運営会社
運営会社
AlteryxでPDFファイルを読み込んでみます
こんにちはh-wakasugiです。2024年10月から他部門から異動してきました。よろしくお願いします!
コンピュータビジョンカテゴリの「PDFからテキスト抽出」ツールを使用してPDFファイルを読み込んでみます。
コンピュータビジョンカテゴリの説明については以下の記事で紹介しています。

目標
PDFファイルに含まれるテキスト、画像を抽出してみます。
テストに使用するPDFファイルは以下を使用します。
Alteryx Intelligence Suite Data Sheet
実行の流れ
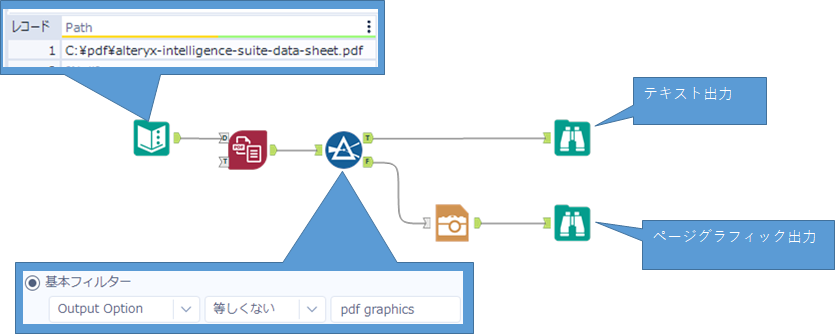
「PDFからテキスト抽出」ツールの設定
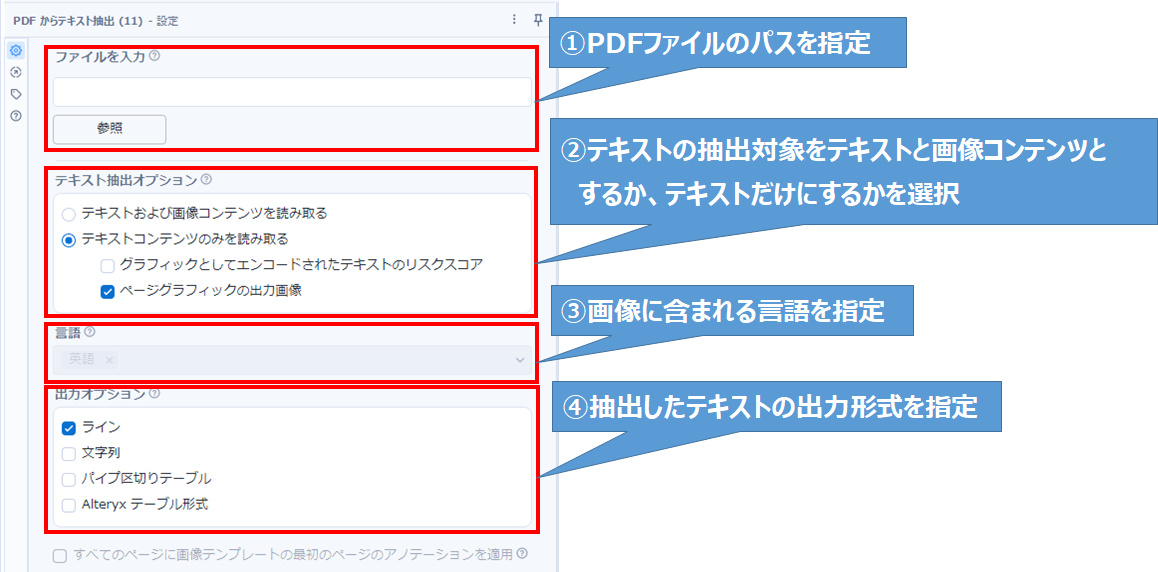
①PDFファイルを指定します。
単一のPDFファイルを指定することも、PDFファイルの格納されているフォルダを指定することも可能です。
オプションの「 D アンカー」は、ファイルパス情報をツールに渡すために使用されます。
今回は、「テキスト入力ツール」を接続して単一のPDFファイルのパスを渡します。
②光学文字認識 (OCR) を使用するかを選択します。
画像に含まれるテキストを抽出する場合は「テキストおよび画像コンテンツを読み取る」を選択します。光学文字認識 (以降、OCRと記載)を使用した抽出を行います。
今回は、PDFファイルに含まれるテキスト、画像を抽出するため、「テキストコンテンツのみを読み取る」と「ページグラフィックの出力画像」を選択します。
③画像コンテンツに含まれるテキストの言語を指定します。
OCR はアラビア語、英語、フランス語、ドイツ語、イタリア語、日本語、ポルトガル語、簡体字中国語、およびスペイン語をサポートしています。
今回は、「テキスト抽出オプション」で「テキストコンテンツのみを読み取る」(OCRを使用しない)としている為、設定不可(グレー表示)となっています。
④抽出したテキストの出力形式を指定します。(複数選択可能)
PDFファイルから抽出したテキストの出力形式を指定します。(各出力オプションの出力例は下記補足参照)
補足)
・ライン
1 行に含まれるテキストを 1 レコードで出力します。
![]()
・文字列
1 ページに含まれるテキストを 1 レコードで出力します。

