 運営会社
運営会社
ThoughtSpotのSpotIQ分析の「異常値」分析についてご紹介します
AkimasaKajitaniです。今回は、SpotIQ分析の「異常値」分析について試してみたいと思います。
SpotIQ分析の「異常値」分析とは?
SpotIQの「異常値」分析は、言い換えると外れ値を抽出する分析方法です。
基本的には、各値が基準値から決められた範囲外になると外れ値として検出されるというのが基本的な手法です。基準値の決め方や範囲の決め方がそれぞれのアルゴリズムで異なりますが、ThoughtSpotの「異常値」分析は、以下のアルゴリズムから選択可能です。
- 「中央Zスコア」もしくは「Zスコア」(デフォルトで実行される)
- 季節性ハイブリッドESD(時系列データ)
- 線形回帰(時系列データ)(デフォルトで実行される)
この中で、「中央Zスコア」と「Zスコア」は属性項目に対しての異常値発見用のアルゴリズムで、それ以外は時系列データに用いられます。
この異常値分析は、SpotIQ分析以外でも、KPIチャートやAIハイライトなど様々なところで利用されています。
「異常値」分析を行うためには?
SpitIQの異常値分析は、各属性のデータ型によって自動的に適切なアルゴリズムが使用されるようになっています。また、元のクエリ(検索トークン)に入っている属性項目の持つアイテムの組み合わせに対して異常値分析が行われるようになっているので、検索トークンの時点でそれを意識して検索トークンを作成してください。その上で、「列の選択」で選択した属性項目の各アイテムが外れ値になっているかどうか、というのが計算されるようになっています。
