 運営会社
運営会社
ThoughtSpotウェビナー「SpotMap」(2026年2月)についてご紹介いたします
AkimasaKajitaniです。本ブログ記事は、2026年にSpotMapという新たに始まったウェビナーシリーズの内容についてブログに書いているシリーズです。
本ブログ記事は、2026/01/09 AM0:00(JST)に行われたThoughtSpot社のウェビナー「SpotMap」に関するレポートです。本イベントの録画、スライドはウェビナー登録ページから見ることができますので、よろしければご覧ください。
SpotMapウェビナーって何?
SpotMapウェビナーは、ロードマップをご紹介するウェビナーシリーズとなっており、毎月第一木曜日に開催されます。ThoughtSpotの製品分野として6つあり、年2回ずつ行われる、とのことです。
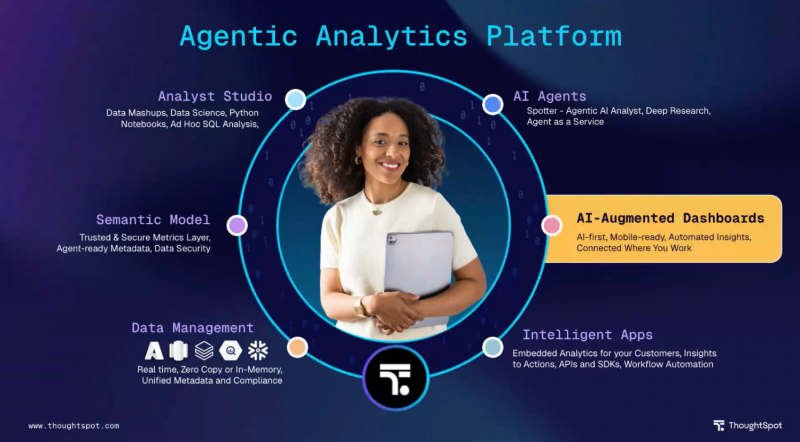
SpotMapへの登録はこちらのリンク からできます。
今回のアジェンダ
今回はSpotter3に絞った内容となっています。
- Spotter3の新機能
- デモ
- ロードマップ(Spotter 3.5)
(今回は、データ管理とAnayst Studioに関してのウェビナーの予定だったように記憶していますが、Spotterの話になったようです)
Spotter3の新機能
Spotterのロードマップの3本の柱
まず、こちらがSpotter3のロードマップの3本の柱とのことです。
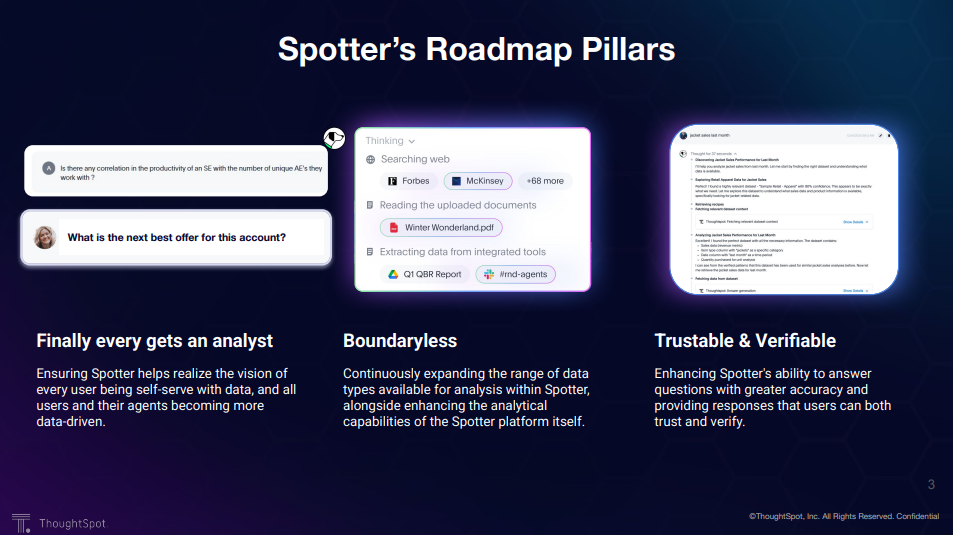
- 全員がアナリストになれる
- AIの力で全てのユーザーがセルフサービスでデータドリブンになれる
- 境界を取り払う
- Spotter内では非構造化データ、構造化データなどデータのタイプに関わらず利用できるようになります
- 信頼性、検証可能性
- AIの行動がすべて透明化されています
実際に使ってみた経験からも、これらは確かに実現されていると思います。
Spotter3とは?

