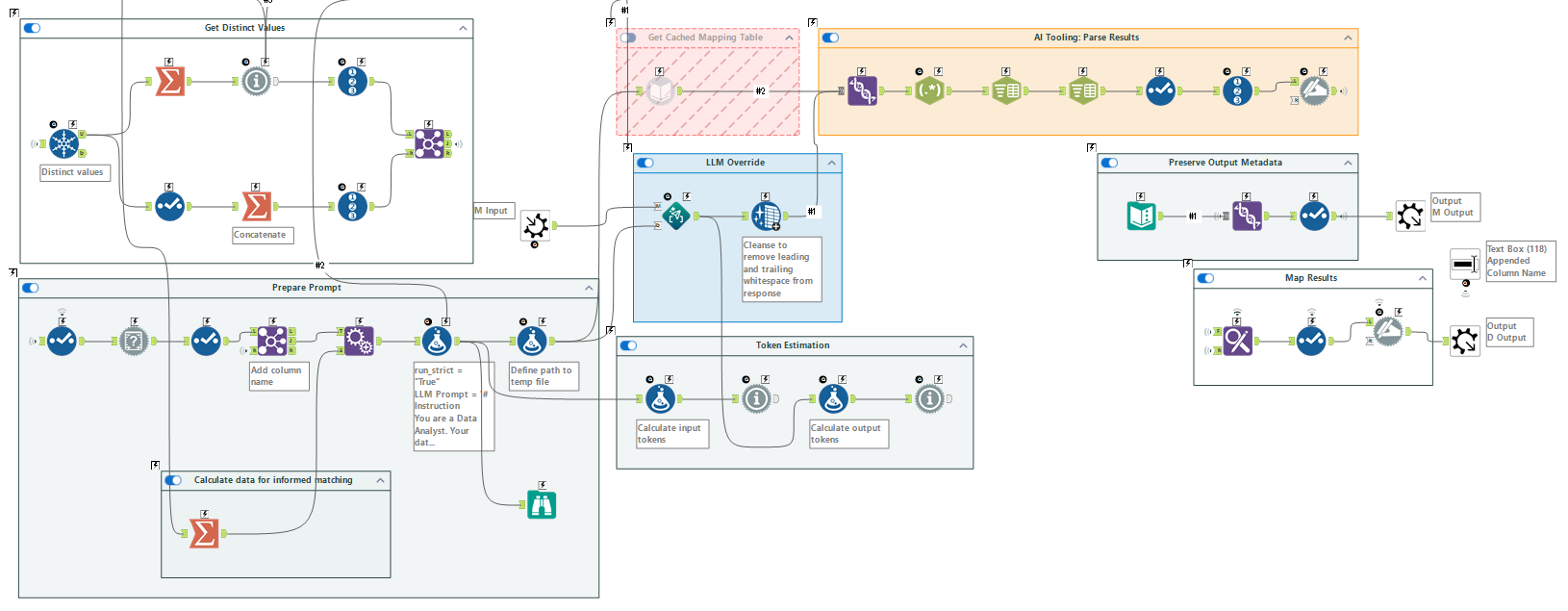
この中のPromptツールに長大なプロンプトが入っています。
# Instruction
You are a Data Analyst. Your dataset is very messy. Specifically, a column called Field have been input inconsistently. You want to map every Field value to a single string that represents that Field so you may perform analysis on it correctly.
Below are all of the unique Field values in a list with the format ["Value1"|...|"ValueN"].
Your task is to produce a table that maps each value in the list to a single value representing that Field. The output table should have two columns: "Original Value" and "Standard Value". You are essentially doing a fuzzy match to help us reconcile this data in such a way that it is consistent and reusable.
After you are done each original value of Field should only have a single representation in the dataset. If there are multiple standards within the dataset, please use the most universally standardized version that you can. If there are multiple values that should be mapped to the same value, please ensure they are accurately represented in the "Original Value" column so they can be mapped to the single standardized value. Please only output the table and output it in pipe separated format. Please also ensure whitespace is preserved. For example, if one of the original values is " hello", that should be represented as a different value from "hello" because of the leading whitespace.
# Input - Field
[Brasil|Brazil|Brazill|Brazl|Bundesrepublik Deutschland|Deutschland|England|Federative Republic of Brazil|German|Germany|Germnay|Great Britain|Japan|Jpan|Nihon|Nippon|The UK|The United States|U.S.A.|UK|US|USA|United Kingdom|United Kingdom of Great Britain and Northern Ireland|United States|United States of America]
The user has also elected to include ground truth for Standard Value - this should help you out immensely! In this case, you are fuzzy matching from some messy data (or potentially clean) to consistent matched values and you need to do your best in determining a match between our incoming values and the reference data that will be provided. The following will be used as your ground truth Standard VAlue for what we will map the Original Values represented in the Field column. You must only use values from the following Standard Value list in your generated mapping:
[United Kingdom|Brazil|USA|Japan|Germany]
If you find that the list of above mapping is insufficient to cover the Original Value field, do not make up additional values. It is okay for the mapping table to be imcomplete, but it is not okay for you to use values that do not appear in the previous list of Standard Value reference items. That being said, you should do your best to find associations between the data that needs to be standardized and the standard values that you are generating.
# Output Format
Format should be pipe delimited for further parsing downstream from this interaction, as below:
Original Value|Standard Value
A|a
B|b
Please do not use any delimiters other than the pipe (|) unless they were already present in the input dataset. For instance, an input value containing quotes can preserve its quotes, but an input value without delimiters should be preserved as it was read in.
長いですね・・・。こんな感じで作っていけば、Promptツールを自由に使いこなせるように思います。
まとめ
- Precision Match(表記標準化)ツールについて説明しました
- 用意されているサンプルワークフローについて解説しました
- 実際に日本語で実行してみました
※Alteryx Designer 2025.1.2.120 時点の情報です










