 運営会社
運営会社
【AlteryxTips】初心者向け 正規表現ツールの考え方とコツ
初めに
はじめまして、こんにちは! y-tanakaです!
この記事では、データ分析初心者の私が、Alteryxを勉強していく中でポイントだと思った知識についてまとめます。
ですので、内容は技術的というより、私と同じようにAlteryx勉強を始めたばかりの人向けのものとなっております。
今回は正規表現ツールについてです!
私自身まだ正規表現を完璧にマスターしたわけではありませんが、Alteryxを勉強していく中で知った、正規表現ツールの使い方のポイントなどをまとめていきます。
 正規表現ツールとは?
正規表現ツールとは?
まずは簡単に、正規表現について解説します。
正規表現とは、文字列を特定の記号・文字の羅列で表現するもののことを言います。
例えば、任意の数字一文字を表すには「\d」、のように書きます。
詳しい使い方については、こちらの記事をご参照ください。

私は正規表現を完璧に覚えているわけではないので、いつも調べながらこのツールを使用しています。
そうして使っていく中で、このツールの使い方のコツや考え方が少しわかってきたので、ここではそれを3つ紹介していきます。
正規表現ツールの使い方のコツ・考え方
① {}で括ると回数を指定できる
正規表現のすぐ後ろに{}で括った数字を記述することで、「直前に書いていた正規表現を何回分判定するか」を指定できます。
例えば、
「数字4桁」は「\d{4}」と表記します。
簡単なデータで試してみましょう。
例えばこんな文字列があるとします。
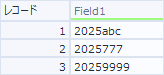
1には数字4桁と文字が3つ。
2には数字が7桁。
3には数字が8桁。
といった感じです。
このデータに、正規表現ツールで「数字4桁を"1111"に置き換える」といった設定をしてみます。
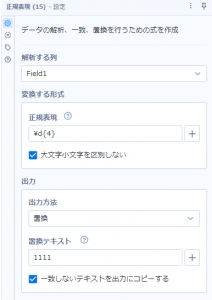
実行してみると、結果はこんな感じです。
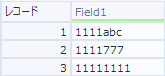
1では、「数字4桁と文字3つ」のうち、最初の数字4桁が適合して「1111」に置き換わる。
2では、左から数えて数字4桁分のところが適合して「1111」に置き換えられる。残りの部分は「数字が3桁」なので適合せず、そのまま。
3では、左から数えて「数字4桁」のところが適合して「1111」に置き換えられ、残りの部分も「数字4桁」なので適合し「1111」に置き換えられる。
といった結果で出力されました。
これを応用すれば、例えば
「~~~~~111-2222ーーーー」のような長い文字列の中から、
郵便番号に該当する部分を「\d{3}-\d{4}」と書いて抜き出す、なんてこともできます!
ただし、この例のようにデータの中から指定した文字列を抜き出す「解析」機能については、正規表現の書き方に注意があります。
これが次に紹介するポイントです。
② 「解析」では、分けたい・取り出したい部分を()で区切る
正規表現ツールを使う際、「解析を使って文字列を取り出したいのに、正規表現を書いても『エラー: 解析するものがありません。完全な式を入力してください。』と表示が出てきて解析ができない!」と困ることがありました。
例えばこんなデータがあるとします。
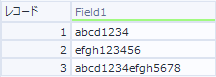
このデータに対して「数字で書かれた部分を取り出したい」時、
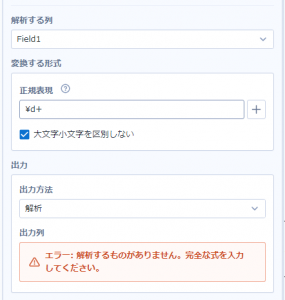
ただ「数字何文字か」を表す正規表現「\d+」と書いても、下の方にエラーが出てしまいます。
この時知ったのが、『解析を使う時には、分けたい・取り出したい部分は()で区切る必要がある』ということです!
正確には、解析はグループ化されたものに対して行われるので、()でグループ化をしないといけない、という意味です。
実際に、()を付けてみると、
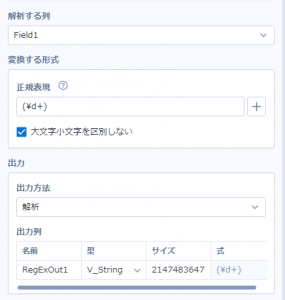
このようにエラーの表記は消え、実行すると
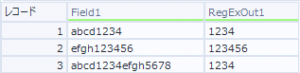
きちんと、「数字何文字か」を取り出すことができました!
ちなみに、解析ツールでは、「最初に一致したものだけ」が取り出されるので、レコード3のように「文字 数字 文字 数字」のように書かれていても、取り出されるのは最初に一致した数字の部分のみになります。
また、グループ化は一か所に限らず、例えば
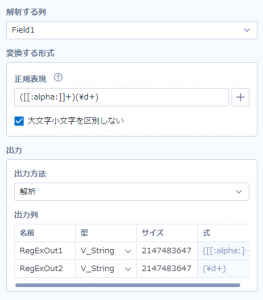
このように、「文字が何文字か」のグループと「数字が何文字か」のグループ、と書けば、