少し絵にすると、以下のように異常値分析が行われます。検索トークンから、セットした属性値でフィルタしたデータセットを作成し、それぞれのデータセットに対して、列の選択で指定した属性の項目に異常値が無いかどうかを調べる、という形になります。

それでは実際にやってみましょう。
まず、以下のように検索トークンを設定してみました。

この検索トークンの設定は非常に重要です。ここで設定した項目のアイテムごとに処理が行われます。
3点メニューからSpotIQ分析を選択します。
異常値を選択し、次へをクリックします。
次に、「列を選択」です。ここで指定した属性項目に対して異常値があるかどうかの判定が行われます。
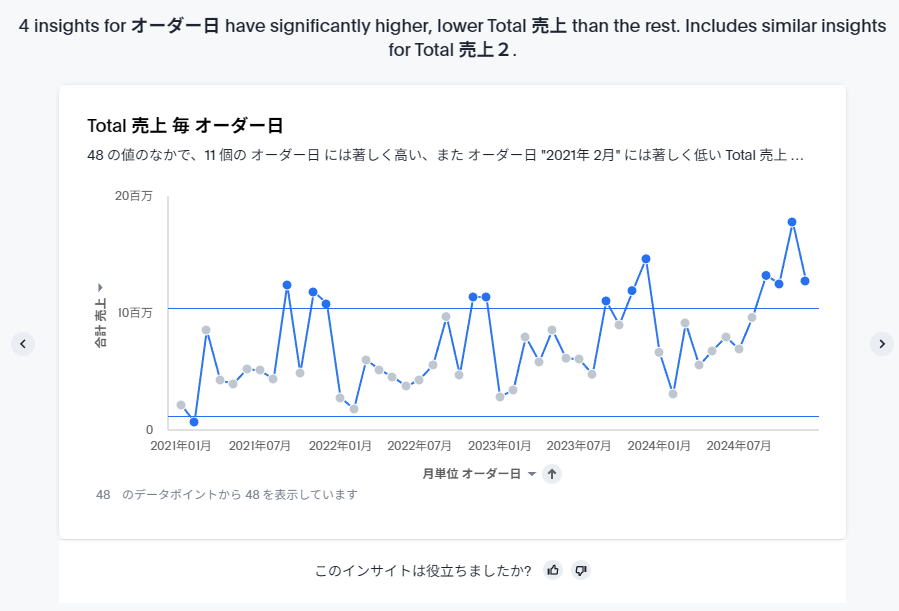
異常値分析は結果が多めに出るようになっています。まず、日時項目が入っている場合、線形回帰モデルによる異常値分析が行われます。
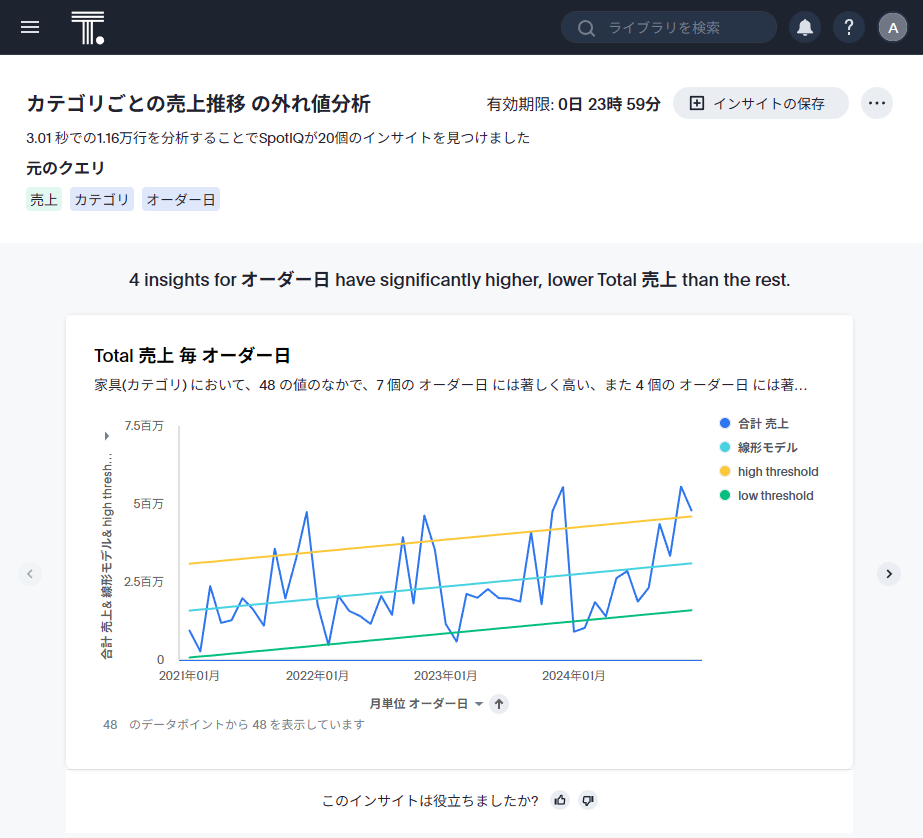
次のスクショでは、最初のクエリに入っていた「カテゴリ」ごとに異常値分析が行われていることがわかるかと思います(カテゴリの家具でフィルタされた結果がまず表示されています)。最初のグラフではカテゴリの家具にしぼった状態でオーダー日に見た時に異常値があるかどうか判定されています。以下のグラフでは黄色と緑の線よりはみ出した部分が異常値として判定されています。なお、右端の「>」ボタンが有効化されている場合、属性項目の他の値でフィルタした場合でも異常値が発見されたことを示しています。
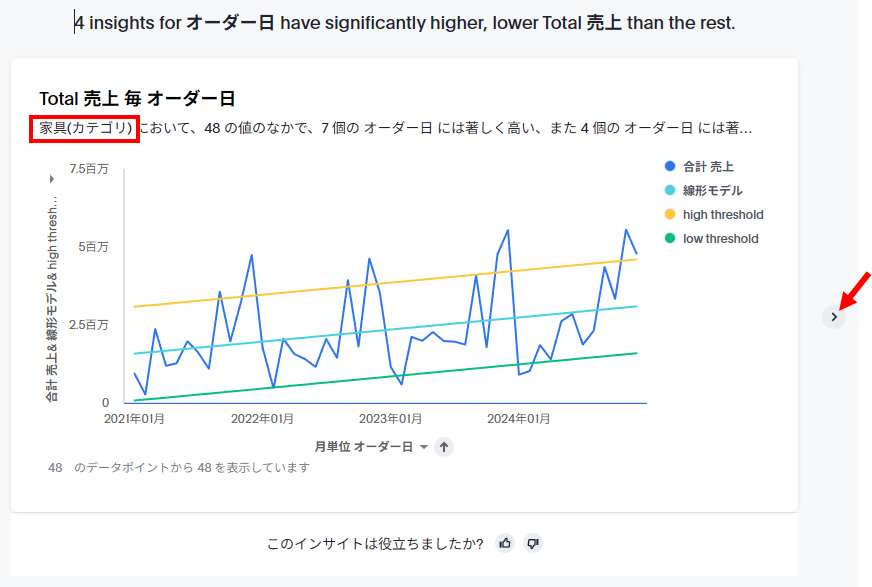
試しに「>」をクリックすると、カテゴリの「事務用品」で絞った状態になっています。
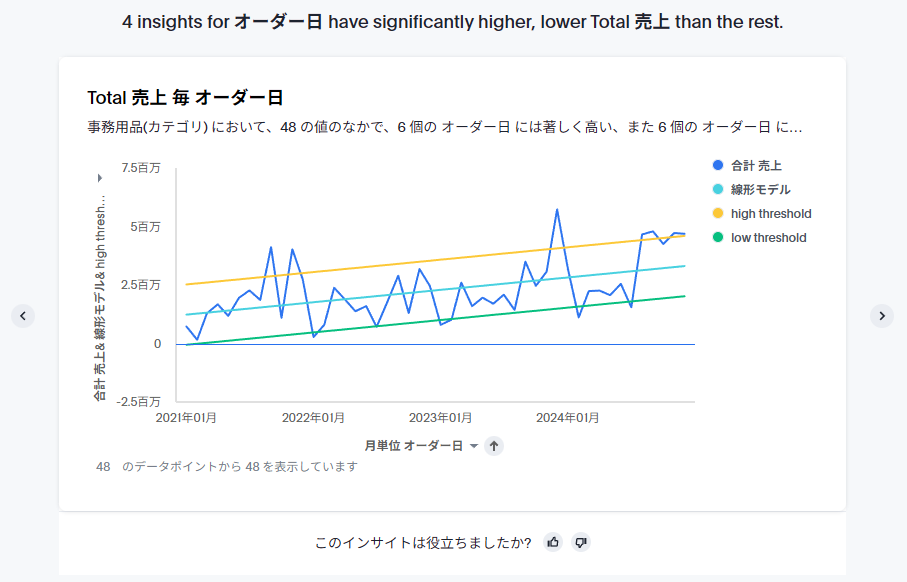