- 構造化データと非構造化データの統合
- 構造化データだけではなく、他のSaaSアプリやインターネット、その他の場所からコンテキストを取り込んで融合し、インサイトを補強できます。
- 新しい行動な分析スキル
- エージェントがPythonコードを記述できます。これにより相関分析や予測が可能となっています。
- また、複数のデータモデルにまたがって質問ができるようになっています。
- 信頼できるパートナーとして
- エージェント(AI)が実行する全ての手順を見ることができます
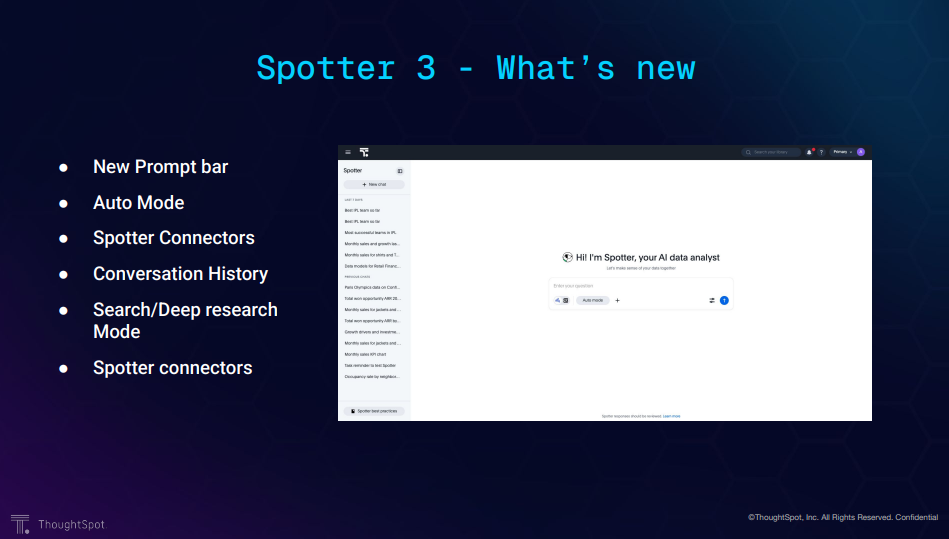
Spotter3の新機能は以下のとおりです。
- プロンプトバー
- UIがかわりました!
- オートモード
- 質問すべきデータを自動的に選択してくれます
- スポッターコネクター(スライドには二回書いてますね・・・大事なことだから?)
- 外部のデータに接続するMCPクライアントとして動作する機能です(MCPサーバーを追加できるということです)
- 会話履歴
- 検索/ディープリサーチモード
- ディープリサーチモードでは、より質問を深堀りしていきます
Spotter 1/2/3比較
Spotter1~3の機能の比較表はこちらのとおりです(プレゼン資料にもありましたが、字が小さくなりそうなのでスクショは貼らず、日本語化しました)。
| 機能 | 説明 | Sage/ Spotter1 |
Spotter | Spotter3 |
|---|---|---|---|---|
| 自然言語を用いた質問に回答する | データの検索や問い合わせを自然言語で行う | ✓ | ✓ | ✓ |
| データリテラシー | データセットとその意味についての説明とコンテキスト | ✓ | ✓ | |
| マルチリンガル | 英語に加えてその他の言語のサポート | ✓ | ✓ | |
| 推論と思考の検証 | Spotterの分析手順とロジックを表示し、透明性を確保 | ✓ | ||
| ReACTによる高い精度 | 回答の自己修正と検証が可能 | ✓ | ||
| AIインサイト(要約) | 分析の概要と洞察を作成 | ✓ | ||
| なぜの質問 | 変更分析を通して、データの変化を説明 | ✓ | ||
| ディープリサーチ | 複数ステップの分析、計画、実行を詳細なコンテキストレポートとしてユーザーに提示 | ✓ | ||
| コードによる高度な分析 | 統計および機械学習モデルや高度な分析のためのコード生成を含んだ、多段階分析が可能 | ✓ | ||
| データモデル選択のオート化(オートモード) | 質問すべきデータモデルの自動的選択 | ✓ | ||
| MCPコネクター | Spotterが利用するMCPをカスタマーが追加可能 | ✓ |
ウェビナーの中では、最も重要なのは「MCPコネクター」である、と言っています。これを使うことで、外部のコンテキストを色々と取り込めます。また、外部のSaaSなどにアクションを行うこともできます。
自動モードについては、複数のデータを切り替えて質問ができる、ということのようです。
実際に使った感想として、Spotter3は以前に比べて精度が非常に高くなっています。その分速度的なところは遅くなっているというのは実際あります。これは、どのLLMも同様の方向性になっているので、世の中のトレンドとあっているということかと思います。また、この精度アップについてはReACT、および推論と思考の検証という機能追加によるところがポイントかと思います。データへの問い合わせを行った際、以前のSpotterでは「できました!」と、出てきた結果を見てみると、中身が空っぽだった、ということがちょくちょくありました(これは、検索トークンがマッチしなかった時の現象です)。これをSpotter3ではちゃんと検知してくれて、データがうまく取得できない場合に取得方法を変えて再取得に行きます。そこからだいたいPythonコードで処理が行われることが多いのですが、結果としては正確な情報が得られる可能性が以前より大幅に高くなっています(失敗が入る分、時間がかかっている、ということです)。
