運営会社
運営会社
Pythonのdifflibで類似度マッチを行うマクロ紹介
![]()
単語の類似度を計算し結合するマクロです。内部的にはPythonツールを使用しています。
概要
Pythonのdifflibを用いて、単語の類似度を計算し、結合するマクロです。
英語であれば、住所や名前、電話番号等、ファジーマッチツールで類似したものの組み合わせを得ることができますが、残念ながら日本語に対応していません。
しかしながら、Pythonのdifflibライブラリにはゲシュタルトパターンマッチングという手法でテキストの類似度を算出する関数があります。このマクロではこのライブラリを使い、英語、日本語を問わずテキストの類似度を計算することができます。
マクロダウンロード
SimilarityMatch_ja fa-download
※CommunityのGalleryには英語版を掲載しております
使い方
設定項目
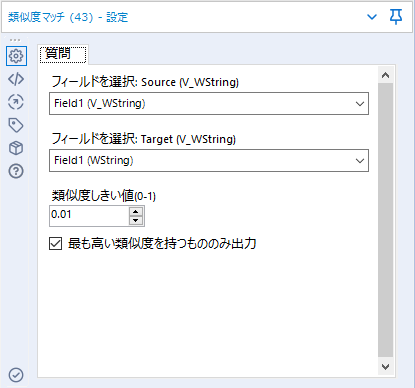
| 設定項目名 | 設定内容 |
|---|---|
| 対象フィールドを選択:Source | 比較元のフィールドを選択します |
| 対象フィールドを選択:Target | 比較したい単語の入ったフィールドを指定します |
| 類似度しきい値 | ここで指定したしきい値以上のT入力のレコードを出力します。0~1の間の値を入れて下さい。一致度0は完全に不一致。1は完全に一致です。 |
| 最も類似度の高いレコードのみを出力する | チェックをつけると、最も類似度の高いT入力のレコードを出力します。つまり、S入力に対してT入兎力のレコードを1つだけ出力します(チェックを入れなければS入力に対してT入力のすべてのレコードが出力されます(フィールド付加ツールと同様の動きになります)。
このオプションを使う場合、「類似度しきい値」は0より大きい値を指定することを推奨します。 |
サンプル
本マクロのサンプルワークフローとなります。
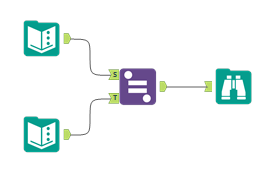
【設定】
類似度しきい値:0.01(0は全く一致していないものになるので省いたほうが良いのでこのような設定にしています)
最も類似度の高いレコードのみを出力する:チェック
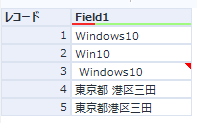
【インプットサンプル】
Source用
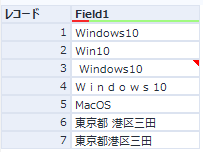
Target用
【アウトプット】
結果は以下のようになります。
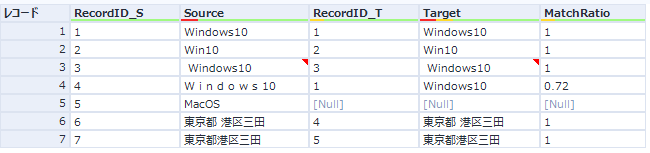
空白などが入っただけであればマッチ度は1(一致)とみなされます(3、6,7行目)。文字に空白が入った「W i n d o w s 10」と空白が全くない「Windows10」も一致度0.72となっています。このあたりは、単に空白をすべて削除しておく、という手もあるかもしれません。
なお、日本語の場合は、事前に半角・全角を統一するなり、カタカナ・ひらがなを統一した方が良い結果が得られるように思われます。
技術情報
作成・動作確認バージョン
Alteryx Designer 2021.1.4.26400
参考情報
difflib
https://docs.python.org/3/library/difflib.html fa-external-link
difflibのSequenceMatcherは、ゲシュタルトパターンマッチングというアルゴリズムで二つのテキスト間の類似度を計算します。
サンプルワークフローダウンロード
類似マッチ_Sample_workflow fa-download
注意事項
- 本マクロに関する不具合、および利用したことによる損害については一切の責任を負いません
- 不具合報告、ご要望などあるようでしたら弊社フォームにて投稿頂ければ、本マクロの改良、機能追加など検討させて頂きますが、弊社都合にて行いますので要望の反映などのお約束はできませんのでご了承ください
- 有償でのカスタマイズ要望などあるようでしたら、弊社フォームにてお申し込みください。別途お見積りさせて頂きます