下にスクロールすると、今度は売上ではなく「列を選択」で選択した「利益」のインサイトが出てきました。
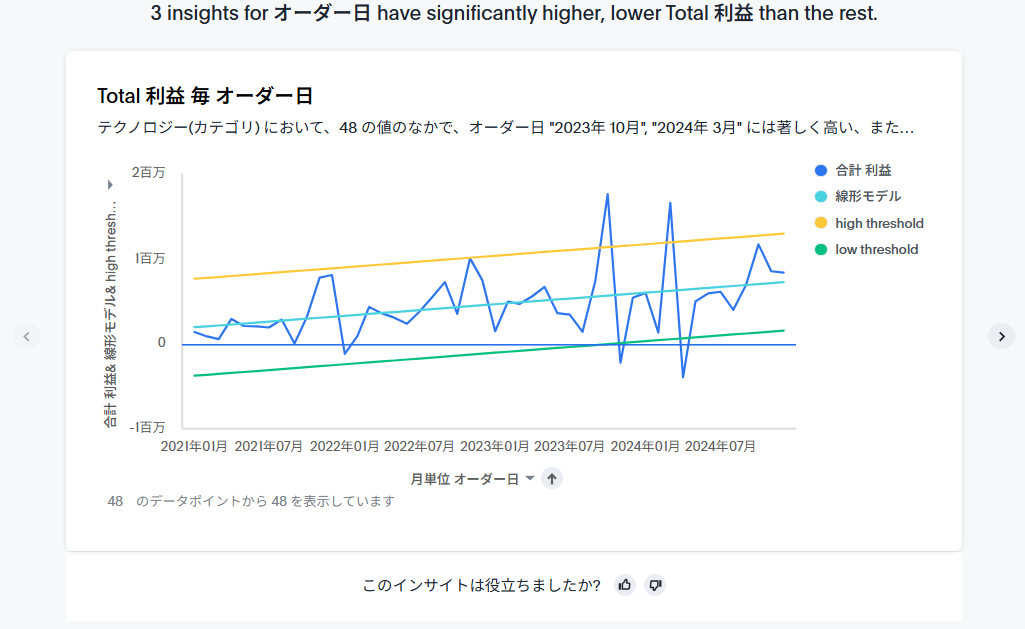
さらに下にスクロールすると、「列で選択」した都道府県に対してのインサイトが出てきました。これは「中央Zスコア」で検出した異常値です。
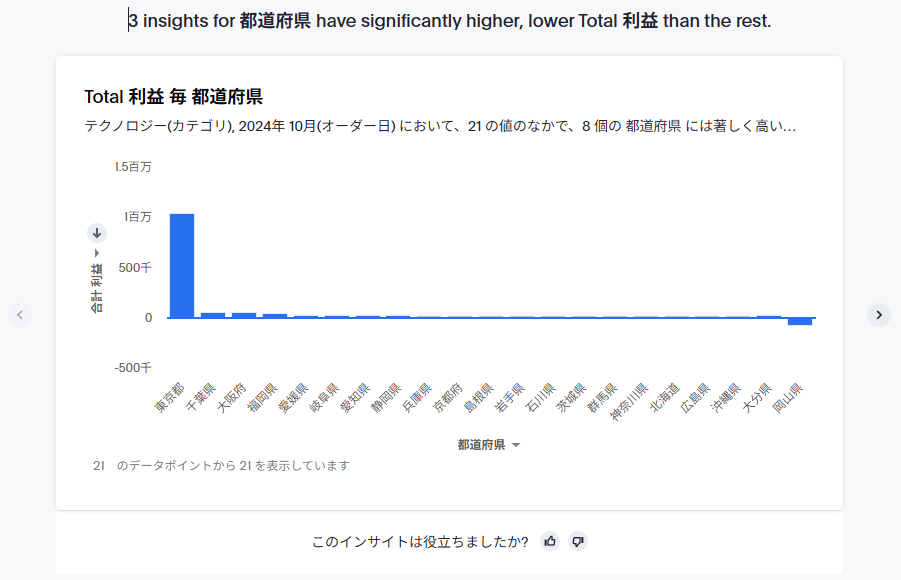
このような形で、元のクエリにある項目でフィルタリングし、集計されたデータセットごとに「列で選択」した項目でスライスしたものに異常値となるようなものがあるかどうか、というのを分析しています。
なお、時系列データに対しても、以下のように中央Zスコア/Zスコアで異常値検出が働きます。ただし、以下のように徐々に右上がりになっているような傾向を元データが持っている場合は、線形回帰の方がより異常値検知手法としては正しいかと思います。
ずっと定常的に繰り返すような時系列データだと、このような中央Zスコアでの異常値検知でも問題ないかと思います。
基本的に、時系列データの異常検知は、元データに周期性やトレンドがあったりするので、精度の高い異常検知は難しいと考えて間違いありません。元データに合わせた手法を取る必要があります。
パラメーターのカスタマイズについて
パラメータのカスタマイズ画面について見てみましょう。基本的に各機能共通のカスタマイズ設定と、各分析手法ごとの設定に分かれています。なお、この設定自体はワンショットの使い捨てになるのでご注意ください(ここで一度設定しても、再度SpotIQ分析を行う際、設定値はリセットされています)。
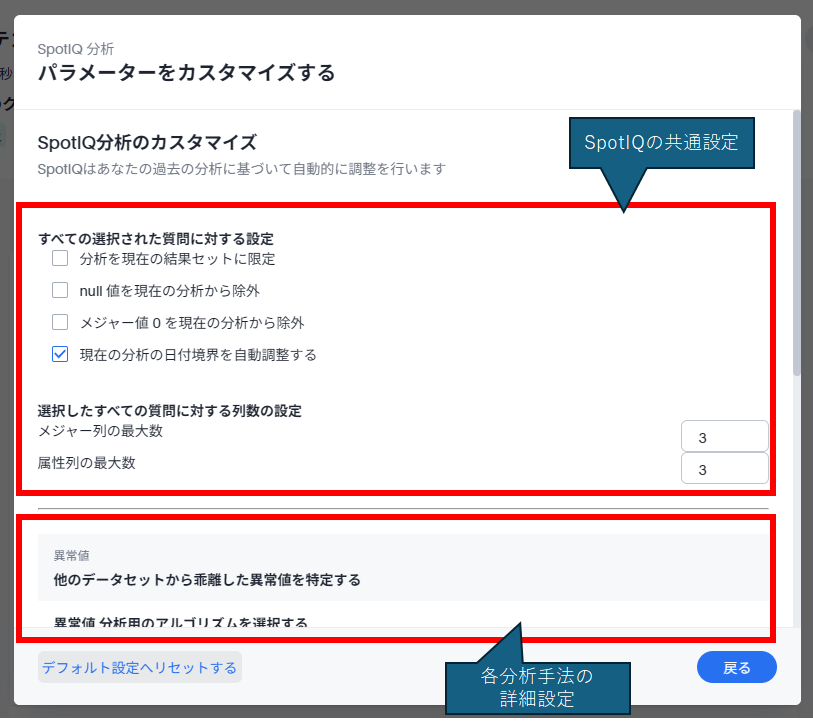
SpotIQの共通設定