これは、Spotterの構成となっています。
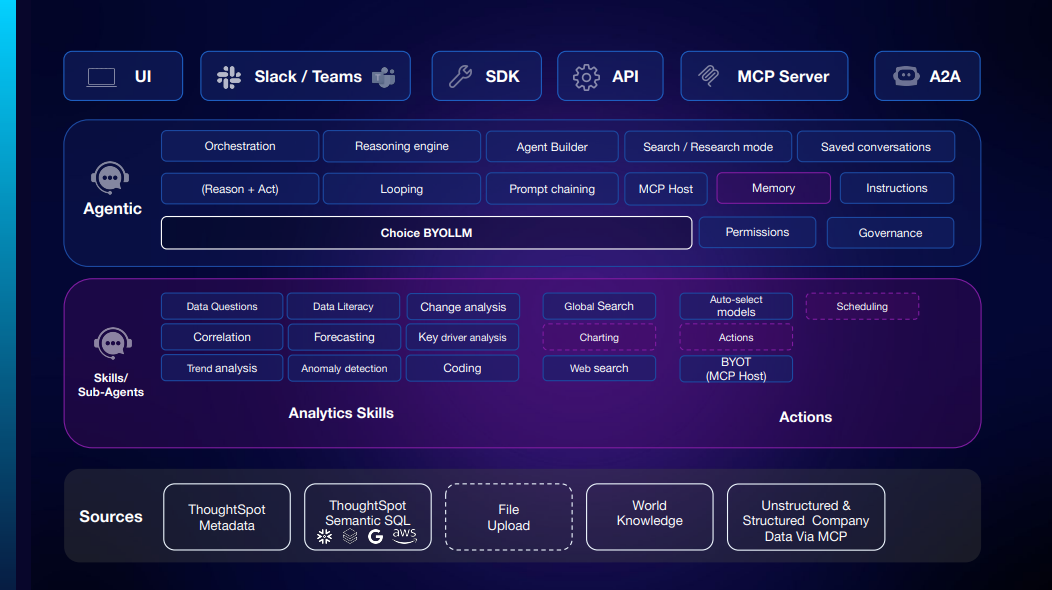
これを見て個人的に思うのは、変更分析、というのは他のLLMなどではLLMが行う範囲での分析となっていて、ThoughtSpotが元々持っている変更分析に比べると精度等いまいちかな、と思うのですが、Spotterの場合は元々ThoughtSpotが持っている変更分析の機能をそのまま使うことができるため、ハルシネーションは起きない、ということです。しかも自分自身で好きなように深堀りでき、非常に便利な機能なので、これだけでもSpotterを使う理由になります。
また、点線の部分はまだ実装されていない機能のようで、チャート作成、アクション、スケジューリング、ファイルアップロードが未対応になっています。チャート作成は、検索トークンで取得できたものはそのままThoughtSpotのチャート機能が使えますが、Pythonのコーディングした結果はチャートで表示できない、という部分を指していると思います(このあたりはSnowflake Intelligenceも同様の課題を持っていて、SQLで得られた結果はグラフにできるけど、Pythonの結果はグラフに書けないということです)。
また、26.2の段階では、Web SearchはMCPサーバーを追加しないと動作しないと思います。
一番上のアクセスレイヤーについては、様々なところからアクセス可能になっています。UIだけではなく、APIやMCPサーバー、さらにはSlacl/Teamなどのチャットアプリからもアクセスできるのは面白いポイントかと思います。
Spotterの(他のAIエージェントと比べた時の)違い
「What makes Spotter different」というスライドを日本語化してみました。たびたびこの内容は、いろんなところで聞かれます。
| 特徴 | 内容の要約 |
|---|---|
| 推論と分析(単なるQ&Aではない) | 単に回答を出すだけでなく、ビジネス上の問いを理解し、それをデータへの問いに分解して分析を実行します 。 |
| データの境界がないインテリジェンス | 構造化データに限定されず、SaaSアプリ、非構造化データ、Web上の知識を組み合わせて全体像を把握します 。 |
| 根拠に基づいた決定論的なインサイト | 確率的な推測ではなく、データという事実に裏打ちされた、検証可能なインサイトを提供します 。 |
| AIとBIのシームレスな融合 | 対話型の分析と、従来のデータ探索(DIYモード)を自由に行き来してコントロールできます 。 |
| 広範な分析スキル | 質問への回答、コード生成、変化分析、予測、複雑な計算など、多岐にわたるスキルを自動で使い分けます 。 |
| 誰でも検証可能 | SQLを知らなくても、Spotterが取った全てのステップを自然言語で説明させ、内容を検証できます 。 |
| 会話を超えたアクション | 分析結果に基づき、JiraやAsanaのチケット作成、Slackへの投稿など、次のアクションを直接実行できます 。 |
| クラウドデータウェアハウスに依存しないユーザー環境 | SnowflakeやGoogle、Databricks等で動作し、ビジネスユーザーに最適化されたインターフェースを提供します 。 |
| エンタープライズ級のセキュリティ | 行・列レベルのセキュリティ設定を保持し、各ユーザーの権限範囲内でのみ動作します 。 |
| 柔軟な埋め込み | SDK、API、MCPフローを通じて、独自のアプリケーションやワークフローに組み込むことが可能です 。 |
ちなみに、私の考える特に重要な差別化ポイントは以下のとおりです。
「AIとBIのシームレスな融合」については、会話の中で得られたチャートは、ThoughtSpotの持つドリルダウン機能を使ったり、グラフの体裁を変えたり、フィルタをかけたりなど自分でさらに深堀りできますし、ライブボードに追加して後で再利用することも可能です。