実行した時に、文字の列と数字の列として、二つ取り出すことができます。
レコード3については、先ほどと同じように、初めに適合したもののみが取り出されています。
さらに応用してみます。例えばこんな風に正規表現を書いた時。
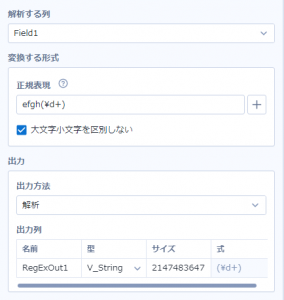
今回は、「efgh」を固定し、その後にグループ化した「数字何文字か」を指定しています。
これで実行してみると、こんな感じで出力されます。
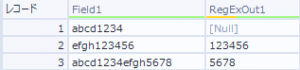
レコード1だけNullになりました。
この正規表現では、「efghの後ろの数字何文字か」をグループ化して取り出す、という動きをしています。
レコード1にはefghという文字列はないので、適合するものがないためNullが出力されます。
このように、特定の文字列の後ろにあるものを指定して取り出すこともできます!
③ トークン化と列分割ツールの違い
詳しい使い方は最初の方に記述した過去の記事を参照していただきますが、要約すると、
「トークン化を行うと列分割ツールのように、正規表現に適合するものを列や行に分割することができる」機能となっています。
そこで、正規表現ツールのトークン化と列分割ツールは何が違うのか、について解説していきます。

例えばこんなデータから、数字だけを取り出して列を作りたい場合について、それぞれのツールでやってみます。
まず、列分割ツールで「-」を区切りにして分割しようとすると
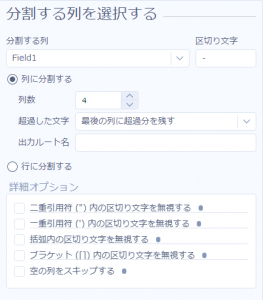

このように、数字ではない「abc」まで取り出されてしまいます。
取り出したいのは数字だけなので、これを消すためにセレクトツールも使わないといけません。

これでは使うツール数が増えてしまい、非効率的で少しめんどうです。
では次に、正規表現ツールのトークン化機能を使ってみます。設定はこんな感じです。
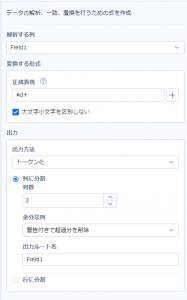
元のデータの中に数字の塊は3つなので、トークン化の設定の中で列数を3と指定します。
これで実行すると、

この通り、数字だけを列として取り出すことができました!これなら、正規表現ツール一つだけで済み、使うツール数を抑えることができます!
ちなみに上記の例は「列として取り出したい場合」でしたが、「行として取り出したい場合」でも同じです。
列分割ツールで行として分割しようとすると、
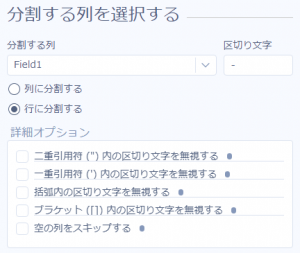
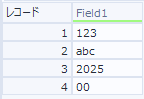
このように、数字以外の文字列も行として取り出されてしまい、取り除くために別のツールを使う必要が出てきてしまいます。
ですが、正規表現ツールを使えば、
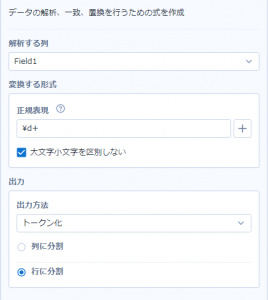

このように、きちんと数字だけを行として取り出すことができます!
・データの中の一部のデータを使う必要があり、それだけを取り出したい場合は正規表現ツール
さらに、この二つのツールの違いはもう一つあります。あまり実務向けではありませんが、これもご紹介します。
先ほど列として取り出したい場合で使った列分割ツールと正規表現ツールの設定を流用します。
前の設定では、分割数を文字列の塊に合わせた数にしていましたが、これを「本来取り出せる数よりも小さい数」に設定するとどうなるでしょうか?
まずは列分割ツールで、先ほどは分割数を「4」としていたのを、「2」に変えてみます。
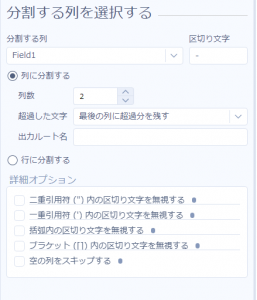
これで実行してみると、

このように、2列目の最後に残りの部分が結合された形で出力されます。
では次に、正規表現ツールの設定を変えてみます。
先ほどは分割数を「3」にしていましたが、これも「2」にします。
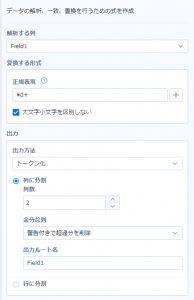
これで実行すると、

このように、適合したものの最初の二つ分のみが出力されます。「00」は切り取られて出力されません。
・正規表現ツールでは、元のデータから正規表現に適合する文字列を分割数で数えた分だけ取り出す
最後に
以上が、私がAlteryxを勉強した中で知った、正規表現ツールの使い方のコツや考え方でした。
初めての投稿で拙いところもありますが、参考にしていただけたら嬉しいです。