SpotIQの共通設定は以下のとおりです。
- 分析を現在の結果セットに限定
- null値を現在の分析から除外
- メジャー値0を現在の分析から除外
- 現在の分析の日付境界を自動調整する
「分析を現在の結果セットに限定」は、元のクエリ(検索トークン)のみに絞って異常値分析を行います。そのため、「列を選択」で選択した項目は全て無視されます。
null値や0を除外するというのは、元データ内でnull値や0がどのような意味を持っているか、で設定を変更する必要があります。例えば、アイテムが存在しない場合にnullの代わりに0が入っているようなケースがあるかと思いますが、このような場合は分析対象から除外すべきでしょう。
その他、メジャー列の最大数、属性列の最大数はそれぞれ0~3の範囲で設定可能ですが、特に変更する必要はないと思われます(どちらかというともっと増やしたいかと思いますが、3が最大のようです)。
現在の分析の日付境界を自動調整するオプションは、ドキュメントでは以下の通り説明されています。
「日付境界の自動調整」がtrueに設定されている場合、クエリに日付時刻フィルターがない場合はThoughtSpotは最小日付と最大日付の両方を除外します。フィルターが含まれている場合はThoughtSpotはクエリに明示的に含まれている日付を含めつつ、極端な日付ポイントを削除します。
異常値分析の詳細設定
上のスクショは途中で途切れているので改めて異常値分析の詳細設定のスクショを掲載したいと思います。細かい値のカスタマイズについてはこちら に詳しく書かれています。
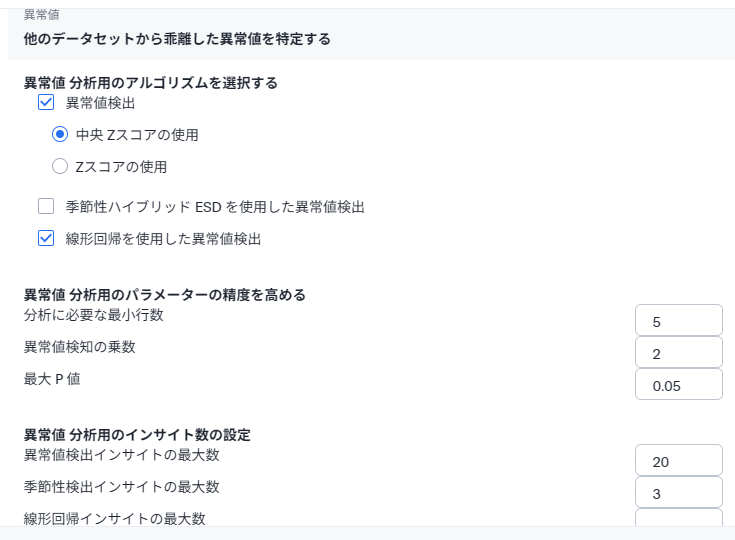
- 異常値分析用のアルゴリズムを選択する
- 異常値検出