「誰でも検証可能」については、ThoughtSpotの持つトークンサーチ(検索キーワード)の機能がポイントで、このキーワードを見ることで正しくデータが検索されているのか、というのをSQLを知らなくても判断できることがポイントです。
「会話を超えたアクション」については、MCPサーバーを追加できる、というのが非常に大きなポイントかと思います。
「クラウドデータウェアハウスに依存しないユーザー環境」については、Spotterを使いたいから特定のクラウドデータウェアハウスにデータを集約する必要が「ない」ことです。つまり、どのクラウドデータウェアハウスに格納されていてもSpotterを使うことができる、ということで、ベンダーロックインしない、ということです。
デモ
ウェビナーではここからデモに移っています(動画では20分くらいからデモが開始されます)。デモで行ったことは以下の内容です。ちなみに、シナリオは「私がパリの不動産管理会社オーナーで、Airbnbに物件を掲載したいとします。夏に向けて準備しておきたい」となっています。
- オートモードで、自分のやりたいことに沿って使用すべきデータをSpotterに提案してもらう
- 信頼度付きで2つのモデルが提示されたのは驚きでした
- 特定の地区のレビューコメントを分析して、人々が一般的にどのようなアメニティについて語っているのか質問
- 半構造化データに対してのクエリで、レビューコメントを分析し、どのようなことが物件の高評価に繋がっているのかを提示してくれました。これは取得したデータに対して、自動的にPythonで分析が行われています
- 今後開催されるイベントを調べるために、Confluenceを検索させます
- 仕込みとして、ThoughtSpot社内のConfluenceにWEBの記事をいくつか準備したようです
- いわゆる、MCPサーバーに対しての問い合わせも問題なくこなせる、というデモですね
- まとめた内容をSlackに送信させる
- 月曜日にこの件についてパートナーと話すことを思い出させる Asana タスクを作成する
- これもMCPサーバーへのアクションです。検索ではなく、タスクの作成、ということも可能です
ロードマップ(Spotter 3.5)
今後のSpotter 3.5のロードマップです。

今後の四半期で取り組む内容がSpotter 3.5とされています。
- 簡単に導入できるSpotter3.5
- エージェントのインストラクション
- 現在はモデルに対してのインストラクションが設定可能ですが、エージェントにも設定できるようになるようです
- エージェントの出力の共有
- ThoughtSpot内でのエージェントの出力結果を共有できるようになる
- CSVアップロード
- エージェントのインストラクション
- 自己学習エージェント
- ライブボードや会話から学習を行い、よりパーソナライズされる
- カスタマイズSpotter
- 「Customs Partners」という名称で現在進んでいるが、自社の業務に合わせてキュレーションされたものを作成できるようになる。例として、営業アナリスト、マーケティングアナリストといった機能ベースのアナリストやプロジェクトベースのアナリストを立ち上げることが可能になるようです
Q&Aの興味深い質問
- 音声データの活用
- 予定はあるが、MCPサーバーを追加すれば今でもできます
- Spotter3でできないことは何ですか?
- 非常に複雑な複数のデータモデルを大規模に組み合わせる場合、さらなるチューニングが必要になります。そのため、複数のデータモデル間でも動作するようにする必要がありますが、これは現時点では実現できていません。
次回SpotMap
次回、SpotMapは3月5日でAnalyst Studioについてです(今度こそAnalyst Studio!)。