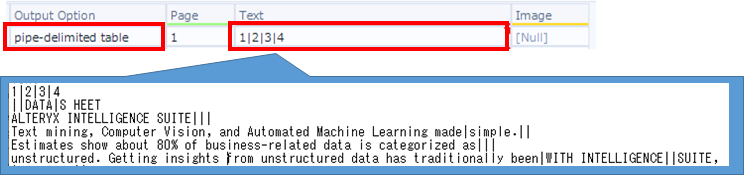
・パイプ区切りのテーブル
1 ページに含まれるテキストを パイプ区切りのテーブル形式で、1 レコードで出力します。
・Alteryx テーブル形式
1 行に含まれるテキストをAlteryx テーブル形式で、 1 レコードで出力します。

実行してみた
◆テキスト出力
「Text」フィールドに読み込んだテキストが出力されます。
出力オプションをラインに設定しているのでPDFファイルの1行が1レコードで出力されます。

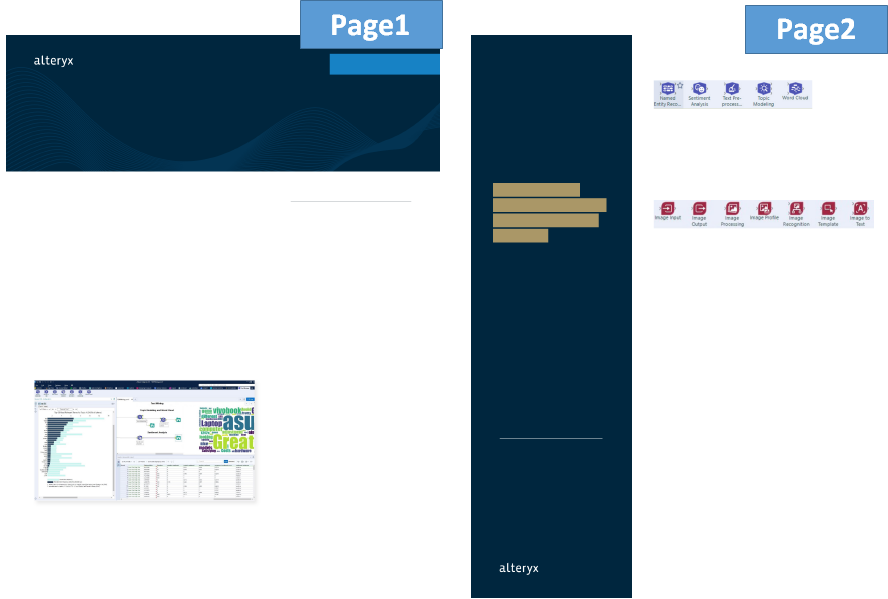
◆ページグラフィック出力
「Image2」フィールドにImage形式でページグラフィックデータが出力されます。

上記のPage1、2を画像表示すると、以下のようにページグラフィックが抽出されています。
今回は、「PDFからテキスト抽出」ツールを使用してPDFファイルからテキストと画像を読み込んでみました。
ツール1つで簡易にテキスト抽出が可能なことがわかりました。
今後、画像からのテキスト抽出、他言語でも試してみたいです。