- 中央Zスコアの使用
- Zスコアの使用
- 季節性ハイブリッドESDを使用した異常値検出
- 線形回帰を使用した異常値検出
- 異常値検出
- 異常値分析用のパラメータの精度を高める
- 分析に必要な最小行数
- 異常値検知の乗数
- 最大P値
- 異常値分析用のインサイト数の設定
- 異常値検出インサイトの最大数
- 季節性検出インサイトの最大数
- 線形回帰インサイトの最大数
異常値分析用のアルゴリズムは、デフォルトでは中央Zスコアと線形回帰となっています。異常値検出の2つのオプションは、属性項目の異常値の検出用で、季節性ハイブリッドESDと線形回帰は時系列モデルの異常値検出用です。一般的に、Zスコアより中央Zスコアの方が外れ値に左右されないので安定して利用できます(いわゆるロバスト(=堅牢性が高い)であるということです)。
時系列分析は、デフォルトの線形回帰の利用で良いと思います。もう一方の「季節性ハイブリッドESD」を選択すると実行に時間がかかり、私はうまく検出できたことがありません。Twitterのエンジニアが開発した手法 とのことですが、インターネットで検索しても実際に使っている人が少ないようです。Geminiさんが解説 してくれたので参考にして頂ければと思います。
次に、異常値分析用のパラメータの精度を高めるオプションです。
分析に必要な最小行数では、分析に必要な最小行数の設定が可能ですが、減らせばその分精度は落ちます。最低2ポイントは必要です(0にも設定ができますが・・・)。
異常値検知の乗数は、中央Zスコアで使用される乗数です。デフォルトは2ですが、以下の表に基づいて設定するのをおすすめします(基本的には以下のテーブルにしたがって自動的に動くと聞いています)。
| カーディナリティ | N(平均からの標準偏差の数) |
|---|---|
| <20 | 2 |
| <500 | 3 |
| <10000 | 4 |
| >=10000 | 5 |
最大P値は、線形回帰で使われています。基本的には統計的なしきい値として働きます。帰無仮説が真である確率、というのがこのパラメータの統計的な説明になりますが、より低い値にすると、それだけ正確性があがります。より大きい値にすると、より不確実なものもインサイトとして得られるようになります。なお、0.05(5%)というのは一般的に使われる値というだけです。
異常値分析用のインサイト数の設定は、それぞれの手法ごとに設定が可能です。異常値検知については、比較的に多めに出力されるようなデフォルト値になっていますが、多くのインサイトが得られる場合、必要に応じてこの値を大きくしてください。
その他できること
右上にあるメニューにて「インサイトの保存」もできますが、それ以外に以下のことが可能です。
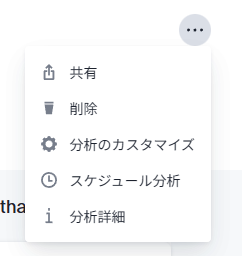
分析のカスタマイズは、どのようなオプションで分析を行ったのか確認できる機能です。
スケジュール分析は、定期的に同じオプションでSpotIQ分析を行う機能です。
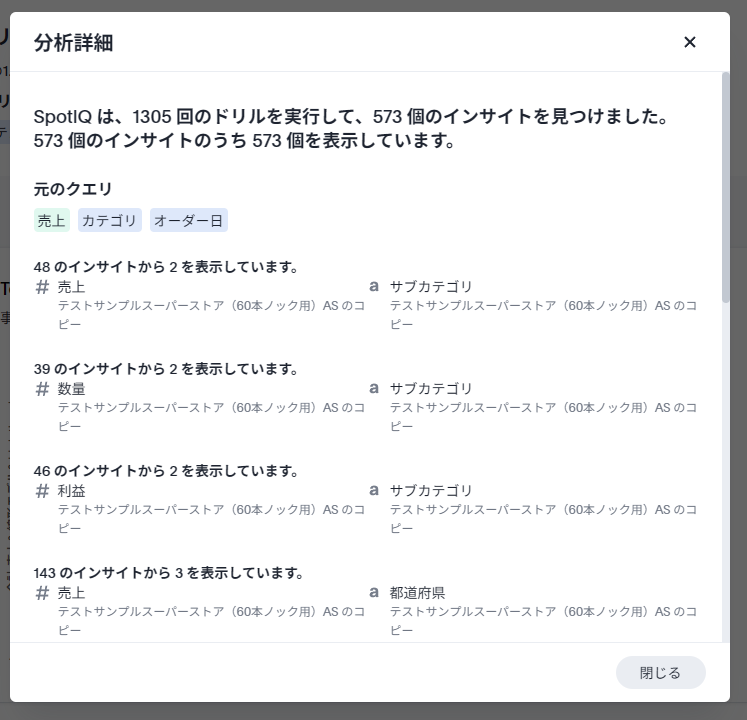
分析詳細は、分析を行った際にどのような組み合わせでインサイトを見つけたかを詳しく確認することができます。ここで大量のインサイトが発見されている場合、「パラメーターをカスタマイズする」にて出力される「インサイトの最大数」の値を大きくすることで、多くのインサイトに目を通すことが可能となります。
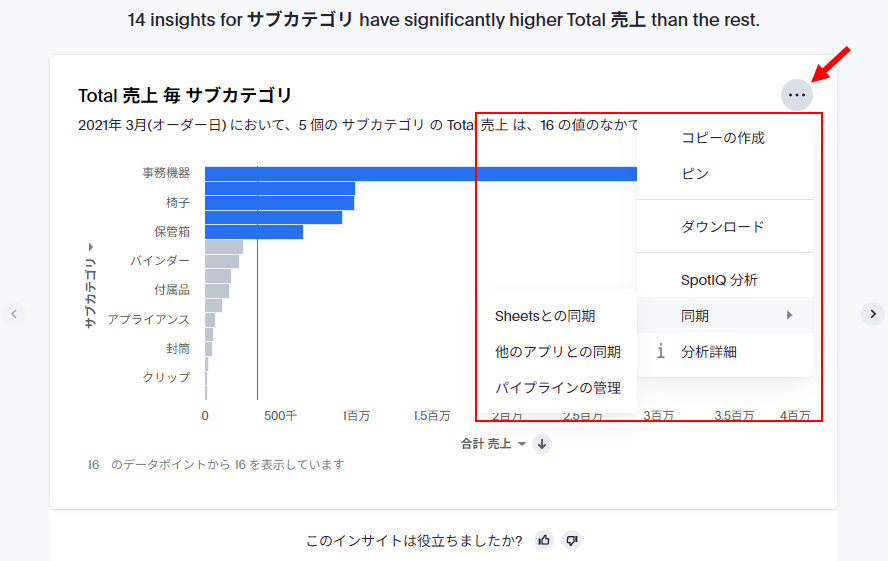
さらに、SpotIQで作成された各チャートはチャート内の3点メニューからライブボードへのピン留めやダウンロード、同期、分析の詳細の確認などができます。「コピーの作成」を行えば、チャートを自分でカスタマイズすることも可能です。
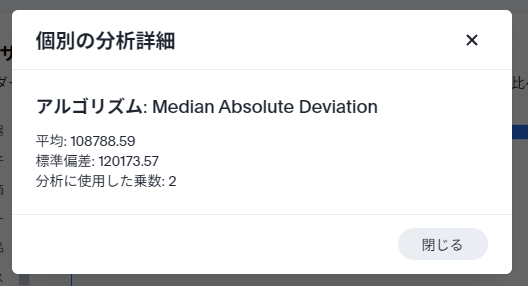
分析の詳細については、以下のようにどのアルゴリズムで作成されたのか、その時のパラメータを確認することができます。
制約事項とベストプラクティス
制約事項
- SpotIQ分析では、Group_Aggregation 系の関数は利用できません。
ベストプラクティス
- 異常値分析は、時系列データでも、それ以外でも使うことができます。元のクエリに日付項目を入れてしまうと、出てくる結果がいずれかの年月などにフィルタされたものが出てくるためご注意ください。年月のフィルタをかけたくない場合、最初のクエリに日付項目を入れず、「列の選択」で日付項目を指定してください。
- そのため、元のクエリ(検索トークン)がシンプルな方が扱いやすいと思います。「売上」だけで検索トークンを作成し、「列の追加」でスライスして異常値を検出したい属性項目を追加する、といった方法も効果的です。この時、特定の月のデータで絞りたい、ということであれば元のクエリにフィルタを加えてください
- 元のクエリの属性項目に追加すべきである項目は、各アイテムごとに異常検知を行いたい場合です。例えば「売上 製品名」などで作成すれば、製品ごとに異常検知が行われます。
参考URL
What are the spotIQ algorithms
SpotIQ analysis | ThoughtSpot documentation










